
99个大模型微调模型/数据/工具
免费扫描参与课程(附老师ppt原稿&100+大模型论文)
领99个大模型微调模型/数据/工具
(文末有福利)
导师推荐100+大模型论文合集
我们邀请了清华大学博士,AI顶会审稿人青山老师为大家带来——惊艳的大模型高效参数微调法!来和大家聊一聊有关大模型微调的方法、未来趋势及创新点!

免费扫描参与课程(附老师ppt原稿&100+大模型论文)
领99个大模型微调模型/数据/工具
(文末有福利)
讲师介绍—青山老师
▪️研究领域:工业故障诊断、医学图像分割、医学多模态问答、不平衡学习、小样本学习、开集学习和可解释性深度学习等。
▪️共发表20余篇SCI国际期刊和EI会议论文,包括一区期刊IEEE Transactions on Industrial Informatics (影响因子11.648),Applied Soft Computing (影响因子8.263),Neurocomputing (影响因子5.779), ISA Transactions (影响因子5.911),Journal of Intelligent Manufacturing (影响因子7.136) 等。论文引用200+。
▪️长期担任人工智能顶级会议AAAI等审稿人, Neurocomputing,Expert Systems with Applications等国际顶级期刊审稿人。
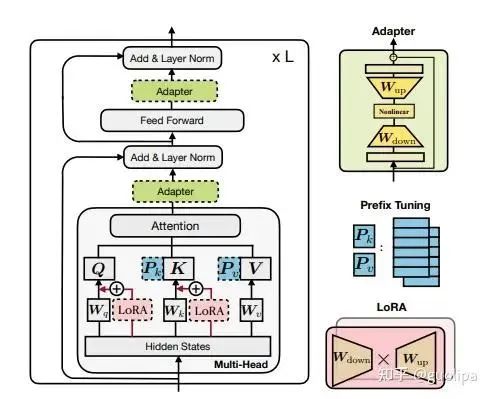
Prefix-tuning和P-tuning通过引导模型生成过程,使模型能够更准确地满足任务需求。
Adapter技术通过添加轻量级的适配器层,实现了快速的任务适应和灵活性。
Low-Rank Adaptation(LoRA)通过低秩近似减少模型参数量,提高模型的效率和部署可行性。
REcurrent ADaption(READ)在保持较高质量模型微调效果的同时,可以节省56%的训练显存消耗和84%的GPU使用量。
免费领99个微调数据/模型/工具
▪️58个开源的微调数据
▪️18个开源垂直微调模型
▪️23个开源的指令微调与强化工具
(文末有福利)

PEFT 方法可以分为三类,不同的方法对 PLM 的不同部分进行下游任务的适配:
Prefix/Prompt-Tuning :在模型的输入或隐层添加 k 个额外可训练的前缀 tokens(这些前缀是连续的伪 tokens,不对应真实的 tokens),只训练这些前缀参数; Adapter-Tuning :将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块称为 adapter(适配器),下游任务微调时也只训练这些适配器参数; LoRA :通过学习小参数的低秩矩阵来近似模型权重矩阵 W 的参数更新,训练时只优化低秩矩阵参数。
作为一个科研小白,怎么发表一篇大模型微调相关的优质论文?
为了论文,大家都在努力地设计新网络、新策略、新training算法,只要能够在某一问题上做到一个很好的performance,论文就水到渠成。而想要快速达到,来自前辈的指点不可或缺。
一个好的指导老师的作用是,没有课题,能够结合所在课题组具体情况,结合最近热门研究方向,帮你规划课题,如果有了课题而缺少创新方向,老师能够快速帮你找到几种切入点,几种框架,甚至连需要读哪些文献都帮你想好了......
扫描二维码
获取学术大咖科研指导
(文末有福利)

文末福利



关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 程序员狗哥
程序员狗哥
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675