
「不良视频」如何消灭?她手把手教你走出第一步

不严肃的开场白
视频社交已经成为了时下最in的社交方式,相较于传统的文字、语音聊天,使用亲身录制的短视频、幽默搞笑的图片、表情包与好友进行交流,不仅更加风趣且更具人情味。 而随着视频社交的流行,每天产生的视频数据能够达到数千万小时,这些数据的质量参差不齐,其中有大量的不良视频,如涉暴、涉黄、涉政等。在海量数据面前,完全依靠人工审核无法解决内容审核的难题。因此也催生了智能内容审核的诞生。智能内容审核是指借助于人工智能技术,对海量视频进行自动分类,鉴别出其中涉及敏感内容的视频并予以禁播。
而随着视频社交的流行,每天产生的视频数据能够达到数千万小时,这些数据的质量参差不齐,其中有大量的不良视频,如涉暴、涉黄、涉政等。在海量数据面前,完全依靠人工审核无法解决内容审核的难题。因此也催生了智能内容审核的诞生。智能内容审核是指借助于人工智能技术,对海量视频进行自动分类,鉴别出其中涉及敏感内容的视频并予以禁播。
 智能内容审核的第一步,是进行视频分类。今天,我们要聊的就是视频分类背后的算法。
智能内容审核的第一步,是进行视频分类。今天,我们要聊的就是视频分类背后的算法。
严肃的开场白
故事要从深度学习说起。(因为从深度学习说起,可以显出本文是一篇有逼格的算法总结。)深度学习是一个近几年来火遍各个领域的词汇,在语音识别、图像分类、视频理解等领域,深度学习的相关算法在特定任务上已经能够达到甚至超过人类水平。本文从视频分类的角度,对深度学习在该方向上的算法进行总结。 视频分类是指给定一个视频片段,对其中包含的内容进行分类。类别通常是动作(如做蛋糕),场景(如海滩),物体(如桌子)等。其中又以视频动作分类最为热门,毕竟动作本身就包含“动”态的因素,不是“静“态的图像所能描述的,因此也是最体现视频分类功底的。数据集
熟悉深度学习的朋友们应该清楚,深度学习是一门数据驱动的技术,因此数据集对于算法的研究起着非常重要的作用。网络上虽然有大量用户上传的视频数据,但这些数据大多数缺少类目标签,直接用于算法的训练会导致效果欠佳。在学术界,通常有一些公开的、已经经过完整标注的数据集,是算法训练的好帮手。具体到视频分类领域,主要有两种数据集,trimmed和untrimmed。Trimmed是指视频经过剪辑,使其只包含待识别类别的内容;untrimmed是指视频未经过剪辑,包含了动作/场景/物体之外的很多信息。Untrimmed通常在视频分类的算法之外,还要加上动作检测算法。这不在今天的话题当中,有空我们可以再聊聊这一块的算法。 那么trimmed video的数据集比较常见的有UCF101,HMDB51,Kinetics,Moments in time。Untrimmed video的数据集比较常见的有ActivityNet,Charades,SLAC。部分数据集的比较见下表: 视频分类常用数据集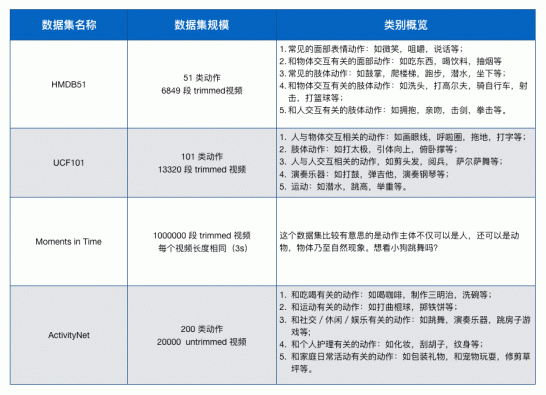 需要指出的是,从上表中我们可以看出视频分类的数据集实际上比图像分类的数据集的规模小得多。这是因为在视频上进行标注远比对图像进行标注要费时费力。trimmed视频还好些,基本标注时间等于视频时长。如果是untrimmed视频,需要在视频中手工标注动作的起始和结束时间,根据测试,需要花费视频长度的 4 倍时间。
因此ladies and 乡亲们,这些数据集,且用且珍惜吧。
需要指出的是,从上表中我们可以看出视频分类的数据集实际上比图像分类的数据集的规模小得多。这是因为在视频上进行标注远比对图像进行标注要费时费力。trimmed视频还好些,基本标注时间等于视频时长。如果是untrimmed视频,需要在视频中手工标注动作的起始和结束时间,根据测试,需要花费视频长度的 4 倍时间。
因此ladies and 乡亲们,这些数据集,且用且珍惜吧。
研究进展
在视频分类中,有两种非常重要的特征:表观特征(appearance)和时序特征(dynamics)。一个视频分类系统的性能很大程度上取决于它是否提取并利用好了这两种特征。但是提取这两种特征并不那么容易,会遇到诸如形变/视角转换/运动模糊等因素的影响。因此,设计对噪声鲁棒性强且能保留视频类别信息的有效特征至关重要。 根据ConvNets(深度卷积神经网络)在图像分类上取得的成功,很自然地,我们会想到把ConvNets用到视频分类中。但是,ConvNets本身是对二维图像的表观特征的建模,而对于视频来说,除了表观特征,时序特征也很重要。那么如果把时序特征用起来呢?通常有三种思路:LSTM,3D-ConvNet和Two-Stream。
1. LSTM系列
LRCNs[1]是LSTM和ConvNet结合进行视频分类的方法。这种结合很自然,已经在图像分类任务上训练好的ConvNet分类器,可以很好地提取视频帧的表观特征;而对于时序特征的提取,则可以通过直接增加LSTM层来实现,因为LSTM能够将多个时刻的状态作为当前时刻的输入,从而允许时间维度上的信息得以保留。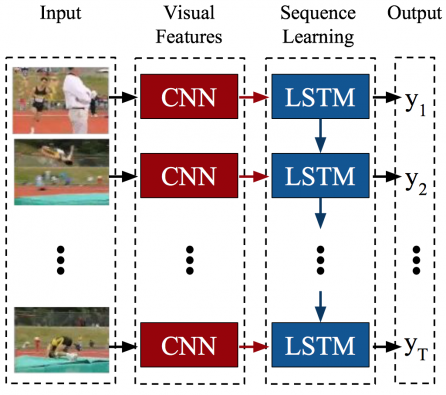 视频分类任务是变长输入定长输出的。文章另外还介绍了LRCNs用于图像描述(定长输入变长输出)和视频描述(变长输入变长输出)的方案,感兴趣的同学可以自行查看。
视频分类任务是变长输入定长输出的。文章另外还介绍了LRCNs用于图像描述(定长输入变长输出)和视频描述(变长输入变长输出)的方案,感兴趣的同学可以自行查看。
2. 3D-ConvNet及其衍生系列
C3D[2]是Facebook的一个工作,它主要是把2D Convolution扩展到3D。其原理如下图,我们知道2D的卷积操作是将卷积核在输入图像或特征图(feature map)上进行滑窗,得到下一层的特征图。例如,图(a)是在一个单通道的图像上做卷积,图(b)是在一个多通道的图像上做卷积(这里的多通道图像可以指同一张图片的3个颜色通道,也指多张堆叠在一起的帧,即一小段视频),最终的输出都是一张二维的特征图,也就是说,多通道的信息被完全压缩了。而在3D卷积中,为了保留时序的信息,对卷积核进行了调整,增加了一维时域深度。如图(c)所示,3D卷积的输出仍是一个三维的特征图。因此通过3D卷积,C3D可以直接处理视频,同时利用表观特征和时序特征。 关于实验效果,C3D在UCF101上的精度为82.3%,并不高,其原因在于C3D的网络结果是自己设计的简单结构(只有11层),而没有借鉴或预训练于其他成熟的ConvNets结构。
因此针对这一点,有很多学者提出了改进。
- I3D[3] 是 DeepMind 基于 C3D 作出的改进,值得一提的是 I3D 这篇文章也是发布 Kinetics数据集的文章。其创新点在于模型的权重初始化,如何将预训练好的2D ConvNets的权重赋值给3D ConvNets。具体地,将一张图像在时间维度上重复T次可以看作是一个(非常无聊的)T帧的视频,那么为了使该视频在3D结构上的输出和单帧图像在2D结构的输出相等,可以使3D卷积的权重等于2D卷积的权重重复T次,再将权重缩小T倍以保证输出一致。I3D在Kinetics数据集上进行预训练然后用于UCF101,其精度可达到98.0%。
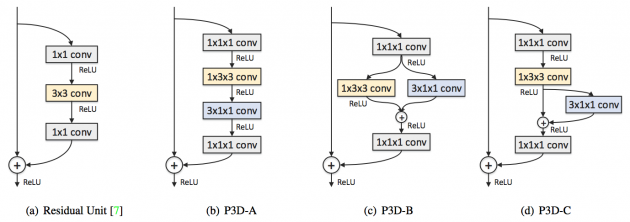
- P3D[4]是MSRA基于C3D作出的改进,基本结构是把ResNet扩展为“伪”3D卷积,“伪”3D卷积的意思是利用一个1*3*3的2D空间卷积和3*1*1的1D时域卷积来模拟常用的3*3*3的3D卷积,如下图所示。P3D在参数数量、运行速度等方面对C3D作出了优化。
关于实验效果,C3D在UCF101上的精度为82.3%,并不高,其原因在于C3D的网络结果是自己设计的简单结构(只有11层),而没有借鉴或预训练于其他成熟的ConvNets结构。
因此针对这一点,有很多学者提出了改进。
- I3D[3] 是 DeepMind 基于 C3D 作出的改进,值得一提的是 I3D 这篇文章也是发布 Kinetics数据集的文章。其创新点在于模型的权重初始化,如何将预训练好的2D ConvNets的权重赋值给3D ConvNets。具体地,将一张图像在时间维度上重复T次可以看作是一个(非常无聊的)T帧的视频,那么为了使该视频在3D结构上的输出和单帧图像在2D结构的输出相等,可以使3D卷积的权重等于2D卷积的权重重复T次,再将权重缩小T倍以保证输出一致。I3D在Kinetics数据集上进行预训练然后用于UCF101,其精度可达到98.0%。
- P3D[4]是MSRA基于C3D作出的改进,基本结构是把ResNet扩展为“伪”3D卷积,“伪”3D卷积的意思是利用一个1*3*3的2D空间卷积和3*1*1的1D时域卷积来模拟常用的3*3*3的3D卷积,如下图所示。P3D在参数数量、运行速度等方面对C3D作出了优化。
3. Two-Stream Network及其衍生系列
Two Stream[5]是VGG组的工作(不是UGG哦),其基本原理是训练两个ConvNets,分别对视频帧图像(spatial)和密集光流(temporal)进行建模,两个网络的结构是一样的,都是2D ConvNets,见下图。两个stream的网络分别对视频的类别进行判断,得到class score,然后进行分数的融合,得到最终的分类结果。 可以看出Two-Stream和C3D是不同的思路,它所用的ConvNets都是2D ConvNets,对时序特征的建模体现在两个分支网络的其中一支上。Two-Stream的实验结果,在UCF101上达到88.0%的准确率。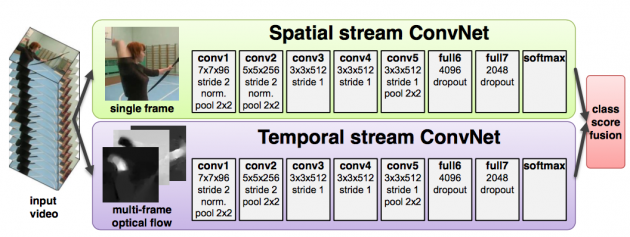 在spatial stream和temporal stream如何融合的问题上,有很多学者作出了改进。
- [6]在two stream network的基础上,利用3D Conv和3D Pooling进行spatial和temporal的融合,有点two stream + C3D的意思。另外,文章将两个分支的网络结构都换成了VGG-16。在UCF101的精度为92.5%。
- TSN[7]是CUHK的工作,对进一步提高two stream network的性能进行了详尽的讨论。two stream在这里被用在视频片段(snippets)的分类上。关于two stream的输入数据类型,除去原有的视频帧图像和密集光流这两种输入外,文章发现加入warped optical flow也能对性能有所提高。在分支网络结构上尝试了GoogLeNet,VGG-16及BN-Inception三种网络结构,其中BN-Inception的效果最好。在训练策略上采用了跨模态预训练,正则化,数据增强等方法。在UCF101上达到94.2%的精度。
在spatial stream和temporal stream如何融合的问题上,有很多学者作出了改进。
- [6]在two stream network的基础上,利用3D Conv和3D Pooling进行spatial和temporal的融合,有点two stream + C3D的意思。另外,文章将两个分支的网络结构都换成了VGG-16。在UCF101的精度为92.5%。
- TSN[7]是CUHK的工作,对进一步提高two stream network的性能进行了详尽的讨论。two stream在这里被用在视频片段(snippets)的分类上。关于two stream的输入数据类型,除去原有的视频帧图像和密集光流这两种输入外,文章发现加入warped optical flow也能对性能有所提高。在分支网络结构上尝试了GoogLeNet,VGG-16及BN-Inception三种网络结构,其中BN-Inception的效果最好。在训练策略上采用了跨模态预训练,正则化,数据增强等方法。在UCF101上达到94.2%的精度。

4. 其他
除了以上两种常见的思路以外,也有学者另辟蹊径,尝试与众不同的方法。 - TDD[8]是对传统的iDT[9]算法的改进(iDT算法是深度学习以前最好的行为识别算法),它将轨迹特征和two-stream network结合使用,以two-stream network作为特征提取器,同时利用轨迹对特征进行选择,获得轨迹的深度卷积描述符,最后使用线性SVM进行视频分类。TDD是一个比较成功的传统方法与深度学习算法相结合的例子,在UCF上达到90.3%的精度。 - ActionVLAD[10]是一种特征融合的方式,它可以融合two stream的特征,C3D的特征以及其他网络结构的特征。其思想是对原有的特征计算残差并聚类,对不同时刻的帧进行融合,得到新的特征。ActionVLAD是对视频空间维度和时间维度的特征融合,使得特征的表达更全面。 - Non-local Network[11]是Facebook何恺明和RBG两位大神近期的工作,非局部操作(non-local operations)为解决视频处理中时空域的长距离依赖打开了新的方向。我们知道,卷积结构只能捕捉数据的局部信息,它对于非局部特征的信息传递不够灵活。Non-local Network则根据所有帧所有位置的信息对某个位置进行调整。文章把这个block加在I3D上做了实验,在Charades上精度提升2%。总结
以上所有的视频分类算法都是在近几年提出的,可以看出这一领域的发展之快。从学术角度,视频分类是开启视频理解这个领域的金钥匙,对它的研究可以为相关领域的研究打下坚实的基础,包括视频动作检测,视频结构化分析等,都用到了视频分类的技术。从我们实际生活的角度,视频分类已经在默默地做着很多事情,例如在文章一开始提到的智能内容审核,再例如视频检索、视频监控、视频广告投放、自动驾驶、体育赛事分析等。在不久的将来,相信视频分类以及其他的AI算法将为我们带来更多惊喜的变革。AI让生活更美好。牛人说
牛人说专栏致力于技术人思想的发现,其中包括技术实践、技术干货、技术见解、成长心得,还有一切值得被发现的技术内容。我们希望集合最优秀的技术人,挖掘独到、犀利、具有时代感的声音。参考文献
[1] J. Donahue, et al. Long-term recurrent convolutional networks for visual recognition and description. CVPR, 2015. [2] D. Tran, et al. Learning Spatiotemporal Features with 3D Convolutional Networks. ICCV, 2015. [3] J. Carreira, et al. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. CVPR, 2017. [4] Z. Qiu, et al. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. ICCV, 2017. [5] K. Simonyan, et al. Two-Stream Convolutional Networks for Action Recognition in Videos. NIPS, 2014. [6] C. Feichtenhofer, et al. Convolutional Two-Stream Network Fusion for Video Action Recognition. CVPR, 2016. [7] L. Wang, et al. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. ECCV, 2016. [8] L. Wang, et al. Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors. CVPR, 2015. [9] H. Wang, et al. Action Recognition with Improved Trajectories. ICCV, 2013. [10] R. Girdhar, et al. ActionVLAD: Learning spatio-temporal aggregation for action classification. CVPR, 2017. [11] X. Wang, et al. Non-local Neural Networks. arxiv 1711, 2017.关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/


![藤原熊二 没有第九张[偷笑]2深圳·公明 ](https://imgs.knowsafe.com:8087/img/aideep/2021/12/22/b4d1aeee6b429ed3ba754ae108f04c85.jpg?w=250)



 七牛云
七牛云
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675