
GPT-4抽象推理PK人类差距巨大!多模态远不如纯文本,AGI火花难以独立燃烧

新智元报道
新智元报道
【新智元导读】圣达菲研究所的科研人员用非常严谨的定量研究方法,测试出了GPT-4在推理和抽象方面与人类水平还有较大差距。要想从GPT-4的水平发展出AGI,还任重道远!

ConceptARC是如何测试的?
ConceptARC基于ARC之上,ARC是一组1000个手动创建的类比谜题(任务),每个谜题包含一小部分(通常是2-4个)在网格上进行变换的演示,以及一个「测试输入」网格。
挑战者的任务是归纳出演示的基础抽象规则,并将该规则应用于测试输入,生成一个经过变换的网格。
如下图,通过观察演示的规则,挑战者需要生成一个新的网格。

测试结果,GPT-4比起人类还有很大差距
研究人员分别对纯文本的GPT-4和多模态的GPT-4进行了测试。
对于纯文本的GPT-4来说,研究人员使用更加表达丰富的提示对GPT-4的纯文本版本进行评估,该提示包括说明和已解决任务的示例,如果GPT-4回答错误,会要求它提供不同的答案,最多尝试三次。
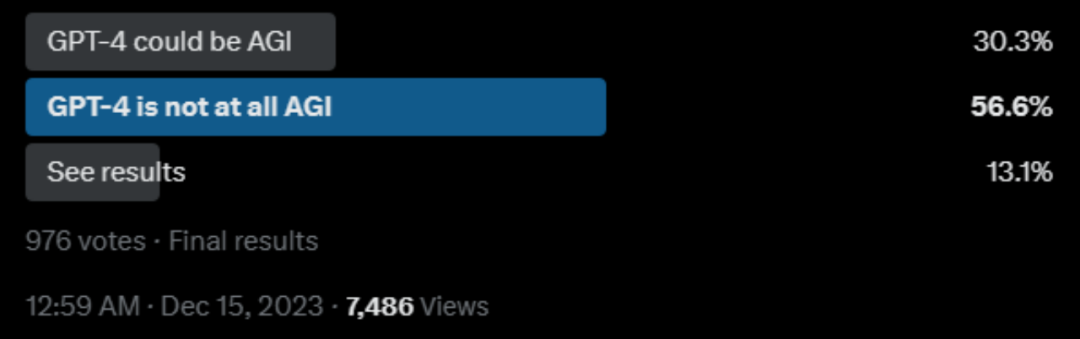
但在不同的温度设置下(温度是一个可调节的参数,用于调整生成的文本的多样性和不确定性。温度越高,生成的文本更加随机和多样,可能包含更多的错别字和不确定性。),对于完整的480个任务,GPT-4的准确率表现都远远不如人类,如下图所示。


网友分析
有位大牛网友对于GPT-4在ConceptARC上的表现,发了足足5条评论。其中一条主要原因解释道:
基于Transformer的大型语言模型的基准测试犯了一个严重错误,测试通常通过提供简短的描述来引导模型产生答案,但实际上这些模型并非仅仅设计用于生成下一个最可能的标记。
如果在引导模型时没有正确的命题逻辑来引导和锁定相关概念,模型可能会陷入重新生成训练数据或提供与逻辑不完全发展或正确锚定的概念相关的最接近答案的错误模式。
也就是说,如果大模型设计的解决问题的方式是上图的话,那实际需要解决问题可能是下图。


研究人员说,对于提升GPT-4和GPT-4V在抽象推理能力的下一步,可能尝试通过其他提示或任务表示方法实现。
只能说,对于大模型真的能完全能达到人类水平,还是任重而道远啊。



关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675