
自增id和uuid的优劣 为什么要用自增ID
为什么DBA总是强调要用自增id做主键?
这也是研发同学一直以来的疑问,一般DBA会说基于性能考虑。具体为什么,可能也没详细解释过。今天,简单明了地解释一下。
MySQL数据如何存储:
clustered index
The InnoDB term for a primary key index. InnoDB table storage is organized based on the values of the primary key columns, to speed up queries and sorts involving the primary key columns. For best performance, choose the primary key columns carefully based on the most performance-critical queries. Because modifying the columns of the clustered index is an expensive operation, choose primary columns that are rarely or never updated.
In the Oracle Database product, this type of table is known as an index-organized table.
首先,
官方手册中关于聚集索引有详细的说明
InnoDB表存储基于主键列的值进行组织
这类表又称之为索引组织表
总结一句话就是:MySQL的innodb表的数据是按照主键的顺序进行存储的。
其次,
MySQL数据库在磁盘上按数据页进行存储的,每个数据页的默认大小为16k
有序主键和无序主键的区别:
1. 有序主键(例如自增ID)
存储性能:
插入数据:由于自增ID的连续性,新记录总是插入到索引的最后位置,符合B+树的增长方式。无需在中间位置插入或移动数据,因此插入过程简单,性能较高。
数据页分裂:因数据是顺序插入的,页分裂发生频率低。只有在数据页完全填满时才会新开数据页,以支持新的连续数据,避免了大量的数据重排和移动。
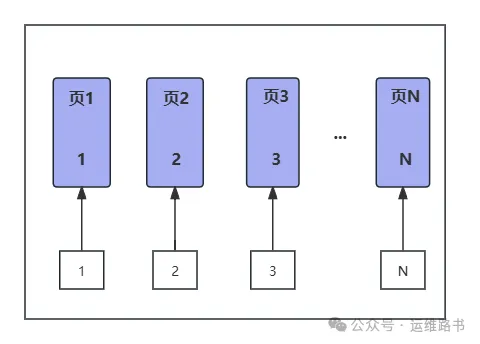
查询性能:
顺序插入的数据在物理上是连续存储的,因此基于主键的范围查询效率较高,减少了磁盘随机读写的次数。尤其是大范围查询时,数据连续分布在少数数据页中,可以减少IO操作。
2. 无序主键(例如UUID)
存储性能:
插入数据:UUID是随机生成的无序字符串,新插入数据无法确定插入位置,通常会插入到B+树的中间位置。每次插入都可能导致页分裂并重新组织索引,增加了数据重排的次数,导致存储开销更大。
数据页分裂:由于无序主键的随机性,数据插入分布不规律,页分裂频繁。当数据页满了时,系统会强制在中间位置插入新页,使得一部分记录被移动到新页。页分裂和数据移动会导致数据页利用率降低,影响插入性能。
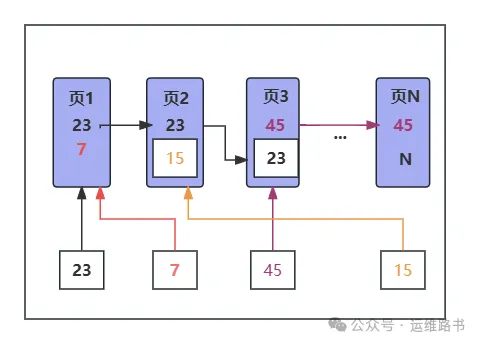
查询性能:
数据分布在更多的非连续数据页中,影响了范围查询的效率。每次查询需要在多个不相邻的数据页中获取数据,磁盘的随机读写增加,导致查询性能下降。
自增ID的优缺点
优点:
唯一性:每个记录的自增ID是唯一的,能够满足主键的唯一性要求。
顺序性:自增ID是连续递增的整数值,在插入时顺序排列,不会引起频繁的页分裂。
索引构建和维护成本低:因为自增ID按顺序增长,InnoDB在插入数据时无需频繁调整数据位置,索引维护成本较低,性能较高。
占用空间小:相比UUID等字符串类型的主键,自增ID通常是4字节或8字节整数,占用空间更少。
缺点:
存在业务数据泄露风险:连续的ID可能会让人推测出插入的总数量或增长规律,可能导致数据泄露风险。
跨库合并复杂:如果不同数据库或分片中使用相同自增ID策略,数据合并时容易产生冲突。
无法保证全局唯一:自增ID通常是数据库实例内部唯一,难以在分布式环境下保证全球唯一性。
UUID的优缺点
优点:
全局唯一性:UUID能够在分布式系统中保证唯一性,而无需依赖中心化的ID生成服务。
支持分布式环境:在分布式架构中,UUID特别适合用于跨数据库实例的记录合并,不会引起主键冲突。
数据迁移灵活性:数据迁移、跨系统整合等操作更简单,不需要重新生成主键或做ID映射。
避免信息泄露:UUID的随机性避免了可能会暴露插入的顺序或数量这一风险,增强了数据的安全性。
缺点:
插入性能低:UUID是无序的随机字符串,在B+树等结构中不能按顺序插入,导致频繁的页分裂,增加了数据库索引的维护开销,影响插入性能。
占用存储空间大:UUID通常为128位的字符串,存储时比自增整数(4字节或8字节)更占用空间。
查询性能差:因为UUID是无序的,基于UUID的范围查询性能低。UUID在数据页中分布分散,导致更多的磁盘随机读取,而不是连续读取,增加了IO负担。
排序和对比成本高:UUID长度较长,进行排序和比较的成本也较高,尤其在需要频繁排序的场景中,性能开销更大。
阅读性差:UUID是随机生成的长字符串,可读性差,不易辨识和调试,增加了手动操作或日志分析的难度。
解决方案
了解了两种方案的优缺点,接下来就是要取舍了,如何平衡各方?
研发已经开始撸代码了,时间紧任务重,本能上不愿意在这上面耗费时间重新修改。
基于安全性的原因
全局唯一的需求
最后决定采用 UUID v7
UUIDv7特点:
基于时间排序:
UUIDv7在设计上是时间顺序递增的,前42位编码了时间戳(以毫秒为单位)。在大多数场景下接近顺序增长,从而减少随机性带来的插入性能开销。
支持高并发环境:
除了时间戳部分,UUIDv7还包含了一定的随机位和节点ID位,以保证在同一毫秒内生成的UUID不重复。且无需中心化的ID生成服务。
较好的查询和存储性能:
因为UUIDv7有时间顺序特性,B+树结构的索引可以更高效地存储和查找UUIDv7,减少了数据页分裂的情况,提高了插入和范围查询性能。
长度和格式兼容:
UUIDv7仍然保持UUID 128位长度和标准格式(8-4-4-4-12),这使得它可以直接替换掉传统的UUID版本而无需调整存储字段格式。
以目前公司新项目为例,之前采用java的hutool工具生成uuid,同样支持uuidv7。只需要更换一个调用方法即可,代码修改量极小。
总结
| 特性 | 自增ID | UUIDv4 | UUIDv7 |
|---|---|---|---|
| 全局唯一性 | 无法保证 | 全局唯一 | 全局唯一 |
| 存储空间 | 较小(4-8字节) | 较大(16字节) | 较大(16字节) |
| 插入性能 | 高 | 较低(无序插入导致页分裂) | 较高(接近顺序插入) |
| 排序支持 | 支持顺序插入 查询高效 | 不支持,无序 | 支持,按时间顺序 |
| 可读性 | 较高 | 较低 | 较低 |
| 信息泄露 | 可能泄露插入顺序 | 隐藏插入顺序 | 基于时间顺序 部分暴露插入顺序 |
| 适用场景 | 单库系统 需要顺序性 | 分布式系统 只需唯一性 | 分布式系统需要顺序性和高插入性能 |
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 李苗苗
李苗苗
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675