
ChatGPT参数规模被扒:只有7B
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
ChatGPT惨遭攻击,参数规模终于被扒出来了——
很可能只有7B(70亿)。
消息来自南加州大学最新研究,他们使用一种攻击方法,花费不到1000美元就把最新版gpt-3.5-turbo模型的机密给挖了出来。

果然,OpenAI不Open,自有别人帮他们Open。

具体来说,南加大团队三位作者破解出了未公布的gpt-3.5-turbo嵌入向量维度(embedding size)为4096或4608。
而几乎所有已知的开源大模型如Llama和Mistral,嵌入向量维度4096的时候都是约7B参数规模。
其它比例的话,就会造成网络过宽或过窄,已被证明对模型性能不利。
因此南加大团队指出,可以推测gpt-3.5-turbo的参数规模也在7B左右,除非是MoE架构可能不同。

数月前,曾有微软CODEFUSION论文意外泄露当时GPT-3.5模型参数为20B,在后续论文版本中又删除了这一信息。

当时引起了一阵轩然大波,业界很多人分析并非不可能,先训练一个真正的千亿参数大模型,再通过种种手段压缩、蒸馏出小模型,并保留大模型的能力。
而现在的7B,不知道是从一开始20B的消息就不准确,还是后来又再次压缩了。
但无论是哪一种,都证明OpenAI有很恐怖的模型优化能力。
撬开ChatGPT的保护壳
那么,南加大团队是怎么扒出ChatGPT未公开配置的呢?
还要说到现代语言模型中普遍存在的“Softmax瓶颈”。
当Transformer网络处理完输入,会得到一个低维的特征向量,也就是Embedding。这个特征向量再经过Softmax变换,就得到了最后的概率分布输出。
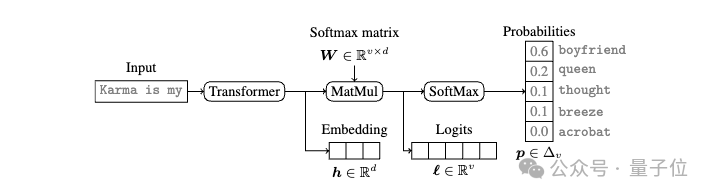
问题就出在Softmax这里,因为矩阵的秩受限于特征向量的维度,所以大模型的输出空间事实上被限制在了一个低维的线性子空间里。

这就像是无论你的衣柜里有多少件衣服,最后能穿出去的搭配,其实是有限的。这个”衣柜”的大小,就取决于你的“特征向量维度”有多大。
南加大团队抓住了这一点,他们发现,只要从API调用中获取到足够多的输出样本,就足以拼凑出这个大模型的特征向量维度。
有了这个特征向量维度,可以进一步推断大模型的参数规模、还原出完整的概率输出,在API悄悄更新时也能发现变化,甚至根据单个输出判断来自哪个大模型。
更狠的是,推测特征向量维度并不需要太多的样本。
以OpenAI的gpt-3.5-turbo为例,采集到4000多个样本就绰绰有余了,花费还不到1000美元。
在论文的最后,团队还探讨了目前的几个应对这种攻击的方法,认为这些方法要么消除了大模型的实用性,要么实施起来成本高昂。
不过他们倒也不认为这种攻击不能有效防护是个坏事,
一方面无法用此方法完整窃取模型参数,破坏性有限。
另一方面允许大模型API用户自己检测模型何时发生变更,有助于大模型供应商和客户之间建立信任,并促使大模型公司提供更高的透明度。
这是一个feature,不是一个bug。

论文:
https://arxiv.org/abs/2403.09539
参考链接:
https://x.com/TheXeophon/status/1768659520627097648
— 完 —
报名中!
2024年值得关注的AIGC企业&产品
量子位正在评选2024年最值得关注的AIGC企业、 2024年最值得期待的AIGC产品两类奖项,欢迎报名评选!
评选报名截至2024年3月31日 

中国AIGC产业峰会同步火热筹备中,了解更多请戳:Sora时代,我们该如何关注新应用?一切尽在中国AIGC产业峰会
商务合作请联络微信:18600164356 徐峰
活动合作请联络微信:18801103170 王琳玉
点这里 关注公众号:拾黑(shiheibook)了解更多 [广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 量子位
量子位
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675