
北大发现了一种特殊类型的注意力头!
 夕小瑶科技说 原创
夕小瑶科技说 原创
作者 | 任同学
检索头的发现或许将有力地帮助大模型领域在提高长上下文推理能力、减少幻觉和压缩KV缓存方面的研究。
从 Claude100K 到 Gemini10M,我们正处于长上下文语言模型的时代。如何在长上下文中利用任何输入位置的信息?北大联合另外四所高校发现了一种特殊类型的、负责从长上下文中进行检索的注意力头。

研究人员对4个模型族、6个模型尺度和3种微调类型的系统调查表明,存在一种特殊类型的注意力头(称之为检索头),它主要负责从长上下文中检索相关信息。
研究人员发现了检索头具有一些重要和有趣的性质:
通用性:所有具有长上下文能力的探索模型都有一组检索头; 稀疏性:只有一小部分(小于5%)的注意头是检索头; 内在性:检索头在短上下文预训练的模型中已经存在。当将上下文长度扩展到32-128K时,仍然是同一组注意力头执行信息检索; 动态激活:以 Llama-27B 为例,无论上下文如何变化,12个检索头始终关注所需信息。其余的检索头在不同的环境中被激活; 因果关系:完全修剪检索头导致检索相关信息失败,产生幻觉,而修剪随机的非检索头不影响模型的检索能力。
由于检索头用于从长上下文中检索信息,因此不难推测,检索头强烈影响思维链(CoT)推理,因为模型需要经常引用问题和先前生成的上下文。
相反,模型使用其固有知识直接生成答案的任务受屏蔽检索头的影响较小。这些观察结果共同解释了模型的哪个内部成分会在输入 token 中寻找信息。
通用且稀疏的检索头
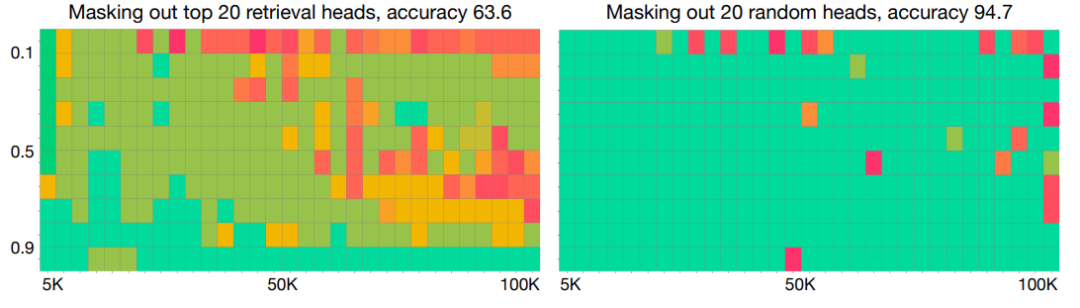
研究人员表示,在研究的所有语言模型中,无论是Base还是Chat版本,上下文长度如何,小模型还是大模型,密集或是MoE——只要它们在大海捞针基准中通过,它们就有一小组检索头。
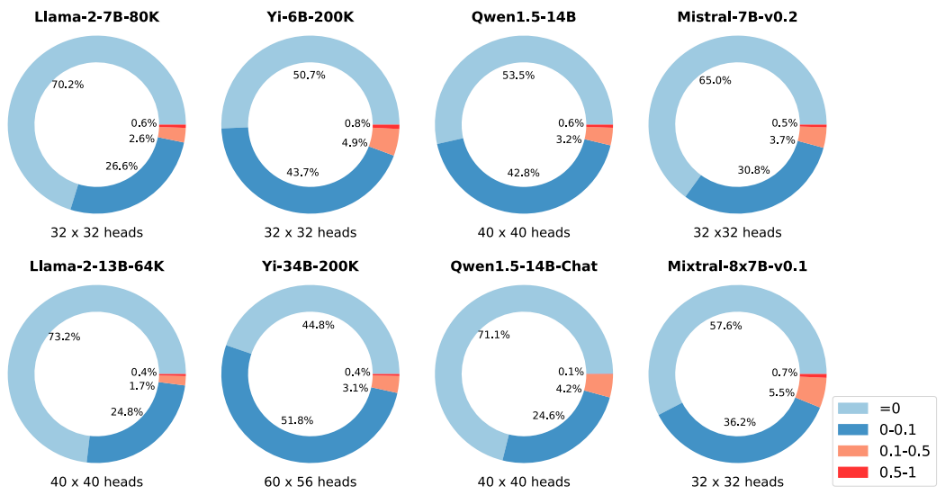
上下文长度的拓展不影响检索头的位置
研究人员提出,检索头是一种已经位于基础模型中的、固有的特性,是预训练的结果,并且最关键的是,如将上下文从 4K 扩展到 100K,或将其微调为聊天,或升级到 MoE 专家模型,它仍然是激活的同一组检索头。

这个性质在同一个模型家族中也能体现出来,同一族模型的检索头是强相关的,即聊天模型和基础模型通常使用同一组检索头,而不同家族模型的检索头明显不同!
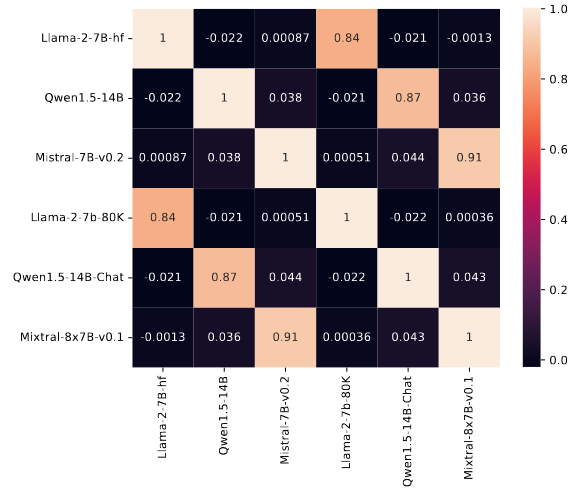
如何用检索头来解释模型幻觉?
研究人员使用检索头的理论解释了模型产生幻觉的原因,即当模型错过了部分信息时,检索头不会被激活;当模型找不到针并完全产生幻觉时,检索头会处理虚拟的token。
通过逐渐掩盖检索/随机头的数量,可以观察模型的行为如何变化。如图 4 所示,屏蔽检索头会严重损害模型的大海捞针性能,而屏蔽随机头对性能的影响要小得多。

值得注意的是,当将屏蔽头的数量 K 增加到 50(约占全部头数的 5%)时,所有模型的针测试性能均降至 50 以下,这表明顶部检索头负责大部分针检索行为。
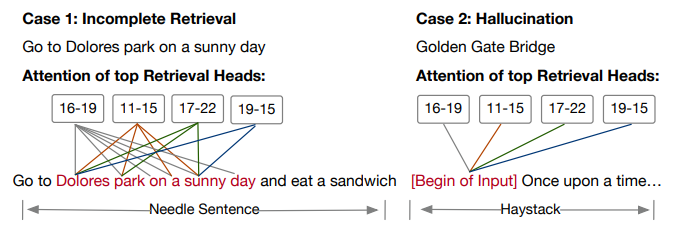
随着屏蔽头的数量增加,最初会屏蔽一小部分最强大的检索头,不完整检索开始出现。在没有最强检索头的情况下,余下较弱的头只能检索到目标信息的一部分。
形象地说,每个检索头持有“针”的一小部分,但这些碎片无法形成完整的“针”,导致最终输出不完整。这种现象通常在屏蔽得分大于0.4的检索头时开始出现。随着屏蔽头的数量进一步增加,幻觉变得更加普遍,标志着检索能力的完全失败。
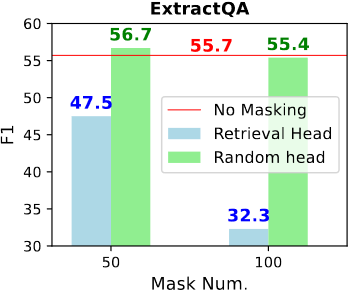
除了大海捞针类的实验,研究人员还使用 Extract QA 作为测试方法,为了确保所询问的知识不存在于模型的内部知识中,研究人员通过选择一组最新的新闻文章、从中提取一个段落并要求 GPT-4 产生答案对,类似于 Anthropic 中进行的评估。
如图 6 所示,随机屏蔽非检索头对性能没有显着影响。屏蔽检索头导致 F1 分数大幅下降,分别下降了 9.2% 和 23.1%。这些观察结果表明,现实世界的文档 QA 任务在很大程度上依赖于检索头的功能。
对CoT的性能有显著影响!
研究人员测试了Mistrial-7B-Instruct-v0.2在MMLU、MuSiQue和GSM8K上的表现,结果显示,在仅使用答案提示(不包括CoT)的情况下,屏蔽检索头或随机头并不会真正影响性能,这可能是因为模型的生成主要基于存储在FFN层中的内部知识。对于链式思维推理,屏蔽检索头则会显著影响模型的性能。

通过检查典型的错误案例,研究人员发现当掩盖了检索头,模型会变得对先前的重要信息“视而不见”,并产生虚假的 CoT 幻觉。

检索头与模型语言能力无关
神奇的是,作者提到检索头只会影响事实性,而不影响语言能力。当检索头被掩蔽时,模型说出“在多洛雷斯公园”的开头后可能产生“do other things”的幻觉,但这仍然是一个流利的句子,只是并不是“吃三明治”事实。
有网友也注意到作者提到“如果模型通过了“大海捞针”测试,那么模式总是可以观察到的”,这是否意味着,不能通过测试的模型就没有检索头!? 而作者也出了回复:
我倾向于相信(到目前为止)状态空间模型/线性和局部注意力模型不能做捞针实验的原因是因为它们没有检索头。
这倒是有些费解,不过这项工作才刚开始,期待后面会有新的发现吧!



关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675