
盘点2023,大模型产业狂奔的365天
来源:量子位 | 公众号 QbitAI
无尤 发自 2023
4万亿摄氏度(345MeV),是美国纽约布鲁克黑文国家实验室在2010年利用相对论性重离子对撞机进行金离子对撞实验时创造的,人类迄今为止所能制造的最高温度,是太阳核心温度的26万倍。
如果说2023年有一项技术能够达到如此空前的“热度”,毫无疑问,那就是生成式大语言模型。

但是不同于那不足十亿分之一秒的、转瞬即逝的4万亿度高温,大模型对各行各业的深远影响,在2023年既如“春雷万钧”,又似“润物无声”。所以,如果要用两个关键词形容2023年的大模型产业,除了“热”,还有“卷”。
2022年11月,ChatGPT横空出世,在仅仅两个月过后,ChatGPT月活跃用户就成功破亿,并成为史上月活用户最快破亿的消费级应用。初出茅庐的ChatGPT像个全能战士,能聊天、会写代码、写论文…。在人们感慨这款对话应用功能强大的同时,其背后的大模型——GPT,第一次真正意义上被推进了所有公众的视野。
现代AI技术主要是通过构建深度神经网络来模拟人脑的学习过程,通过学习大量数据“沉淀”出AI模型,用来完成诸如图像分类、目标检测、机器翻译、语言理解等特定任务。但这一次的大模型不一样了,超大规模的数据量、算力和神经网络规模使得模型产生了“智能涌现”。
目前,“智能涌现”最通俗的解释,可能来自于百度创始人李彦宏,他认为,过去的人工智能是,想让机器学会什么技能,就教它什么技能。教过的,有可能会;没教过的,就不会。大模型出现“智能涌现”之后,以前没教过的技能,它也有可能会了。
2023年,大模型领域的研究与创新在国内外“两翼齐飞”。全球科技大厂与众多创业公司、学术机构纷纷投身这场技术浪潮。粗略统计,目前全球已经发布了数百个大模型,可谓是在一年时间里,把一项通用技术“卷”上了天。
但是要在千行百业里种下大模型的“花”,除了模型本身,还需要针对大模型升级云计算基础设施、配套相应的平台与工程化能力、配套面向上层应用的全新范式开发工具。
卷模型:全球已发布几百个基础大模型,2024进入大规模淘汰赛
作为大模型技术研究的全球领导者,OpenAI背靠微软这位“金主爸爸”,在2023年3月、9月和11月,相继推出GPT-4、GPT-4V、GPT-4 Turbo,在基础大模型表现方面被公认为遥遥领先,被全球同行玩家视作追赶对象和比较基准。
但是在11月,OpenAI上演了一出联合创始人、CEO——Sam Altman,被董事会闪电解雇,到加入微软、最终回归的“宫斗”闹剧后,不少人也对OpenAI未来前景产生了一定担忧。
作为OpenAI最强有力的竞争对手,Anthropic由前OpenAI高管创立。
23年3月和7月,Anthropic陆续发布了旗下大模型产品Claude和Claude 2,并且推出了直接与ChatGPT竞争的对话机器人应用,强调打造“安全且负责任的AI”。值得一提的是,Claude 2刚推出时支持100k上下文窗口,11月升级2.1版本,支持200k“超大杯”上下文窗口,分别对GPT-4和GPT-4 Turbo实现了碾压。Anthropic优异的表现也在23年下半年吸引了来自亚马逊的40亿美元、谷歌的20亿美元新投资。
如果说OpenAI赋予了GPT灵魂,那么这具“躯壳”在早年间可以说是Google给的。
作为Transformer架构的始作俑者,Google在2023年也不甘落后,推出了PaLM 2 、Gemini等现象级大模型;在大模型领域沉寂许久的云计算巨头AWS,在4月发布Titian大模型后,直至年底才被爆料正在训练一个新的、内部代号为「Olympus」的大模型,参数将高达2万亿;此外,阿联酋的技术创新研究所(TII)与Meta则发力开源,TII最新发布的Falcon 180B对Meta的Llama 2实现了超越,成为迄今为止最强的开源大模型。
回到国内市场,最先发力大模型的企业是百度。
2023年3月,百度率先推出生成式大语言模型——文心一言,填补了国内这一领域空白,并在发布后四个月内,高速迭代至3.5版本,相比3.0版本,训练速度提高了2倍,推理速度提高了30倍,模型效果累计提升超过50%。在首个真正意义上的权威机构评测(IDC《AI大模型技术能力评估报告,2023》)中,文心大模型超越GPT-3.5,并摘得国内大模型表现第一名的桂冠。10月,李彦宏宣布文心大模型4.0正式发布,并发表了“文心大模型4.0综合能力与GPT-4相比毫不逊色”的豪言壮语。
此外,阿里巴巴与腾讯则分别在上、下半年发布了自家的大模型:通义千问和混元。随着百川智能、智谱AI、零一万物等一众初创公司加入基础大模型混战,国内大模型市场彻底进入“战国”时代。
卷算力:大模型率先重构云计算,2024智能计算开始拼「性价比」
大模型需要巨量的算力资源来支撑庞大的系统和训练、推理任务。
从全球主流大模型玩家的成分中我们不难看出,如AWS、微软、Google、百度、阿里等,本身都是云计算厂商,有着充足的算力储备。而OpenAI、Anthropic、智谱AI、百川智能等创业公司虽然自身不具备云服务能力,但也需要依附云计算厂商才能实现模型的迭代升级。
收入创下 181.2 亿美元的纪录,环比增长 34%,同比增长 206%;数据中心收入创下 145.1 亿美元的纪录,环比增长 41%,同比增长 279%,这是英伟达交出的第三季度财报数据。创始人兼首席执行官黄仁勋表示:“从公司强劲的增长中可知,各行各业都在经历从通用计算到加速计算和生成式 AI 的平台转型。”
云计算厂商在大模型发展浪潮中有着创业公司无法比拟的巨大优势。近期,Omdia Research发布的英伟达GPU出货量测算图在网络上走红,则在一定程度上反映了云计算大厂对AI算力的焦虑。但是大模型的算力仅靠买买买就够了吗?
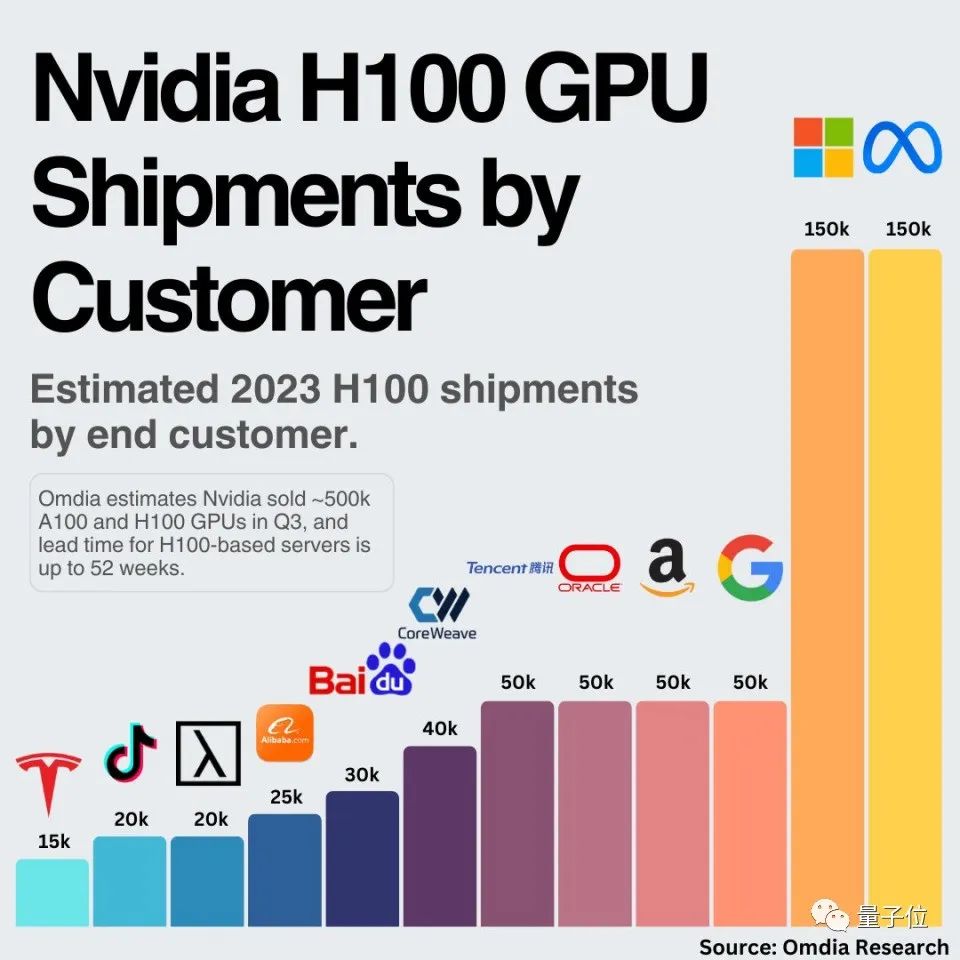
事实上,云计算厂商普遍选择多条腿走路的方式,除了囤积GPU以外,基于自身对大模型技术的理解,打造面向大模型训练、推理场景的专属的DSA(Domain Specific Architecture)架构芯片,规模化使用后不但可以摊薄成本,还可以避免未来被单一GPU供应商所绑定。比如AWS打造的Trainium和Inferentia系列芯片、微软的Maia、华为的昇腾、百度昆仑芯等。
随着摩尔定律放缓甚至失效,大模型对智算集群有效算力、稳定性提出极高要求,异构算力和智算集群的系统级优化至关重要,比如微软除了大宗采购英伟达GPU之外,还将大力引入AMD Instinct MI300X等异构算力,并大力优化基于自研芯片Maia的智算集群。
国内,以百度为首的云计算厂商也在智算领域投入了大量精力。比如百度在年底发布了基于自研昆仑芯和华为昇腾打造的两款AI计算实例,升级AI异构计算平台百舸3.0,万卡集群有效训练时间占比达到98%,同时兼容一众国内外主流AI芯片等举措,可谓是珠玉在前,国内市场无人出其右。
卷工具:大模型从“毛坯房”到“精装修”,2024继续卷“平台配套”
大模型技术的突破,除了大数据、大算力这些“硬疙瘩”,背后常常被忽视的还有平台、工程化等方面的积累,这些也是客户用好大模型的关键要素。
创业公司普遍聚焦开发大模型本身,并且有不少选择了开源路线。虽然开源拥有更好的灵活性,但是大模型时代,除了昂贵的算力成本,缺少配套工具还会产生极高的隐形成本,并对客户AI技术储备和二次开发能力提出了极高要求。对于用户来说,大模型不应该是“毛坯房”,也不能没有“物业”。
有别于传统深度学习时代小模型的开发范式,大模型需首先要全新的、完整的工具链来支撑从数据管理、到模型的重训、精调、评估等开发的全流程。而在全球范围内,首先推出此类平台的既不是OpenAI、也不是微软、AWS、Google这些海外巨头,而是百度。
大模型本身和配套工具必须得齐步走,不然光说大模型落地千行百业,模型厂商能挨家挨户做定制化吗?这一点上,百度想的很清楚。
2023年3月,百度推出文心一言大模型时,李彦宏讲到文心一言更大的故事是在云计算。短短10天之后,百度智能云就揭晓了答案,推出全球首个企业级一站式大模型平台千帆,宣告百度不但能做出国内最好的大模型,还要帮其他人做好大模型。而在5月的一场活动中,百度工程师还在国内首次演示了如何基于一站式平台微调行业专属大模型的全过程。

随后,阿里云CTO周靖人在10月底的云栖大会发布了阿里云百炼大模型服务平台;微软则是在11月中旬发布了自家大模型服务平台Azure AI Studio;AWS则是在11月底才更新了Amazon Bedrock服务功能,新增包括模型微调、基于Amazon Titan大模型的预训练等功能。
卷应用:应用开发范式被全面颠覆,2024 AI原生应用将涌现

如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675