
使用Node.js抓取sebug漏洞目录
在10月份的时候为了准备一个竞赛,需要收集公开漏洞和EXP,而且比赛过程中不能连接外网。便尝试用Node.js对sebug漏洞库进行了整站抓取,成功”快照“了两万多个漏洞和exp。写一下大概过程和代码,希望对有类似需求的同学有所帮助。
主要利用了jQuery来进行HTTP下载和关键信息提取(需要操作DOM,可能效率不是很高)的工作。
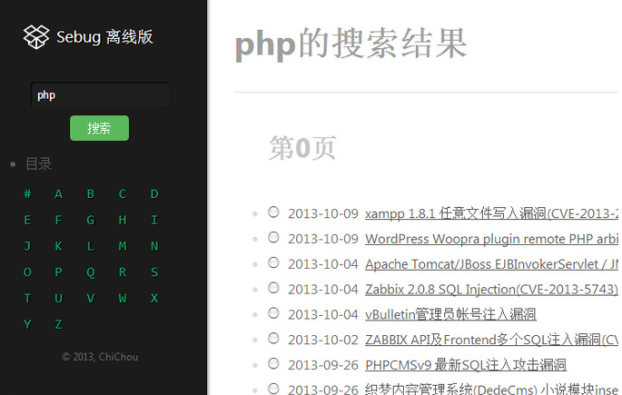 sebug有一个地址可以按顺序列出全部漏洞:http://sebug.net/vuldb/vulnerabilities?start=1
将start参数修改为具体的翻页即可遍历出所有的项目。之前还发现了一个小BUG,把start参数改成-1之类,会输出比较详细的错误信息,包括出错的源文件路径、具体的SQL查询语句,一下就暴露了表结构和后端的系统(web.py+MYSQL)。sebug似乎发现了这个问题,现在只是简单地输出一句HTTP 500。
接下来就是信息的提取了。跟浏览器前端完全一致的函数接口(querySelector等,甚至可以直接用jQuery)是我喜欢用Node.js抓取网页的原因,感觉就像是在自己的网页上写前端代码一样。比如我要提取出第1页中所有漏洞的链接,只需要使用CSS查询“.li_list > ul > li”即可。对网页正文的提取类似。
sebug在漏洞详情中夹带了广告,这是我不需要的。可以这样去掉:
sebug有一个地址可以按顺序列出全部漏洞:http://sebug.net/vuldb/vulnerabilities?start=1
将start参数修改为具体的翻页即可遍历出所有的项目。之前还发现了一个小BUG,把start参数改成-1之类,会输出比较详细的错误信息,包括出错的源文件路径、具体的SQL查询语句,一下就暴露了表结构和后端的系统(web.py+MYSQL)。sebug似乎发现了这个问题,现在只是简单地输出一句HTTP 500。
接下来就是信息的提取了。跟浏览器前端完全一致的函数接口(querySelector等,甚至可以直接用jQuery)是我喜欢用Node.js抓取网页的原因,感觉就像是在自己的网页上写前端代码一样。比如我要提取出第1页中所有漏洞的链接,只需要使用CSS查询“.li_list > ul > li”即可。对网页正文的提取类似。
sebug在漏洞详情中夹带了广告,这是我不需要的。可以这样去掉:
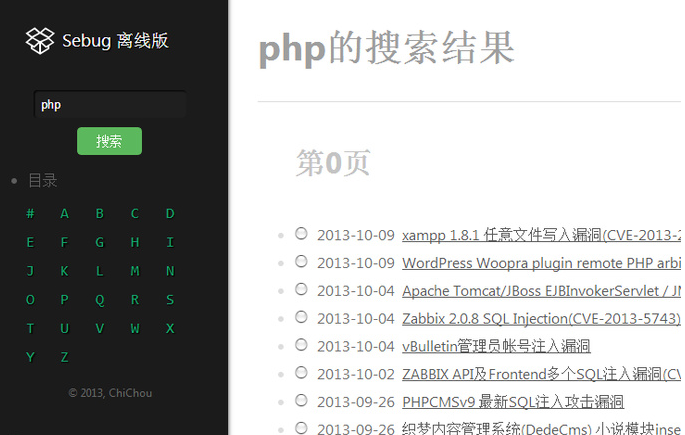 sebug有一个地址可以按顺序列出全部漏洞:http://sebug.net/vuldb/vulnerabilities?start=1
将start参数修改为具体的翻页即可遍历出所有的项目。之前还发现了一个小BUG,把start参数改成-1之类,会输出比较详细的错误信息,包括出错的源文件路径、具体的SQL查询语句,一下就暴露了表结构和后端的系统(web.py+MYSQL)。sebug似乎发现了这个问题,现在只是简单地输出一句HTTP 500。
接下来就是信息的提取了。跟浏览器前端完全一致的函数接口(querySelector等,甚至可以直接用jQuery)是我喜欢用Node.js抓取网页的原因,感觉就像是在自己的网页上写前端代码一样。比如我要提取出第1页中所有漏洞的链接,只需要使用CSS查询“.li_list > ul > li”即可。对网页正文的提取类似。
sebug在漏洞详情中夹带了广告,这是我不需要的。可以这样去掉:
sebug有一个地址可以按顺序列出全部漏洞:http://sebug.net/vuldb/vulnerabilities?start=1
将start参数修改为具体的翻页即可遍历出所有的项目。之前还发现了一个小BUG,把start参数改成-1之类,会输出比较详细的错误信息,包括出错的源文件路径、具体的SQL查询语句,一下就暴露了表结构和后端的系统(web.py+MYSQL)。sebug似乎发现了这个问题,现在只是简单地输出一句HTTP 500。
接下来就是信息的提取了。跟浏览器前端完全一致的函数接口(querySelector等,甚至可以直接用jQuery)是我喜欢用Node.js抓取网页的原因,感觉就像是在自己的网页上写前端代码一样。比如我要提取出第1页中所有漏洞的链接,只需要使用CSS查询“.li_list > ul > li”即可。对网页正文的提取类似。
sebug在漏洞详情中夹带了广告,这是我不需要的。可以这样去掉:
dom.find("#isad").remove();
sebug上很多漏洞并没有直接给出细节,而是贴上一个外链了事。对于需要离线环境使用的我来说,一个链接怎么够?还好遇到了神器PhamtomJS。它的强大功能不多做废话,这里我只需要用到一个特性,将指定URL的网页几乎原汁原味地渲染成PDF格式。
剩下的就是耐心等待了。sebug对频繁的访问会返回HTTP 503,只好在脚本中使用队列和setTimeOut解决,这就完全把以“非阻塞”为卖点的Node彻底弄残了。如果能搞到几个不同的公网IP再做简单的分配,抓取速度将会大为提高。
最后抓取的结果光是数据库就有近100M,而PDF格式的网页快照有111M,就不传gitHub了。
展示界面用express随便写了一个站,只写了index和404的模版,其余的全靠AJAX和动态修改DOM,所以界面这块并没有写多少代码。感觉真是非常的爽啊。
代码地址:https://github.com/ChiChou/offlineSebug
赶工做出来的代码比较潦草,可能以后有精力再重构了,请轻微吐槽。关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 冷鹰
冷鹰
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675