
AI in WAF | 腾讯云网站管家 WAF AI 引擎实践
导语:互联网公司数据被窃取并在暗网兜售的事件屡见不鲜,已引起了人们对网络安全风险问题的热议,某些站点的 Shell 也直接被标价出售。黑客是利用哪些缺陷成功入侵并获取站点权限的?我们的网站防护真的安全吗?
 WAF (Web Application Firewall) 是网站安全防护体系里最常用也最有效的防御手段之一,被广泛应用于 Web 业务及网站的安全防护中。我们知道,安全防护是一个体系化工作,单独部署 WAF 并不一定能防止安全事件的发生。但是如果核心防护 WAF 存在缺陷,只要黑客有足够的耐心,就一定能找到渗透防护体系的突破点。
一旦发生了网站入侵事件,问题自然而然追溯到安全团队,常见的问题是部署的 WAF 为什么没检测到入侵? 这本质上是一个 WAF 被绕过的问题。实际上,传统 WAF 的威胁检测判定的防护方式在面对黑客复杂 Web 攻击及 0day 威胁频发的形势下,越发显得捉襟见肘,已经无法有效检测并拦截攻击。
WAF (Web Application Firewall) 是网站安全防护体系里最常用也最有效的防御手段之一,被广泛应用于 Web 业务及网站的安全防护中。我们知道,安全防护是一个体系化工作,单独部署 WAF 并不一定能防止安全事件的发生。但是如果核心防护 WAF 存在缺陷,只要黑客有足够的耐心,就一定能找到渗透防护体系的突破点。
一旦发生了网站入侵事件,问题自然而然追溯到安全团队,常见的问题是部署的 WAF 为什么没检测到入侵? 这本质上是一个 WAF 被绕过的问题。实际上,传统 WAF 的威胁检测判定的防护方式在面对黑客复杂 Web 攻击及 0day 威胁频发的形势下,越发显得捉襟见肘,已经无法有效检测并拦截攻击。

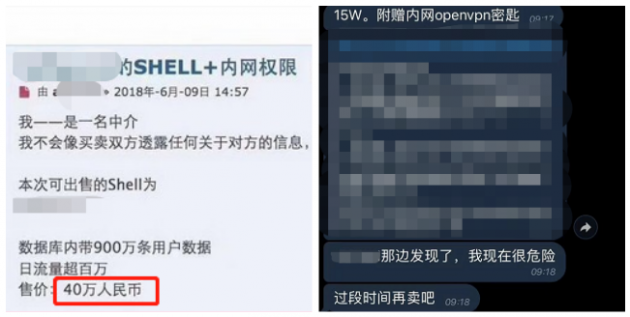
你的网站资料或许正在暗网兜售
△ 某社交软件与暗网上的资料兜售截图
(图片来自互联网)
上方图片可能很多人在前段时间见过,也有很多人闻风进群,只是售卖者可能出于自身隐私问题退群了,但这并没有让这条信息售卖之路彻底断掉,毕竟金钱的诱惑摆在那里,最常见的资料兜售链条是攻击者入侵窃取数据,通过勒索或转卖数据进行获利。在资本逐利的背景下,黑客攻击行动呈现出了极大的耐性和组织性,在攻击手法上,黑客也更多的开始使用多种手段,比如:复杂攻击、未知威胁以及 0day 漏洞利用等,以绕过用户现有的网站防护措施。攻防对抗不对等的情况愈发明显,频繁爆发的大型站点数据泄露及站点安全事件也逐渐变得不足为奇。
WAF (Web Application Firewall) 是网站安全防护体系里最常用也最有效的防御手段之一,被广泛应用于 Web 业务及网站的安全防护中。我们知道,安全防护是一个体系化工作,单独部署 WAF 并不一定能防止安全事件的发生。但是如果核心防护 WAF 存在缺陷,只要黑客有足够的耐心,就一定能找到渗透防护体系的突破点。
一旦发生了网站入侵事件,问题自然而然追溯到安全团队,常见的问题是部署的 WAF 为什么没检测到入侵? 这本质上是一个 WAF 被绕过的问题。实际上,传统 WAF 的威胁检测判定的防护方式在面对黑客复杂 Web 攻击及 0day 威胁频发的形势下,越发显得捉襟见肘,已经无法有效检测并拦截攻击。
亟需变革的 Web 攻击检测技术
要保障 WAF 有效拦截黑客入侵,关键在于 Web 攻击检测的有效性。当前 WAF 的主流检测手段有基于规则和基于语义规则两种:1、基于规则的 Web 攻击识别:
基于规则的 WAF,通过维护大量的已知攻击手法的特征规则,用特征规则匹配来检查目标流量中的攻击行为,这种方式简单有效,一直被沿用至今,随着攻击形势变化,目前突显出一些问题: 1)积累的规则难以有效应对 0day 攻击:规则基于已知的攻击特征维护,对未知攻击及 0day 攻击则难以有效应对; 2)僵化的规则难以应对灵活的黑客攻击手法:常见正则规则表达能力有限,黑客对攻击语句做编码、拼接等处理,可绕过防护; 3)难以平衡的误判与漏判问题:太严格的规则容易误杀正常业务流量,造成误判。太松散的规则则容易被绕过,造成漏判。 基于规则的 WAF 本身并不对程序语义进行理解,攻击者也可以利用文本和程序语言的表达差别,设计绕过措施。2、基于语义分析的 Web 攻击识别:
基于语义规则的原理是在理解程序本身语言规范基础上,通过匹配攻击特征检测 Web 攻击。其检测的前提是程序语言本身具备规则定义的语义规范,典型的应用是针对 SQL 数据库语言的 SQL 注入攻击,及针对 JS 语言的 XSS 攻击的攻击检测。基于语义规则的 WAF 大大提升了检出能力,是对规则检测缺陷的进一步探索,由于引擎具备对语义的理解能力,当黑客将攻击语句做回避式的变形时,能被语义分析引擎解析理解,行业中一些产品在实际应用中取得了比规则更好的检测能力。
△ 正则引擎与语义分析检测机制对比
用机器学习探索 Web 攻击检测新思路
基于语义分析的 WAF 将 Web 攻击检测技术推向了新的台阶,但防护仍然不具备对未知威胁的进化适应能力,处于被动应对攻击状态。如果能将“被动应对”变为“主动进化”,WAF 的防护能力可以进一步得到提升: 1)获取威胁自学习能力:基于规则 WAF的检测能力通过安全专家编写,检测能力局限在安全专家维护的规则能力上,不能通过获取的威胁样本和攻击手法自行学习和训练; 2)获取防护自进化能力:传统 WAF 在部分威胁响应上,只能采用人工添加黑白名单对 WAF 进行防护策略调整,而实际防护能力并未实际提升,缺乏防护自进化能力,本质上无法有效解决对未知威胁检测问题; 3)获取业务自适应能力:传统 WAF 对所有用户采用通用的威胁检测规则库,而实际上每个用户的业务逻辑各不相同,业务表现方式各异,容易造成误判影响业务,同时,通用的规则防护也难以帮助业务各异的用户有效防护业务风险。 如果能通过AI学习经验数据,形成行为模型,然后对目标事件做出判断和预测,将使产品具备自学习、自进化、自适应的特性。将机器学习应用到 WAF 攻击检测中,理论上可以进一步提升当前传统 WAF 的能力,帮助企业安全团队从被动防护的困局中突破出来。AI 应用于 Web 攻击检测需要解决的三个难题
相比其它领域,机器学习在 Web 攻击检测方向的落地应用发展明显滞后。这和 WAF 应用 AI 技术面临的诸多技术问题密切相关。 AI 技术小知识: 1)有监督学习:用已知某种或某些特性的样本作为训练集,建立一个判定模型,再用已建立的模型来预测未知样本,此种方法称为有监督学习。特点:提前采用大量已标记的样本训练 AI 引擎,召回率高,误判率低。 2)无监督学习:根据类别未知的样本解决模式识别中的各种问题,称之为无监督学习。特点:不需要提前标注样本训练 AI 引擎,通过大量数据学习自动实现分类,检出率高,漏判率低。基于有监督的 AI 识别模式的“漏判”问题:
通过 Web 攻击样本建立数据标签,再采用有监督学习模式做出威胁检测与预测。这种方式的弊端在于,行业内存在 Web 攻击样本稀少、样本量级不足,简单通过攻击样本标签进行有监督的 AI 学习,可能会带来 AI 检测的“漏判”;基于无监督的 AI 识别模式的“误判”问题:
基于“正常的载荷(流量)是类似的,异常有各自的异常”的原则,建立正常流量模型,不符合模型的流量都识别为恶意。然而“异常流量大部分并不是威胁”,将“异常流量”全部识别成攻击拦截是不可行的,会有大量的“误判”带来的误报;AI 检测处理时间带来的“延迟”问题:
机器学习需要相对较长的处理时间,如相对复杂的算法理论上可以实现更加精准的识别,但是由于AI 检测的处理延迟将会严重影响业务性能,这也是 AI WAF 落地在线 Web 攻击检测必须解决的难题。 正是由于这些需要突破的技术问题,将 AI 技术应用到 WAF 领域在很长一段时间里,仅停留再理论研究或部分浅层面应用尝试。AI 技术在 WAF 行业中的应用也引起了“为 AI 而 AI”、“AI WAF 仅仅是噱头”的正义。Gartner:严格评估 AI 带来的实际效益
Forrester:未见到真正的基于 AI 的 WAF
行业:每个 WAF 厂家都说自己有 AI
那么腾讯云网站管家 WAF 是如何实现技术突破?实际应用效果又如何呢?我们在下期一起探索 AI 引擎在 WAF 中的实际落地应用,并以 Demo 案例来展示腾讯云 “AI in WAF” 的创新成果,敬请关注。关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 腾讯云安全
腾讯云安全
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675