
Sora 能作为物理世界模拟器吗?

OpenAI 宣称 Sora 是物理世界模拟器,虽然没有明确提世界模型的概念,但很明显,一个好的世界模拟器背后自然蕴含着一个好的世界模型。
原文链接:https://zhuanlan.zhihu.com/p/684089478

我们生存的世界有可能是Sora生成的吗
关于 Sora 是否是物理世界模拟器这点大家争议很大,有人对此支持并开始畅想未来,甚至开始质疑我们目前感知到的环境,包括我们自己,是否也是现有世界之外的一个 Sora 生成的(我很多时候也这么觉得,但跟 Sora 无关,这大概是科幻爱好者的通病。
如果这个世界真是由世界之外的 Sora 生成的,我希望写 Prompt 的大哥把关于我的那部分 Prompt 再优化一下,拜托啦)。有人表示反对并批评 OpenAI 过度炒作(我很多时候也这么觉得,主要跟 Altman 的做事风格有关,目前 OpenAI 不仅越来越 Close,而且有把大模型技术神秘化的趋势)。
我觉得,以目前的技术条件来说,单靠 Sora 本身很难构造世界模拟器,专门为了让 Sora 成为世界模拟器而用现有游戏模拟器来训练它是多此一举,这么做一来做不好,游戏模拟器相对复杂的真实世界来说就是一个玩具;二来目前经验是你想构造一个可扩展的有潜力的模型,模型结构简洁通用是个前提条件,如无必要,勿增实体。

但是,让我们把思路打开,对于构建世界模拟器这件重任,其实没有必要赋予 Sora 这么大的责任负担,不是还有 GPT 4 吗?应该让它们各司其职,各自承担起一部分责任。假设是 GPT 4+Sora 两者配合,我认为大概率未来是可以基于两者能力互补而形成世界模型,来构造出逼真虚拟世界的。可以畅想一下,如果是苹果 Vision Pro+GPT 4+Sora 组合起来会是什么场景,你可以任意时刻进入任意你想体验的世界,无论是合法的还是非法的(谷歌 Gemini 对此表示强烈反对及严正抗议),主动走入 Matrix 不再是梦,想起来是不是令人激动?

我们来仔细分析下各司其职构建世界模拟器的含义。先说无条件(Unconditional,意思没有文本指导)的图片/视频生成模型,比如基于 Diffusion 的图片/视频生成模型。无条件的 Diffusion 图片生成模型擅长对物理世界实体的外观(苹果长什么样子)、实体属性(苹果是红色的)、实体间的空间关系(苹果放在桌子上)建模,它能很好生成一个苹果的图片,本质上是生成了 3 维世界某个场景一个瞬间 Snapshot 的二维压缩平面,但是它并不知道人们把这个物体叫做“苹果”。
无条件的 Diffusion 视频生成的话,除了图片里物体间的空间关系,还可以额外学习到时间维度物体的运动规律,也就是物体的运动轨迹(苹果会从树上垂直落到地面),本质上是对物理世界 4 维时空的 3 维压缩(平面二维图像+时间维度),但是要注意的是:生成模型通过视频学会的是物体的运动规律和运动轨迹,但不是物理定律,它知道苹果应该朝下向着地面运动,因为它看过很多视频都是这样的,但这并不意味着它学会了牛顿的“万有引力”定律。没有人能只通过看到苹果下落就写出万有引力定律公式,包括牛顿也不行,牛顿能写出来也是经过大量实验以及抽象的推理思考才总结出来的。类似的,视频生成模型也不知道人们把这个视频场景叫做“苹果被风吹落到了地面”。可以看出,无条件图片/视频生成模型强在物体外在形象的表征、物体空间关系以及运动轨迹建模,但弱于抽象思考。归纳而言,可以说无条件的图片/视频生成模型着于“色相”而弱于“法”。
再说语言模型,LLM 是从大量人类语言中学习知识的,语言本身就是一种抽象的产物,所以 LLM 擅长对抽象知识的建模和生成,本质上 LLM 在 Transformer 的参数空间内构建了一个由抽象概念编织成的“知识之网”,LLM 是靠不同知识之间的相互关系而不是它的“色相”来定义具体知识的。比如它知道“苹果”这个概念,这是网中一节点,在 LLM 内部看起来就是某个“ID 编号2587的”Token;也知道“苹果是一种水果”,这代表“苹果”和“水果”两个概念之间在“知识之网”上的连线;同时也知道“苹果是红色的”这种实体属性关系,但它不知道“红色”看起来是一种什么感觉,和“绿色”的感觉是什么差异,因为颜色的感知是不同波长光波在视网膜上激发出的不同类型的电信号,本质上是一种感觉,通过语言抽象化、概念化赋予叫做“红色/绿色”的ID用于相互之间传递信息,我们人类管这种感觉叫做“红色”,本质也是把某种感知通过离散编码 ID 化,只不过 LLM 又把它编码成自己内部的数字 Token 编号而已。而且,LLM 对于空间概念理解也比较薄弱,比如它能生成“苹果在桌子上面”,但是估计不太理解“苹果在桌子左边”的空间布局是什么意思,这源于人类对空间关系的理解主要来自于视觉信道。另外,LLM 知道某个概念但是并不知道这个概念对应的外在形象具体是什么样子。所以可以看出,LLM 擅长抽象知识和抽象思考,弱于对于空间关系的理解,以及物体外在具体形象的理解。所谓 LLM 长于“法”而弱于“相”。
当在各自模态范围内不断强化模型能力的时候,本质上仍然在强化它们各自擅长之处,源于本身的弱点无法从根本上得到改善。
然后我们再说 SD、Sora 这种文本指导(Text Conditional)下的图片/视频生成模型。要注意的一点是,LLM 是通过自监督驱动来从数据学习知识的,无需人标注数据,只要把人已经写好的内容给它学就行了。但是,目前无论是 SD 这种“文生图”模型,还是 Sora 这种“文生视频”模型(目前的多模态模型也是类似的),究其本质,还是有监督学习,就是说需要大量高质量的标注好的成对的<文本,图>或<文本-视频>数据。我觉得 Sora 之所以强,最根本的原因应该归功于“合成数据”方面的优势,就是说靠人大量标注<文本-视频>肯定行不通,那么就靠机器自己去标注,在保证质量前提下,大量地、低成本地、快速地扩充标注数据数量,这是目前无论是文生图、还是文生视频效果好不好真正的秘诀和法宝。
再说回来不同模型“各司其职”构建世界模拟器的事情。文本指导(Text Conditional)下的图片/视频生成模型的核心目标不在于各自增强文本模型或者视频生成模型两者各自已经擅长的能力(一般文本编码器[text encoder]模型都是拿来主义,把训练好的文本编码模型拿来直接用,图片 encoder-decoder 模型一般也是离线训练好直接拿来用的,训练过程中参数是固定的,不会跟着文生视频训练数据而发生变化),而是建立起抽象文本和具象外在形象两者之间的grounding,即对 LLM 抽象词语概念的外在形象的绑定,学会单词“苹果”对应的外在形象是什么,也学会“河水中顺流而下”这种语言表达所对应的物体运动轨迹是什么,这是“色随法成”,即产生符合文本描述的视频表征内容。好的Grounding的意义在于联合两者各自的优势,一起来更完整的理解或者创造世界模型。
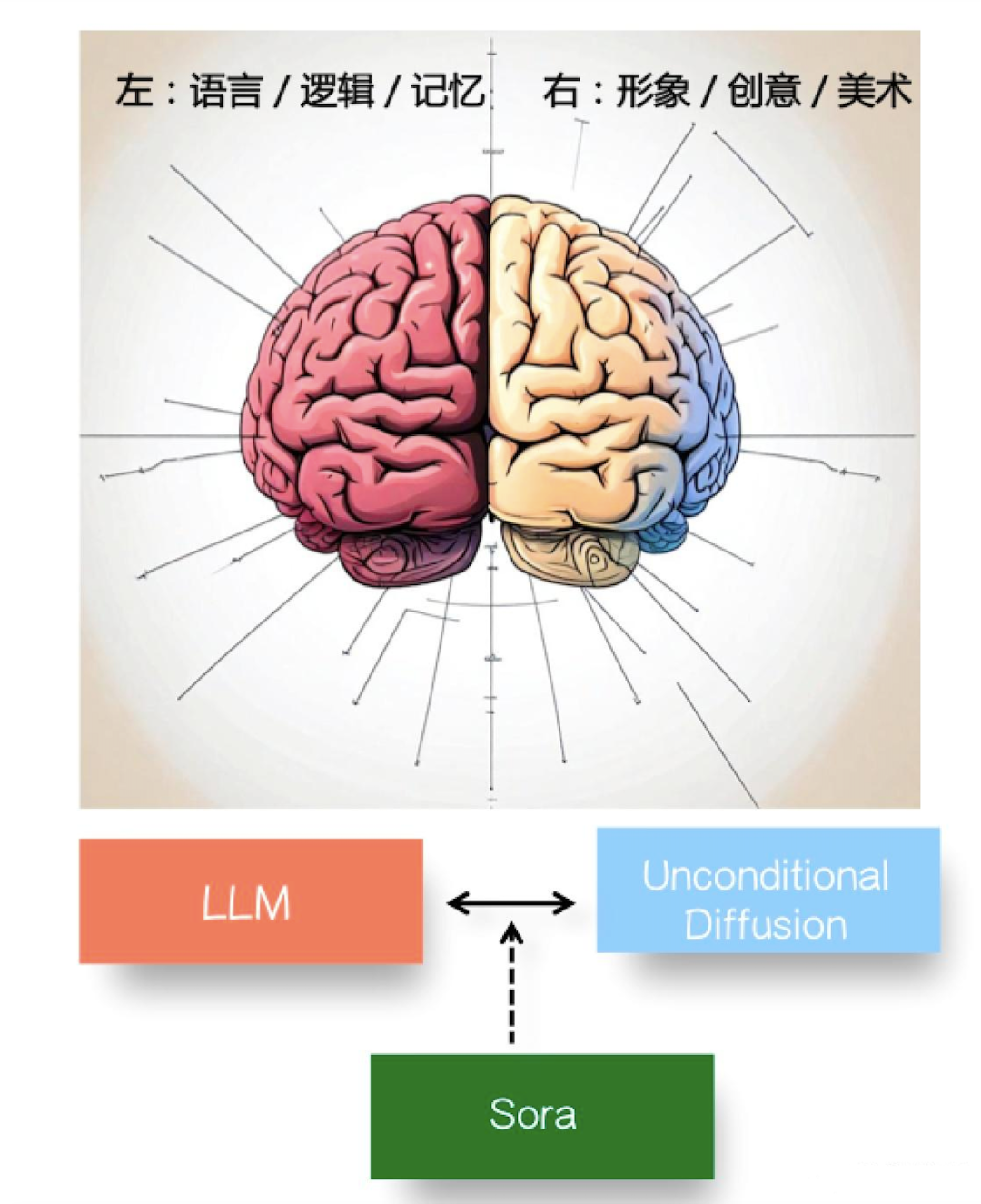
如果打个比方的话,我觉得不同类型的模型各司其职相互配合来构建世界模拟器,可以把它们之间的关系以及相互的配合过程称为解决“大模型的脑裂现象”:无条件的图片/视频模型类似人类的右脑,擅长形象思维,负责形象世界的生成;LLM 类似人类的左脑,擅长语言及抽象思考,负责抽象知识和物理法则的生成和语言描述,包括复杂物理世界规律的建模和表述。如果没有大量高质量的<文本,视频>配对数据的训练,单看两者,就存在大模型表述世界的脑裂现象,而通过类似 Sora 这种大量配对数据的训练,在两者之间建立起良好的grounding,相当于用“胼胝体”建立起了左右脑之间的信息传输通道,两者联合理解和生成复杂的现实世界。
那你说 Sora目前包含世界模型吗?我觉得是包含的,但已经是通过 GPT 4+Sora 这种打配合的模式。Sora 的技术报告里有一句提到“当用户输入 Prompt 后,会用 GPT 把短的 Prompt 改写成长的详细的视频描述文字,然后再作为 Sora 的输入”(we also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model.),估计这里用的就是 GPT 4。如果 Sora 世界模型的总含量是 100 的话,我相信 80% 的世界模型含量体现在 GPT 4 产生的视频详细描述里,就是说可以把很多抽象知识、物理世界的规则甚至是物理定律对应的物体外在表现,通过语言描述体现在送给 Sora 用于产生视频的文字提示里,比如在改写的 prompt 里写清楚:“篮球碰到墙壁反弹了回来/篮球落到水里溅起水花/路面的积水反射出大楼的倒影等”,而剩下的 20% 世界知识含量包含在 Sora 的视频生成过程中(比如物体对应的外观、物体的运动轨迹等,这个可能比较适合直接从图片和视频里学习)。既然 LLM 擅长物理世界的抽象知识表达,我们不如充分利用它的优点,而 Sora 则一方面专注做好 Grounding,这体现为更精准地遵循文本 Prompt 指令,如果你 prompt 里写着“路面积水反射出大楼的倒影”而 Sora 遵循文本能力强,看着 Sora 就是了解物理定律的,但是这个物理规则来自于 GPT 4 产生的 Prompt,Sora 可能只是 Grounding 做得好能遵循指令而已;另外一方面 Sora 把物体的外在形象一致性、空间关系以及运动轨迹表达好就行,两者配合好,我感觉是有望构建物理世界模拟器的。
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨询和教育平台 Boolan 联合主办的「全球机器学习技术大会」将在上海环球港凯悦酒店举行,特邀近 50 位技术领袖和行业应用专家,与 1000+ 来自电商、金融、汽车、智能制造、通信、工业互联网、医疗、教育等众多行业的精英参会听众,共同探讨人工智能领域的前沿发展和行业最佳实践。
本文作者张俊林作为演讲嘉宾,将发表《原生多模态大模型的方法与问题:以Gemini为例》的主题演讲,扫描下方二维码了解更多演讲内容:

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
![啾啾睡不醒u大黄鸭[春游家族] 2中山·紫马岭公园 ](https://imgs.knowsafe.com:8087/img/aideep/2021/11/24/1f10af7cdc9f49f56083741459809520.jpg?w=250)





 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675