
谷歌语言处理框架SyntaxNet新升级,识别率提高25%
最近,谷歌发布语言处理框架SyntaxNet升级版,识别率提高25%,Google在其research平台对其作了介绍,全文如下:
在谷歌,从生成电子邮件的自动回复到语言机器翻译,我们一直持续不断地努力提高这类应用程序的语言理解能力。其中SyntaxNet是一个用于分析和理解句子语法结构的神经网络架构,去年夏天我们将其开源。这其中包括了一个目前最尖端的,我们已训练完成用以分析英语的模型(Parsey McParseface)和随后收集的一组能够处理其它40种语言的模型,我们将它们称之为“ Parsey's Cousins”。虽然我们很高兴地分享这些研究成果并提供这些资源,然而与此同时,建立一个能够很好处理除英语以外的其它各种语言的机器学习系统仍然是一个持续的挑战。为了迎接这一挑战,我们很激动地宣布有一些新的研究资源现在即可访问。
SyntaxNet升级
我们正在对SyntaxNet进行主要的升级更新。这次升级将纳入我们近一年对多语言理解的研究。任何只要对建立处理和理解文本系统有兴趣的个人或团体均可获得这次升级。这次升级的核心是增加了一项可对具有丰富层次表述的句子进行学习的新功能。具体来说,这次升级扩展了TensorFlow 的适用范围,使其能接受语言结构多层次的联合建模,并且允许在处理句子或文本时,动态创造相应的神经网络结构。
举例来说,这次升级使得建立基于字符模型(character-based models)变得容易,基于字符模型会学习把单独的字符组成单词,就如同‘c-a-t’组成‘cat’。这种模型可以学习到有些单词之间是相关的,因为它们有时会共享相同的部分(例如,‘cats’是‘cat’的复数形式并且共享相同的词干;‘wildcat’是‘cat’的一种类型)。在另一方面,Parsey和Parsey’s Cousins的运作是基于单词的序列。这样的结果就是,它们被迫去记住在训练阶段见过的所有单词,以及大多依赖于上下文去决定那些在之前训练阶段未见过的单词的语法功能
以接下来的一句话(无实际意义但语法正确)为例:
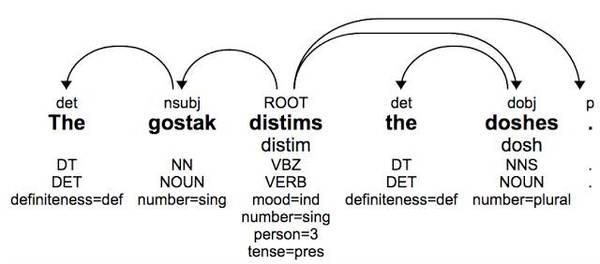
这句话最初是由Andrew Ingraham创造,他曾解释过:“你不了解它(这句话)的意思;我同样也不知道。但如果我们假设这是英文,那我们可知doshes 是被gostak distim掉了。我们也知道doshes 是由gostak进行distim的。”构词法和句法系统性模式允许我们去猜测某个单词的语法功能,哪怕这个单词是肆意编造的:‘doshes’是名词‘dosh’的复数形式(和上文‘cats’的例子类似),‘distims’是‘distim’的第三人称单数形式。基于此分析,我们可以推断出这个句子的整体结构即使这些单词不曾见过。
ParseySaurus
为了展示这次对SyntaxNet升级带来的新功能,我们发布了一组全新的预训练模型ParseySaurus。这组模型采用之前提到的基于字符的输入表达,因此,对那些基于拼写和在上下文中怎样使用的新单词有着更好的预测能力。
ParseySaurus模型拥有比 Parsey’s Cousins更高的准确率(降低了近25%的错误率),尤其对那些词法丰富的语言,如俄语,或是拥有大量胶着语的土耳其语和匈牙利语。这些语言里每个单词可以拥有许多形式,而即使在一个很庞大的语料库中,这其中多数形式是不会在训练阶段看见的。
考虑下面一个虚构的俄语句子。同样的,句子里单词的词干毫无意义但是它们的后缀可以清楚地表示这个句子的结构。
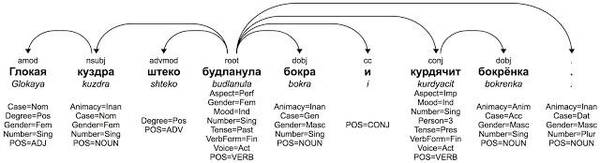
即使我们的ParseySaurus俄语模型从未见过这些单词,它仍可以通过检查组成每个单词的字符序列,正确地分析这个句子。这个模型系统可以确定出单词的许多特性(请注意这里有比上文英语例子中更多的词法特征)。下图显示了ParseySaurus模型怎样去分析这句话:
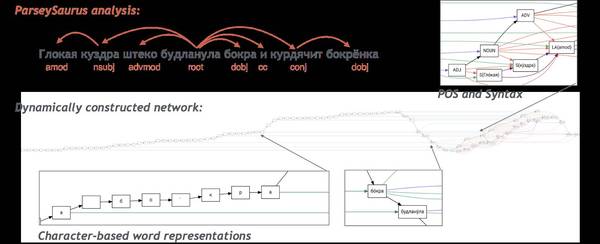
每个正方形表示一个神经网络中的节点,直线表示它们之间的连接。这幅图左侧的“尾巴”表明这个模型将输入当作一串很长的字符串进行接收。它们被间隔地传到右侧。右侧丰富地网络连接显示出这个模型将单词组成短语,产生出句法解析。在这里可查看全尺寸大图。
一项比赛
你也许想知道是否基于字符建模就是最终我们所需的方法,还是这里依然还有其它可能很重要的技术。事实上SyntaxNet还可以提供更多,例如集束搜索( beam search)和不同的训练目标,当然这里还有许多其他的可能。为了找寻在实际运用中最有效的方法,我们正与其他相关机构共同筹办一个多语言解析比赛,它将在今年的计算自然语言学习会议(CoNLL)上进行。这项比赛的目标是构建一个可以在现实世界环境中,针对45种不同语言可以良好运行的句法解析系统。
这项比赛是通过Universal Dependencies (UD)提出倡议而实现的,其目标是开发跨语言一致的树库。由于机器学习到的模型只能与它们访问到数据一样好,因此我们自2013年以来一直在为UD提供数据。对于这项比赛,我们与UD和DFKI合作建立一个全新的多语言评估集,这里面包含1000个已被翻译成20多种不同语言的句子,并由语言学家用解析树(parse trees)进行注释。这个评估集是第一次被提出(在过去,每种语言都有自己独立的评估集),并将实现更一致的跨语言比较。因为句子具有相同的含义并且已经根据相同的准则被注释,我们将能够更进一步地回答哪种语言可能更难解析的问题。
我们希望升级版的SyntaxNet框架和预训练的ParseySaurus模型将激励研究人员参与到比赛中来。我们还创建了一个教程,介绍如何在Google云端平台上加载 Docker图像及训练模型,以方便只有有限资源的小团体参与。所以,如果你有一个想用SyntaxNet框架训练一个自己的模型,那就快点注册报名吧!我们相信我们现在发布的开源项目是一个好起点,与此同时我们同样期待参与者将如何扩展和改进这些模型,甚至创造出更好的模型!
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
![是王足各:月更博主上线[感冒]](https://imgs.knowsafe.com:8087/img/aideep/2021/7/18/e01887d5b28556f4c23cc9347028fc4b.jpg?w=250)





 程序猿
程序猿
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675