
把GPT-3.5装进手机里?小模型爆发背后没什么神奇的魔法
AI未来指北课代表系列——AI大事儿最全、最快拆解。本文探索AI小模型崛起背后的技术路径。
文 / 腾讯科技 郝博阳

(每秒12个token,在本地模型里算是超高速了)
这一超越人们一般认知的性能,在Phi 3的论文中被形容成当前模型的表现偏离了标准的Scaling Law。(deviate from the standard scaling-laws)
小模型到底有没有在打破Scaling Law?我们得先挖挖这些小模型是用什么妙法“突破”Scaling Law的。

两条路,“突破” Scaling Law
Llama 3:有钱任性路径
Llama 3 8B所走的路径是猛加训练数据量。一个80亿(8B)参数的模型,Meta用了15万亿(15T)的数据进行训练!这和他们训练70B模型用的量级一致。所以它是符合Scaling Law的,只不过这次增加的不是参数量,而是数据量而已。
既然如此,为什么之前很少有人做这样给小参数模型喂超大数据的尝试呢?
因为在大语言模型界一直都还有一个规则,叫Chinchilla Scaling规则。这出自一篇发布于2022年的论文,作者Hoffman试图去找到对应某种参数的最佳数据训练量。他通过三种拟合方法,最终发现大概用20倍于参数量的数据进行训练是效率最高的(即tokens/parameters为20/1)。数据比这个少的话,参数多提升也不大;数据比参数多20倍的话,模型性能的提升就没有训练更大参数模型那么明显了。所以如果有足够算力去训练更多的数据时,大多数模型都会选择对应的更大的参数量级去进行训练,因为这样可以达到在一定的算力之下效果的最优,能带来做多的泛化和最好的效果。

但Meta在 Llama 3 的开发过程中对Chinchilla Scaling Law进行了一波压力测试。根据Llama 3的简易版技术文档中所述, 虽然 8B 参数模型的 Chinchilla 最优训练计算量差不多是 200B token,但Meta发现,即使在模型使用超过两个数量级(大概4万亿)的数据进行训练后,模型性能仍在继续提高。所以Meta干脆直接给 8B 和 70B 参数模型喂了15T的token进行训练,结果他们发现模型能力还在继续呈对数线性改进。
针对这点,前OpenAI联合创始人Andrej Karpathy还在Llama 3 发布后特别发了一条推文,指出只要你持续加数据量,模型就是会越来越好。他还点出大家之所以不这么做,一方面是出于误解:觉得超过Chinchilla的最佳数据量,模型的能力提升会大幅收敛。Llama 3正是用事实证明了并不会。另一方面,在现在卡慌的背景下用这么多数据持续多次的训练一个小模型并不经济,因为用同等算力和数据做大模型,其能力更强。

所以只有Meta这种坐拥35万块H100,不差卡的真土豪才敢只从扩量数据这条路上去验证Scaling Law。
Phi-3:工匠雕花路线
微软虽然也不缺卡,但他们明显还是更考虑性价比的。在Phi-3的技术说明中,mini版本所用的训练集为3.3万亿个token,也大大超过了Chichilla最优,但只有Llama 3 8B的1/5。
Phi系列从其第一代开始一直走的都更偏向于另一个路径:优化数据。除了精心筛选数据外,微软还利用更大的模型生成对应的教科书和习题集,专门优化模型的推理能力。
回到优化数据这一点上,实际上目前大模型训练时用到的数据集大多来自网络抓取,它们非常杂乱,其中有相当一部分都是网络垃圾邮件或者广告等重复且无法增加信息丰度的内容。对这些数据进行处理就能使得在这个数据集上进行训练的模型效果得到显著提升。
比如最近Huggingface就发布了一个名为Fineweb的数据集,训练了 200 多个消融模型来仔细解析和过滤,排重Common Crawl从2013-2024年间的所有数据,得到了一个15T的训练集,在这个训练集上进行训练的模型最终效果可以显著提升。
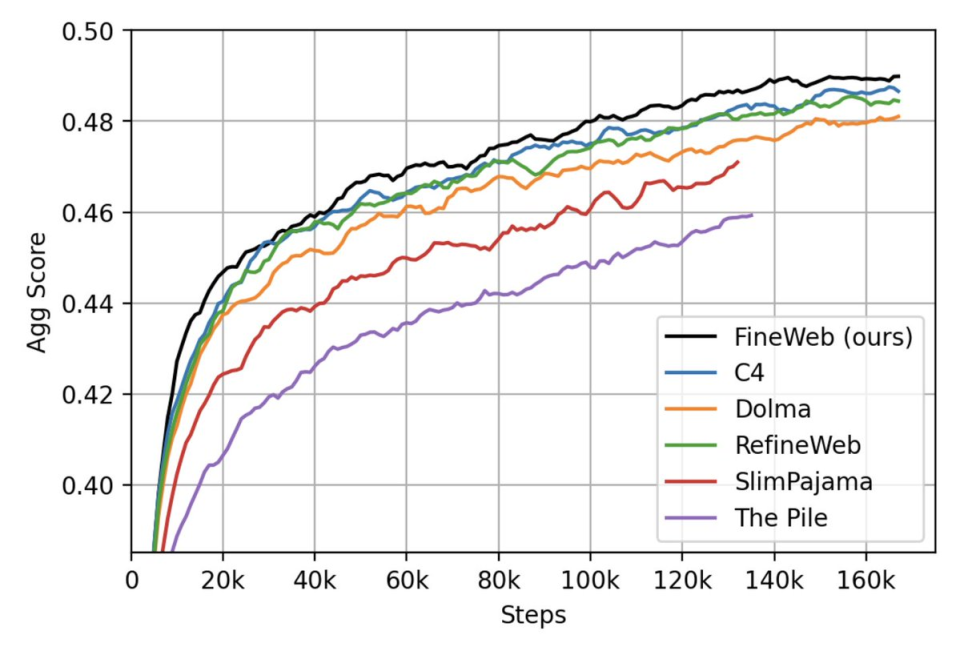
最上面的是FineWeb,最下面的是一般数据
Phi3的核心数据处理方法和逻辑没有什么改变。主要是做了一些拓展和优化,把1.5T的数据集提升到了3.3T。想了解其详细的数据处理逻辑可看前文微软的AI弯道超车法:大模型卷不过,小模型我必坐头把交椅(点击文末阅读原文即可阅读)
当然Phi 3的做法更复杂,其数据包含了两个主要组成部分,a) 经过大语言模型过滤的高质量网页数据。这些数据要进一步按照"教育水平"筛选,保留更多能提高模型"推理能力"的网页。b) 由大语言模型生成的合成数据。这部分数据专门用于教授模型逻辑推理和各种特定领域的技能。
因为Phi3 mini的内容容量较小,无法容纳所有的训练数据,它还将训练分为两个独立的阶段:第一阶段主要使用网络数据源,旨在教会模型一般知识和语言理解;第二阶段将更严格过滤的网页数据与一些合成数据混合,以提高模型的逻辑推理和特定领域能力。第二阶段会覆盖掉第一阶段中不太重要的一些常识数据,为推理能力相关的数据腾出空间。
通过这通对数据的细致处理和雕花,Phi-3 mini居然能达到比它大至少50倍的GPT3.5层级的推理能力。
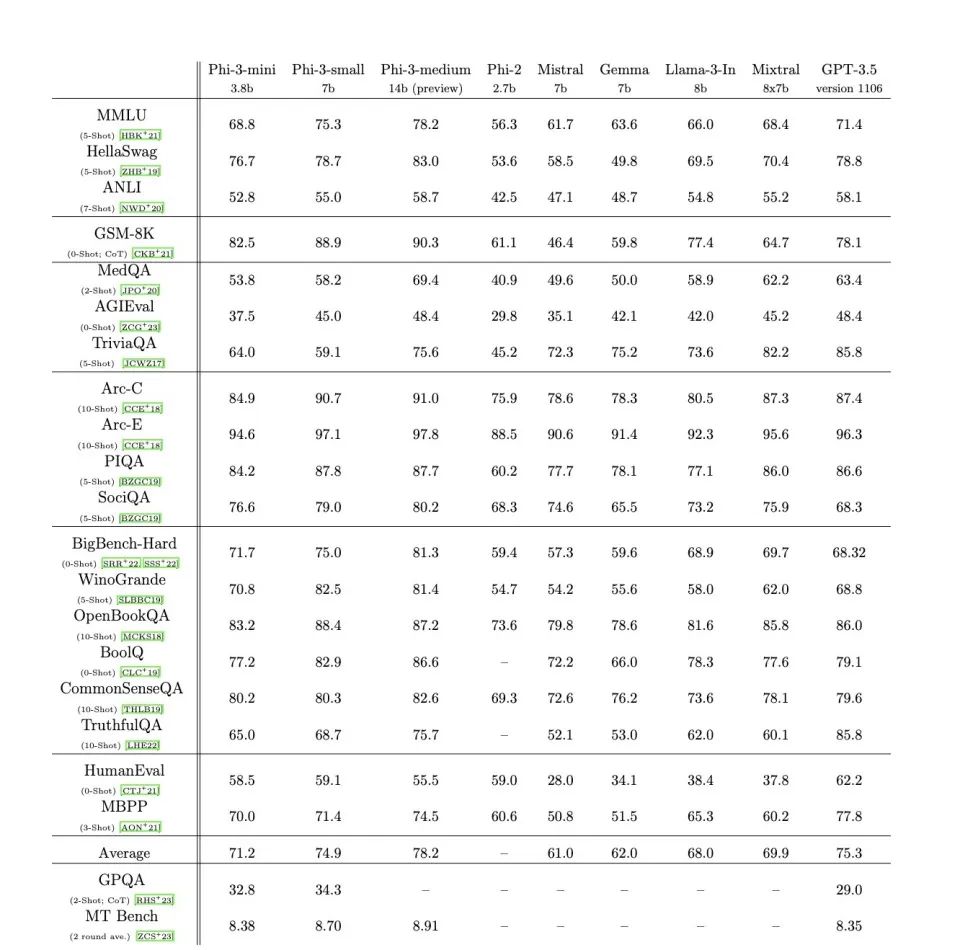
得分基本全面碾压
当然,Phi3 mini的惊艳表现其实也无法动摇Scaling Law 本身,至多只能说力大砖飞有效,但用点巧劲处理一下力(数据),砖飞的更远。

小模型越强,大模型离我们的生活就越近
最近一段时间,围绕Scaling Law的讨论,并不只限于小模型所表现出来“非标准”表现。扎克伯格在Llama 3发布之后接受访谈时就提到,缩放定律现在已经遇到了能源瓶颈,从今之后,大模型的提升会是渐进的,而非飞跃式的。而2025年实现AGI基本不太可能。
其他专家,包括AI三巨头之一的约书亚·本吉奥,反对派巨头Garry Marcus都表示,如果没有框架性的更新,在现行低效的Transformer框架下,AI的发展和Scaling速度都会放缓。
这其实在各个AI大厂的实践中也有体现。据之前外媒报道,微软为GPT-6训练搭建10万个H100训练集群。但以当前美国的电网能力根本承受不了这样的能耗,一旦在同一个州的部署超过10万个H100 GPU,那整个电网都得崩溃。
如果Scaling Law真的撞上了能源墙,那下一步大厂们应该干点什么呢?
其实和互联网大厂在发展中的逻辑一样,如果增长无法保证,那就赶紧转化成实用用例把钱赚上,稳住脚跟。
但直到今天,AI的现实用例都非常稀缺。这一方面是因为技术发展需要时间,如Agent之类真的能导向实用的技术组建还在完善过程中。另一方面其实就是大模型的高昂推理成本让很多看起来收益还不那么明显的项目很难真正落地。
但现在,随着Llama 3 8B还是Phi3 mini的出现,一条将大模型引向实用的路也越来越明朗了。

网友表示虽然高性能小模型训练贵,但推理便宜啊,整体还是更便宜,尤其对于要覆盖较大用户群体的推理成本很低
无论是在越来越强支持AI得设备上实装,还是单纯提供价格低廉的云服务,高性能小模型都意味着AI将更容易的摆脱成本上的桎梏,被更有效的应用。
小模型的强势,实际上将大模型和我们拉的更近了。



关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 腾讯科技
腾讯科技
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675