
机器学习硬件十年:性能变迁与趋势

本文分析了机器学习硬件性能的最新趋势,重点关注不同GPU和加速器的计算性能、内存、互连带宽、性价比和能效等指标。这篇分析旨在提供关于ML硬件能力及其瓶颈的全面视图。本文作者来自调研机构Epoch,致力于研究AI发展轨迹与治理的关键问题和趋势。
要点概览
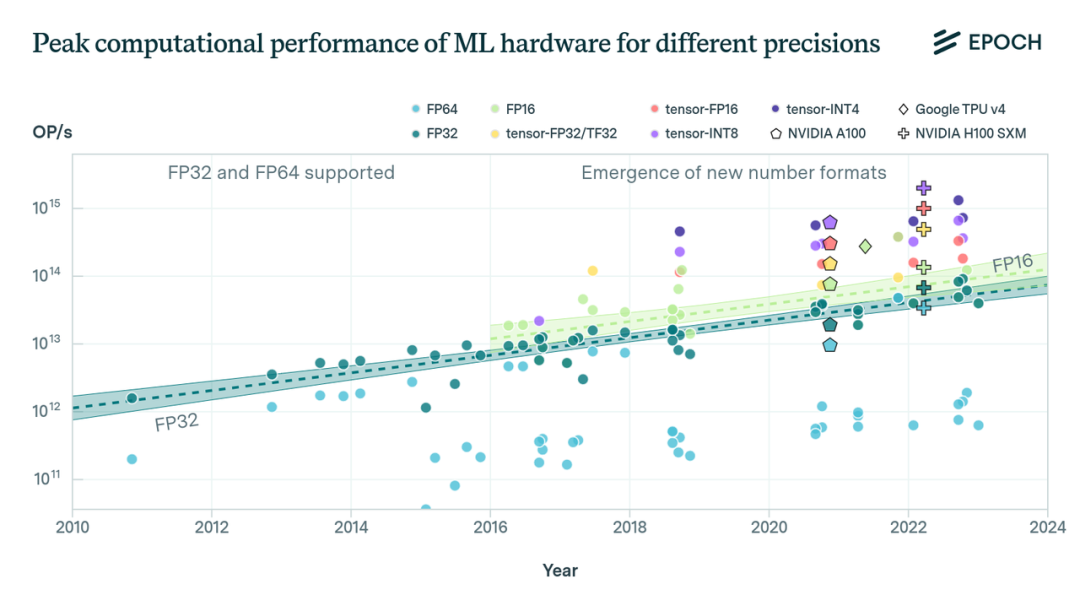
图1:常见机器学习加速器在给定精度下的峰值计算性能。自2016年以来,已出现了新的数值格式。趋势线展示了带有八个或更多加速器的数值格式:FP32、FP16(FP = 浮点、张量-* = 张量核心处理、TF = Nvidia 张量浮点、INT = 整数)
我们研究了GPU在不同数值表示、内存容量、带宽以及互连带宽方面的计算性能,使用的数据集包括2010年到2023年常用于机器学习实验的47个ML加速器(GPU和其他AI芯片),以及2006年到2021年的1948个GPU。主要发现如下:
1、与传统32位浮点数(FP32)相比,低精度数字格式如16位浮点数(FP16)和8位整数(INT8)等与专用张量核心单元相结合,可以为机器学习工作负载带来显著的性能提升。例如,尽管使用的数据量有限,但我们估计tensor-FP16比FP32的速度快约10倍。
2、鉴于用于SOTA ML模型训练和推理的大型硬件集群的整体性能取决于计算性能以外的因素,所以我们研究了内存容量、内存带宽和互连,发现:
内存容量每4年翻一番,内存带宽每4.1年翻一番。它们的增长速度比计算性能慢(计算性能每2.3年翻一番)。这是一个常见发现,通常被称为内存墙(memory wall)。
最新的ML硬件通常配备专有的芯片间互连协议(英伟达的NVLink或谷歌TPU的ICI),与PCI Express(PCIe)相比,这些协议在芯片之间提供了更高的通信带宽。例如,H100上的NVLink支持的带宽是PCIe 5.0的7倍。
3、分析中发现的关键硬件性能指标及其改进速度包括:ML和通用GPU的计算性能(以FLOP/s计)都是每2.3年翻一番;ML GPU的计算性价比(以每美元FLOP计)每2.1年翻一番,通用GPU每2.5年翻一番;ML GPU的能效(以每瓦特FLOP/s计)每3.0年翻一番,通用GPU每2.7年翻一番。

表1:关键性能趋势。所有估算仅针对机器学习硬件。方括号中的数字表示通过1000次bootstrap采样得出的[5; 95]百分位估算。OOM代表数量级,N表示数据集中的观测次数。请注意,性能数据是指稠密矩阵乘法性能。

引言
过去十年中,机器学习的进步在很大程度上是通过扩大用于训练的计算资源(计算)规模实现的(Sevilla等人,2022年),硬件性能的提升在这一进展中发挥了一定作用。随着我们从少量芯片转向大规模超级计算机,对ML R&D(Cottier,2023)投资的增加导致硬件基础设施规模的相应提升。
本文概述了在各种数字精度和专用组件(如张量核心)方面的计算性能趋势。此外,我们还分析了其他性能因素,如内存容量、内存带宽和互连带宽。总的来说,我们分析了ML硬件规格和组件的整体情况,这些规格和组件共同决定了硬件的实际性能,尤其是在大规模ML模型时代。
在这个过程中,我们比较了各种度量标准下的峰值性能,这些指标来自硬件生产商的规格表。[2]通常,由于工作负载规格等各种因素和内存容量以及带宽等规格的限制,实际利用的计算性能只是指定峰值计算性能的一小部分。例如,根据Leland等人在2016年的研究,常见超级计算工作负载的实际利用率可能在5%到20%之间,而在机器学习训练中,这取决于模型的规模、并行化方式等因素(Sevilla等人,2022),这个比例可能在20%到70%之间。尽管如此,峰值性能仍可作为比较不同硬件加速器和世代的有用上限和标准基础。
术语
数字表征:我们将数字表征分为三个维度:
位长/精度:从4位到64位不等,通常用于描述存储数字的位数。
数字格式:指特定的位(bit)布局,如整数或浮点数。数字格式通常包括FP32等位长度,但我们拆分了位布局和位长度[3]。
计算单元:显示是否使用了专用矩阵乘单元。在这篇文章中,我们只区分张量和非张量。
硬件加速器:指加速ML工作负载的芯片,如GPU或TPU。我们在通用术语中可交替使用芯片和硬件加速器这两个术语,而在指代专门的加速器时则使用GPU和TPU。

数据集
我们从两个关键数据集中汇编了硬件规格。第一个数据集在2019年Sun等人的研究(https://arxiv.org/abs/2202.05924)基础上,包含了2006年至2021年期间发布的1948款GPU,我们将其称为通用GPU数据集(主要基于一些不常用于机器学习训练的通用GPU)。第二个数据集仅包含自2010年以来的47个ML硬件加速器,如NVIDIA 的GPU和Google的TPU,它们通常在重要的机器学习实验中使用(根据2022年Sevilla等人的定义)。
我们自己整理了后一个数据集,并将其称为ML硬件数据集,简称ML数据集(基于ML GPU)。此数据集可以在我们的数据表中公开获取(https://docs.google.com/spreadsheets/d/1NoUOfzmnepzuysr9FFVfF7dp-67OcnUzJO-LxqIPwD0/edit?usp=sharing)。

主要性能指标趋势
在本节中,我们将介绍不同数字表征、内存容量、计算性价比和能效的趋势。我们将简要解释每个指标与ML开发和部署的相关性,展示我们的发现,并简要讨论它们的含义。
数字表征
用于计算的数值表征对计算性能有很大影响。具体说来,每个值的位数决定了计算密度(每秒每芯片面积的运算次数)。[4]近年来,硬件制造商已经为ML应用引入了专门的低精度数值格式。虽然FP64在高性能计算中很常见,[5]但在过去15年左右的时间里,FP32的性能一直是大多数消费级应用关注的焦点。
近年来,精度较低的数值格式变得更加普遍,因为低精度已经足够开发和部署ML模型(Dettmers等人,2022;Suyog Gupta等人,2015年;Courbariaux等人,2014年)。根据Rodriguez(https://deeplearningsystems.ai/#ch06/#61-numerical-formats,2020),到目前为止,FP32仍然是机器学习训练和推断中采用最广泛的数值格式,行业越来越倾向于在某些训练和推理任务中过渡到更低精度的数值格式,如FP16和Google的bfloat16(BF16),以及用于部分推理工作负载的整数格式INT8。[6]其他知名新兴数值格式包括16位标准浮点格式FP16,整数格式INT4,以及NVIDIA开发的19位浮点格式TF32。[7]
FP32和FP16的计算性能
从历史上看,近20年来,FP32精度的计算性能趋势一直相对稳定,呈现出2.3年翻倍一次的趋势,与摩尔定律的速度密切相关。在过去几年,特别是自2016年以来,我们已经看到了专门支持FP16精度的硬件的出现,这增加了绝对计算性能,同时减少了位长。

图2:过去二十年,FP32和FP16精度下的通用和ML GPU峰值性能。上图显示,ML GPU的中位性能高于所有通用GPU,但增长率相似。下图显示,2014年一些硬件加速器开始提供FP16性能细节。
在过去十年中,FP32的通用硬件和ML硬件的计算性能显示出几乎相同的增长率,但在性能水平上有所不同。我们的ML硬件数据集中的加速器始终处于最佳可用硬件之列。我们认为,这在一定程度上是因为机器学习实践者选择了最强大的可用硬件,其次,这也是由于最近推出的专门针对机器学习市场的高端数据中心GPU的推出,例如英伟达的V/A/H100或谷歌的TPU。
通过硬件支持更低精度的数值格式以提高计算性能
降低数值精度所带来的性能提升得益于现代机器学习芯片中多重架构的改进,而不仅仅是单纯降低位宽所能达到的。较小的数据类型使得每平方芯片面积可以进行更多的浮点运算,并减小了内存占用。
然而,其他方面的进步也在很大程度上做出了贡献:引入了专门用于矩阵乘的新指令;[8]硬件数据压缩;消除了诸如NVIDIA A100中的矩阵乘硬件中多余的数据缓冲区,这有助于降低数据和指令内存需求,从而提高了单位芯片面积上的操作数。H100更快的内存访问能力进一步优化了上述进展(Choquette, 2023).。
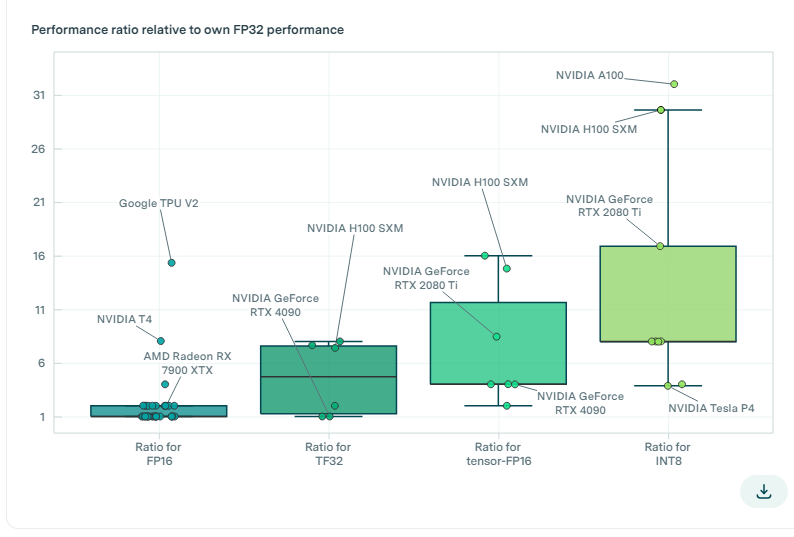
图3:箱线图显示了不同精度数字格式下ML加速器性能相对于其FP32性能的比值,这展示了相对于FP32的性能改善。我们发现,相对于它们自身的FP32性能,采用新的数值表示方式tensor-FP32/TF32、tensor-FP16和tensor-INT8可以分别使平均计算性能提高约5倍、8倍和13倍。并非所有GPU都专门支持低精度格式,我们从图中剔除了那些在较低精度格式上的计算性能未能超过较高精度格式的GPU型号,以便筛选出缺乏专门支持的GPU。
近年来,由于使用了较低的数字精度,GPU在机器学习工作负载中的性能大幅提升。平均而言,与在同一GPU上使用FP32相比,使用tensor-FP32(TF32)、tensor-FP16、tensor-INT8和tensor-INT4等精度较低的数值格式分别可提供约5倍、8倍、13倍和18倍的计算性能。
历史数据显示,FP32性能峰值每2.3年翻一番,这些较低精度的加速效果相当于性能提升了3到9年。然而,最大的加速效果可能超过平均值。与FP32相比,NVIDIA的H100在TF32、FP16和INT8下分别实现了约7倍、15倍和30倍的加速效果。
因此,对于H100来说,与典型的GPU相比,较低的精度提供了比FP32更大的性能增益。正如我们所看到的,虽然使用较低精度能极大地提升计算性能,但出于模型准确性方面的权衡,通常还是会使用较高精度进行训练。[10]尽管TF32、FP16和INT8格式在H100上相较于FP32提供了加速效果,但需要注意的是,这不仅仅是因为较小的数值格式更高效,H100很可能针对这些格式的操作进行了优化,从而促成了速度提升。
内存容量和带宽
典型的处理器核心通过读取数据、处理数据,并将处理后的结果写回内存来执行计算。因此,内存充当了在处理周期之间存储数据的媒介。硬件倾向于使用内存层次结构:从在计算单元附近存储数百KB快速访问数据的寄存器文件,到能够容纳数十GB较慢访问数据的随机存取存储器(RAM)。[11] 数据定期从较大的慢速访问RAM通过中间缓存存储器传输到寄存器文件,必要时再写回。加速器数据表大多提供加速器卡上可用的最大RAM[12]。我们称这些RAM位的数量为内存容量。数据以块的形式传输到最大RAM中,具体取决于所使用的内存技术,这需要一些处理周期。我们将能够每秒传输到最大RAM的最大位数(即峰值比特速率)称为内存带宽[13]。
包含硬件加速器的系统通常包含一个主存储器,用于存储应用程序和数据。然后,这些数据被传输到加速器进行处理。为确保在训练或推理期间模型权重和训练数据在硬件加速器上随时可用,需要更大的内存容量。如果数据无法适应加速器的内存,逻辑(logic)将需要使用CPU内存,甚至更高级别的内存(例如硬盘),这将显著影响时延和带宽。实际上,为避免这种性能损失,模型数据分发到多个硬件加速器的内存中。
硬件处理能力的进步需要更大的内存带宽。如果没有足够的数据输入,就无法达到峰值计算性能,内存带宽就会成为瓶颈[14],这被称为带宽墙(Rogers等人,2009)或通常所说的内存墙。
如图4所示,相对于计算性能的改善,内存容量和带宽的增长速度较慢。具体而言,就通用GPU来说,内存容量每3.04年翻一番,而ML加速器则为4年,内存带宽分别为每3.64年和4年翻一番。相比之下,根据之前的分析,计算性能每2.3年翻一番。

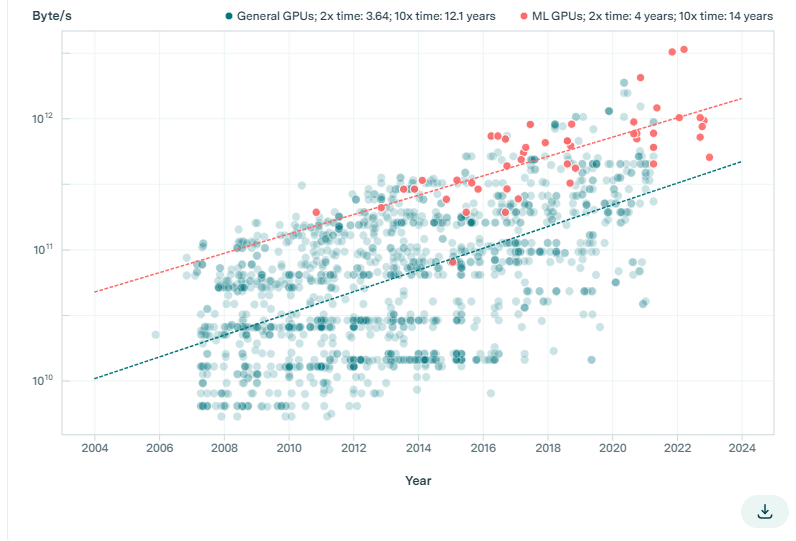
图4:通用硬件与ML硬件的内存容量和带宽的变化轨迹。我们发现所有这些趋势都比计算性能的趋势慢(计算性能每2.34年翻一番),这与通常所说的内存墙趋势一致。
如人们所预期的那样,在内存容量和带宽方面,ML硬件超过了中位的GPU。然而,即使在这方面,这些指标的增长速度也一直落后于计算性能的增长速度(每2.3年翻一番)。这一趋势表明,对于大规模ML应用而言,内存正在成为一个日益关键的瓶颈。当前的架构改进,比如引入更少位的数字表征,可能会减轻这种内存限制。然而,如果不加快发展,这一内存瓶颈将在未来几年继续影响整体性能。[15]
对于一些ML工作负载来说,单个加速器可能提供了足够的计算性能。然而,由于内存限制,通常需要将工作负载分布到多个加速器上。利用多个加速器可以增加总内存容量,从而完全将大型模型和数据集放入内存。这种策略确保了更大的内存容量,可以在多个硬件加速器上容纳模型的全部权重,从而减轻了从主机系统内存传输数据时所产生的时延。对于某些工作负载来说,增加内存带宽可能对满足时延和吞吐量要求至关重要。
值得注意的是,旨在减少内存占用的技术,比如重新计算激活值利用了计算资源来部分抵消这些限制(Rajbhandari等, 2021)。然而,通过多个芯片并行化模型训练需要它们之间通过互连实现高效通信。
互连带宽
在ML的训练和部署中,由于不断增长的内存需求,除需要巨大的计算能力之外,还需要使用多个芯片来满足这些需求。例如,PaLM的训练中使用了6144个芯片(Chowdhery等人,2022年),而对于GPT-4可能需要使用更多芯片。这一需求强调了有效互连这些芯片的需求,使它们能够在不借助CPU内存或磁盘的情况下有效地交换激活值和梯度。
互连带宽是指通信通道能够传输的峰值比特率,通常以每秒传输的字节数为单位测算。当ML硬件之间频繁交换数据时,如果互连带宽跟不上处理速度,这个指标就成为了限制因素。
互连协议定义了最大互联带宽。在我们的数据集中,ML硬件涉及三种常见协议:a) PCI Express(PCIe);b) Nvidia NVLink;c) Google Inter-Core Interconnect(ICI)[16] 。PCIe是一种普遍采用的协议,用于在CPU和机器学习硬件之间进行本地互联。相比PCIe的基于集线器的网络架构,Nvidia的专有NVLink通过实现设备之间的直接点对点连接,克服了PCIe的带宽限制。在无法使用点对点连接的情况下,PCIe被用作备用方案。Google的ICI用于连接他们的TPU[17]。
前面提到的互连协议主要设计用于近距离通信[18] 。当需要进行较长距离的通信时,会采用传统的计算机网络协议,比如以太网或者InfiniBand。在所有传统网络协议中,数据都是通过PCIe路由到网络硬件[19] 。即使存在NVLink和ICI,PCIe仍然作为主机CPU和机器学习硬件之间的标准互连协议。在接下来的内容中,我们将始终指出对应于最快协议的互连速度。
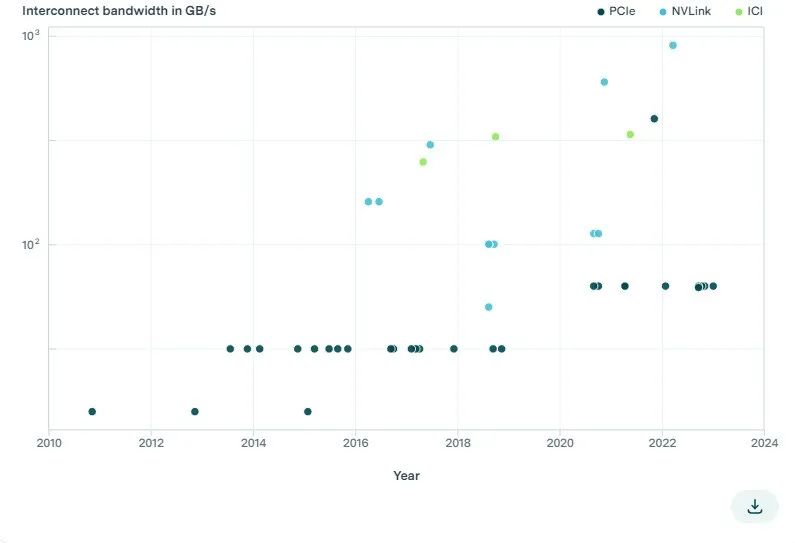
图5: 不同硬件加速器中,每个芯片的聚合互连带宽。NVLink和ICI等专有协议的互连带宽高于PCIe。
我们发现,自2011年以来,ML(机器学习)硬件的PCIe带宽仅从32GB/s增加到2023年的128GB/s(见图5)。[20]然而,英伟达(NVLink)和谷歌(ICI)的专用加速器互连协议可实现更高的互连带宽。此外,常用于大型计算集群的高端ML加速器(例如TPU和V/A/H100)拥有迄今为止最高的互连速度。例如,搭载18个NVLink 4.0通道的英伟达H100实现了900GB/s的带宽,是单个PCIe 5.0 16通道链路的7倍。[21]
一个计算集群可能配备了成千上万台不同程度耦合的硬件加速器。例如,英伟达的DGX H100服务器使用NVSwitch使每台H100互连,从而实现了最大互连带宽为900GB/s的紧密耦合加速器网络(参见[Choquette, 2023],https://doi.org/10.1109/MM.2023.3256796,"Scaling Up and Out"一章)。许多DGX H100服务器又可以组成所谓的SuperPOD,其中各个独立服务器中的加速器仍可使用NVLink传输数据,但耦合程度较低。每个SuperPOD使用以太网和Infiniband连接到另一个SuperPOD。服务器之间的网络拓扑也会影响计算集群的整体性能。
专用集群ML硬件的互连带宽远高于消费级硬件。这凸显了它在大规模ML实验中的重要性,因为这些实验需要在ML硬件节点之间进行高带宽的数据通信。因此,类似于内存容量和带宽,我们建议监测互连带宽,将其作为了解ML硬件趋势的一个相关附加指标。
计算性价比
性能——价格比(Price-performance ratio)通常比单纯的峰值计算性能更有用,它能反映GPU的整体技术改进情况,即每美元成本可获得的性能。我们采用两种方法来估算ML硬件的性价比:
在有数据的情况下,我们使用硬件的发布价格,根据通货膨胀进行调整,并假定两年的摊销时间,详见(Cotra (2020),https://docs.google.com/document/d/1qjgBkoHO_kDuUYqy_Vws0fpf-dG5pTU4b8Uej6)。
在仅提供租赁的TPU或其他硬件等硬件发布价格不可用或不明确的情况下,我们使用Google Cloud的云计算价格(截至2023年7月3日)。我们根据通货膨胀调整价格,以使价格与摊销价格相当,并假设云服务提供商的利润率为40%[22]。如图6所示,在计算FP32精度的性价比时,需考虑估算FP32性价比时的一些重要注意事项。
首先,集群硬件的定价通常会采用私下协商的方式,不公开发布,这使得难以准确定价。其次,尽管某些芯片在个体性价比上表现强劲,但由于互连带宽或可靠性不足,可能无法在工业集群部署中使用。再次,FP32计算引入了对专用ML芯片的偏见,这些芯片使用较低精度数字格式和未在FP32指标中反映的张量核心。最后,由于缺乏有关功耗、冷却和更换率等数量的公开数据(参见[Cottier, 2023],https://epochai.org/blog/trends-in-the-dollar-training-cost-of-machine-learning-systems),估算实际维护成本具有挑战性。尽管作为基准有用,但FP32性价比趋势必须考虑源自ML的特定架构因素和数据约束的限制。

图 6:通用硬件和ML硬件的FP32性价比轨迹。我们发现,这些轨迹大致遵循与峰值计算性能相同的增长轨迹(2.3年翻倍时间)。此外,我们发现ML GPU的绝对性价比低于其他硬件。FP32性价比可能存在对ML硬件的偏见(详见正文)。
我们看到FP32性价比的增长轨迹(2.5/2.1年翻倍时间)大致与通用计算性能的增长轨迹(2.3年翻倍时间)相似。
此外,与其他GPU相比,我们发现ML GPU的性价比较低。我们推测至少有两个原因。
首先,如上所述,由于它们忽略了在ML训练中常见的其他数值表示(如FP16),上述注意事项系统地使FP32性价比对ML硬件产生了偏见。其次,正如前面的部分所述,大规模ML训练不仅依赖于单一性能指标,还依赖于互连带宽、内存容量和带宽等其他指标。然而,这些指标并未反映在FP32性价比中。例如,一款典型的消费级GPU在个体的性价比上可能更好,但对于ML训练来说却不太适用。

图7:不同数值表示ML硬件的计算性价比。其中的点表示ML硬件的发布日期和性能,颜色代表数值格式。虚线表示具有十个或更多加速器的数值格式(如INT8、FP16和FP32)性能改进趋势。
FP32的性价比可能会误导对ML硬件成本效益的认识。例如,AMD Radeon RX 7900 XTX消费级GPU在FP32性价比方面表现最佳。然而,NVIDIA RTX 4090在使用ML训练中常见的低精度INT4格式时,提供了约10倍高的性价比。这得益于RTX 4090专为低精度计算而设计的张量核心,而FP32指标却忽略了这一点。
因此,仅凭FP32的性价比便会错误地认定Radeon优于RTX 4090,而实际上RTX 4090在实际ML工作负载中更为经济实惠。这突显了仅依赖FP32性价比分析,不考虑ML特定架构和数值表示的整体评估的风险。
性价比最好的GPU在很大程度上取决于所使用的数值表示。AMD Radeon RX 7900 XTX消费级GPU在FP32计算上的性价比最高。然而,对于像INT4这样的低精度数字格式,NVIDIA RTX 4090的每美元计算性能大约是Radeon的10倍。这说明按照性价比对GPU进行排名对精度非常敏感,而仅依靠FP32无法全面反映实际ML工作负载中的成本效益。
能效
运行硬件会消耗能源,而大多数组织的目标是尽可能充分地利用他们的硬件。因此,部署能效高的硬件是一种降低硬件加速器寿命周期成本的可能途径。此外,能效更高的硬件通常散热更少,有助于更好地实现可扩展性。
为近似评估ML硬件的能效,我们使用每瓦特的FLOP/s,其中能量组成部分是从热设计功耗(TDP)计算得出的。TDP并不等同于平均能耗,因此不应该用于精确比较。然而,在ML训练和云计算中,我们认为它是一个相当不错的近似值,因为硬件是持续运行的(参见附录中的TDP部分,https://epochai.org/blog/trends-in-machine-learning-hardware#thermal-design-power-tdp)。
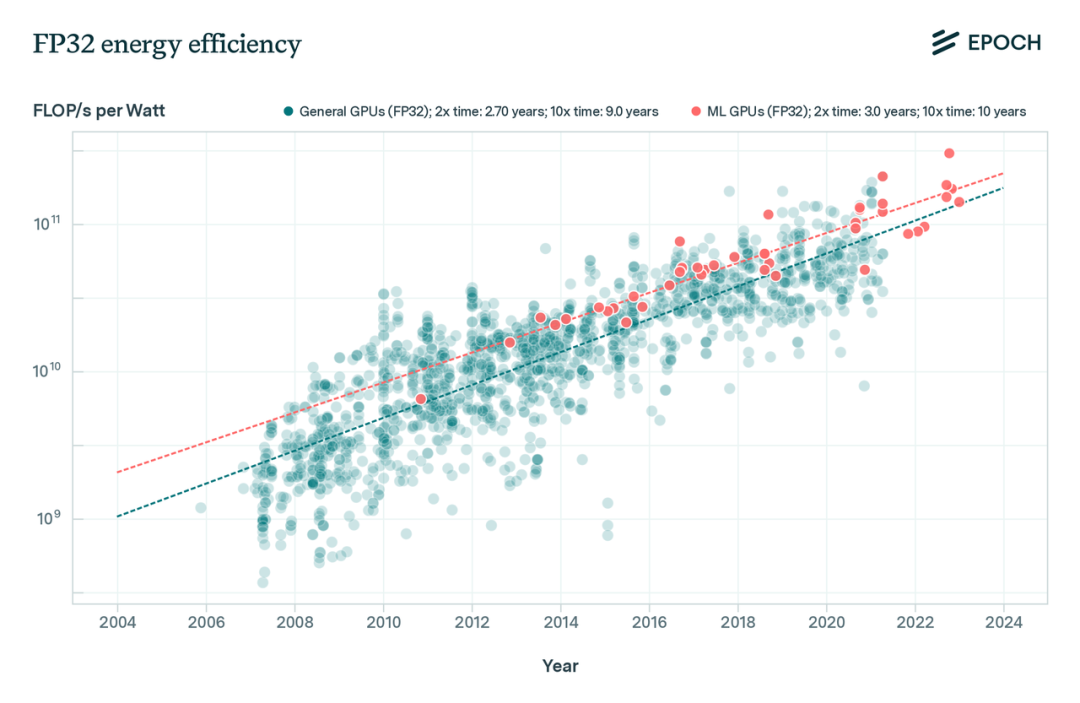
图 8:根据TDP数值计算的FP32精度能效轨迹。我们发现,机器学习GPU的平均能效比通用GPU高,且能效的增长速度略低于峰值计算性能(2.3年翻倍时间)的增长速度。
我们发现,机器学习GPU的平均能效比历史GPU更高。这是合理的,因为ML GPU通常在数据中心运行,能源消耗和碳足迹是重要的度量标准(参见Jouppi等,2023,https://arxiv.org/pdf/2304.01433.pdf,第7.6节)。此外,我们发现能效的增长速率(分别为历史GPU和ML GPU的2.70/3.0年翻番时间)仅略低于峰值计算性能的增长速率(2.3年翻番时间)。这一趋势表明能耗目前(尚)不是扩展的现实瓶颈,但有理由认为在未来可能会成为瓶颈(参见Hobbhahn & Besiroglu, 2022b,https://epochai.org/blog/predicting-gpu-performance)。

结论
最近的研究表明,对于开发和部署ML模型,低精度已经足够(参见[Dettmers 等, 2022];[Suyog Gupta 等, 2015]; [Courbariaux 等, 2014])。我们发现,ML硬件遵循上述发现,并不断集成支持更低精度数值格式的硬件单元(如FP16、TF32、BF16、INT8和INT4),以增加每秒的总操作次数。此外,张量核心等专用计算单元变得越来越普遍,并进一步提高了计算性能。
结合这两个趋势,在我们的推测性占主导的估算中,从FP32到张量-FP16的跃迁平均提供了约8倍的峰值性能增益。然而,旗舰级ML硬件加速器的这一比率可能更高,例如,NVIDIA H100 SXM的TF32到FP32比率约为7倍,张量-FP16到FP32比率约为15倍,张量-INT8到FP32比率约为30倍。
这一趋势表明了一种“硬件-软件协同设计”的模式,其中ML从业者尝试不同的数值表示,并已获得了一些小而有意义的性能提升,减少了内存占用。然后,硬件被调整以适应这些新的数值表示,从而获取进一步的增益。多次迭代这一循环可以促成性能的实质性改善。此外,硬件生产商也在积极寻求新的创新,这些创新随后将引领其进入ML实验室。
此外,在大规模ML训练中,我们强调内存容量、内存带宽和互连带宽等因素的重要性。鉴于目前ML训练通常需要数千个芯片之间的有效交互,超越每个芯片峰值性能的因素变得至关重要。我们观察到,这些指标的增长速度比与计算相关的指标(例如峰值计算性能、性价比和能效)要慢。在大规模分布式ML训练场景中,内存和互连带宽成为利用峰值计算性能的瓶颈。
专门的机器学习硬件和替代的数值表示是相对较新的趋势,这使得精确预测变得困难。正如我们已经明确指出,密切追踪数值格式、内存容量、内存带宽和互连带宽的发展对于更准确地评估未来机器学习能力至关重要。与其依赖静态假设,基于硬件和软件创新不断重新评估性能潜力才是关键。
(我们要感谢Dan Zhang、Gabriel Kulp、Yafah Edelman、 Ben Cottier、Tamay Besirogl和Jaime Sevilla对本文提供的详尽反馈,还要感谢Eduardo Roldán将这篇文章搬运到网站上。)
附录:次要性能指标的趋势
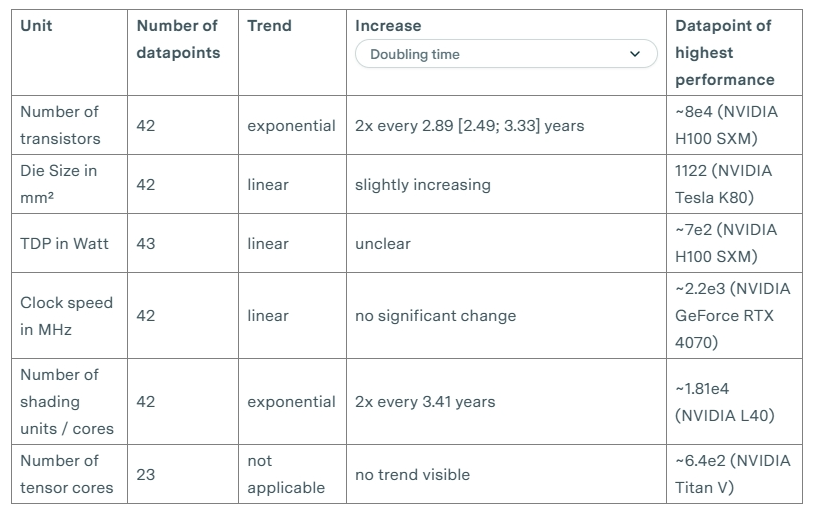
我们补充了晶体管数量、热设计功耗(TDP)、时钟速度、芯片尺寸和张量核心数量等次要指标的趋势。尽管这些指标可能与理解ML硬件的某些趋势相关,但我们认为它们不如我们在文章主体中分析的指标重要或有影响力[23]。
请注意,这些趋势中仍有大量缺失数据,因此可能存在偏见。例如,以下大部分数据不包括TPU。
注释:
1 NA表示数据不可用,因为缺乏足够的数据来估计相关增长率。
2 这些数字通常是基于硬件特性计算得出的。例如,计算性能通常被估算为处理核心数量、时钟速度和每个核心的每个时钟周期的浮点运算乘积。
3 相同位数的比特可以表示不同的数值范围或浮点数精度。我们的硬件数据集不包括针对给定位数格式的每种可用数值格式的计算性能。例如,我们的FP16数据还包括BF16,其在指数和尾数分配的比特数方面存在差异。我们不指望在相同位数的不同浮点数格式之间有太大的性能差异。最适合的数值表示(例如,从能源或运行时间效率的角度)取决于工作负载。[Rodriguez, 2020](https://deeplearningsystems.ai/#ch06/#61-numerical-formats)第6.1节中还包含了一份ML应用的数值表示的综合列表。
4 根据[Mao等人 (2021)](https://doi.org/10.1109/TVLSI.2021.3128435)中的表VI,一个FP64乘法器单元的面积大约是FP32乘法器的五倍。类似的关系也存在于FP32和FP16乘法器之间。
5 由于许多具有历史重要性的超级计算机工作负载对高精度的要求,例如计算流体力学、气象学、核蒙特卡洛模拟、蛋白质折叠等。
6 [Rodriguez, 2020](https://deeplearningsystems.ai/#ch06/#61-numerical-formats), 第6.1节指出:最受欢迎和广泛采用的数值格式是用于训练和推理的FP32。行业正在向用于训练和推理的FP16和BF16靠拢,并在某些工作负载的推理中采用INT8。
7 TF32并非通用数值格式,它仅在NVIDIA张量核心中使用,通过在矩阵乘法之前减少13位精度位,加速使用FP32的模型处理,但保持与FP32相同的数值范围。TF32与FP32的内存占用相同,因为TF32在张量核心中使用与FP32相同的寄存器(参见[Sun等,2022](https://doi.org/10.1109/TPDS.2022.3217824),第8节)。换句话说,TF32被设计为FP32模型的即插即用替代品,但在矩阵乘法过程中可以接受更低的精度。
8 请勿将其与张量核心乘法所需的新指令混淆。[Choquette等人,2021](https://doi.org/10.1109/MM.2021.3061394),SM Core一节指出:在A100中,添加了一条新的异步组合加载-全局存储-共享存储指令,将数据直接传输到SMEM,绕过寄存器文件,提高了效率。
9 注意查看标题为‘SM Core’的部分。
10 例如,目前INT8在训练当前系统中并未被广泛使用。INT8的缺点在Rodriguez,2020,第6.1节中有解释。
11 由ML硬件数据表记录的内存容量通常指的是RAM容量,因为GPU在之前常被用于视频处理,所以也常被称为视频RAM(VRAM)。
12 例如,[AMD Instinct MI200 数据表](https://www.amd.com/system/files/documents/amd-instinct-mi200-datasheet.pdf) 明确说明了128 GB HBM2e。HBM指的是高带宽内存,是一种RAM类型。[NVIDIA H100 Tensor Core GPU 数据表](https://resources.nvidia.com/en-us-tensor-core/nvidia-tensor-core-gpu-datasheet) 表示H100 SXM 的内存为80GB,根据 [NVIDIA H100 Tensor Core GPU 架构](https://nvdam.widen.net/s/95bdhpsgrs#page=36)v1.04,第36页,这个数字对应于HBM3 的内存容量。
13 在应用中,实际带宽通常较低。一个原因是数据传输时延,这也影响了实际带宽,并取决于内存技术。到单独内存芯片的距离以及在大容量内存中的长路径,会导致数据在到达处理单元之前经历大量的周期。如果处理单元预先知道需要哪些数据,就可以以最大带宽进行数据传输。如果不知道,就需要对内存进行随机访问。通常,随机访问越多,实际带宽就越低。我们的数据集中不包含时延指标。
14 图形处理和机器学习训练往往会遇到这个瓶颈,因此,现代机器学习硬件尝试通过两种技术来优化高内存带宽:(a) GDDR内存或(b) 高带宽内存(HBM)。GDDR内存位于与处理芯片相同的板上,而HBM则实现在与处理芯片相同的封装中,从而实现更低的时延和更高的带宽(例如,在数据中心使用的最新机器学习加速器,如NVIDIA A100和H100采用了HBM;而它们的游戏型GPU则没有采用HBM,以节约成本)。将许多DRAM堆叠在一起,并在单个芯片封装中互连多个半导体芯片,与在印刷电路板上连接处理芯片和DRAM相比,需要昂贵的工具,因此HBM通常出现在性能最昂贵和性能最高的机器学习硬件加速器中,例如那些用于数据中心进行大规模机器学习训练和部署的加速器。
15 可参阅 [Megatron-LM: 使用模型并行训练数十亿参数的语言模型](https://lilianweng.github.io/posts/2021-09-25-train-large/),[如何在多个GPU上训练非常大的模型?](https://lilianweng.github.io/posts/2021-09-25-train-large/)或者[训练大型神经网络的技术](https://openai.com/research/techniques-for-training-large-neural-networks) 。
16 [Jouppi等,《TPU v4:一种具有嵌入式硬件支持的光学可重构超级计算机用于机器学习》](https://arxiv.org/pdf/2304.01433.pdf) 的第2节中有详细内容。
17 更多关于ICI的信息请参见[Jouppi等人,2023](https://doi.org/10.48550/arXiv.2304.01433),第2节。值得注意的是,TPUv4使用光开关来满足长距离互连需求。
18 例如,[PCIe 4.0支持长达30厘米](https://www.elektronik-kompendium.de/sites/com/0904051.htm)。根据[Jouppi等,2023](https://doi.org/10.48550/arXiv.2304.01433),第7.2节,Google ICI用于连接1024个TPUv3,但最大长度并未提供。
19 InfiniBand和Ethernet支持的网络带宽低于PCIe,因此它们定义了峰值带宽。
20 按照PCI-SIG协会的标准;预计到2025年将增加到256GB/s。需要注意的是,带宽变化的速度是由协会定义的,而该协会可能在采纳市场的即时需求方面较为缓慢。
21 根据[NVIDIA H100 Tensor Core GPU Architecture, v1.04, p47的说明](https://nvdam.widen.net/s/95bdhpsgrs#page=47):在多GPU IO和共享内存访问中,总带宽达到900GB/秒,新的NVLink提供的带宽是PCIe Gen 5的7倍。... H100包括18条第四代NVLink连接,提供900GB/秒的总带宽...
22 Google Cloud提供一年的37%的使用折扣。因此,我们估计40%是谷歌从正常云计算中获利的合理下限。有关云计算价格的更多考虑可以在https://epochai.org/blog/trends-in-the-dollar-training-cost-of-machine-learning-systems找到。
23 相关性判断结合了作者直觉和我们在先前帖子中的推理。
24 Chiplet是一个将多个芯片集成到一个集成电路/封装中的例子。
25 根据[Hennessy等人,《计算机体系结构》,2017年,第24页](https://www.elsevier.com/books/computer-architecture/hennessy/978-0-12-811905-1)的描述:TDP既不是峰值功率(峰值功率通常要高1.5倍),也不是在特定计算过程中实际消耗的平均功率(平均功率可能更低)。
26支持这一观点的证据来自(Gigabyte术语表,https://www.gigabyte.com/Glossary/tdp):在一个稳定的、企业级的服务器房间或数据中心中,TDP大致等同于计算设备的功耗,因为服务器通常处于最大容量或接近最大容量运行。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
![孟子义#孟子义的随手拍# 巧克力,再胖点我就抱不动你了[doge][doge][doge] ](https://imgs.knowsafe.com:8087/img/aideep/2021/11/1/a6bfc2e83a400270785569a866fac98a.jpg?w=250)





 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675