
GPT4 Turbo的128K上下文是鸡肋?推特大佬斥巨资评测,斯坦福论文力证结论

作者 | 小戏、兔子酱
128K 的上下文长度!?GPT-4 的上下文长度是 32 k,GPT-4 Turbo 直接将上下文长度 x4,128k 的上下文长度完全足够塞进一部中篇小说…… 知识库更新,GPT-4 Turbo 的记忆来到了 2023 年 4 月,它又知道了这半年来发生的大大小小的大事小事…… DALL·E3,文字转语音等等多模态能力向 API 开放…… 每分钟 tokens 上限翻倍…… 更快的推理速度…… 价格直接跳水,降价一半还多…… ……


The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day

当植入位置超过 73k 长度后,GPT-4 Turbo 的性能开始下降; 相对来说,当插入位置在文档深度的 7%~50% 之间时,模型表现不佳; 如果插入位置在文档开头,那么模型总能正确找到答案。
只要问题的答案不是包含在开头,那么 GPT-4 Turbo 并不能保证总能找到答案; 更少的上下文长度=更高的准确性,减少向 GPT-4 Turbo 的输入,总会提升其表现; GPT-4 Turbo 还是偏好于在文档的开头与结尾寻找答案。
My name is {randomCountry} and I have a pet ${randomAnimal}.
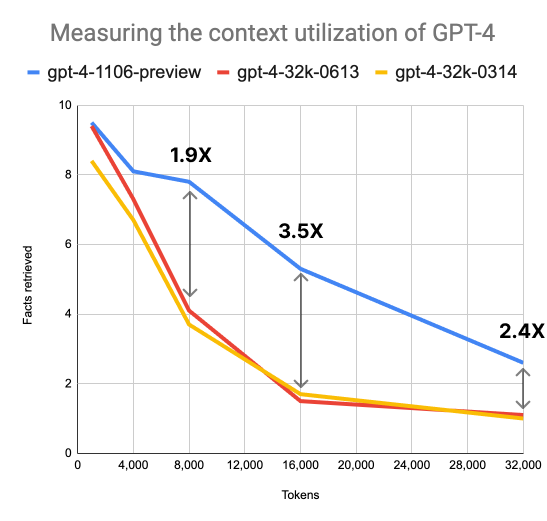

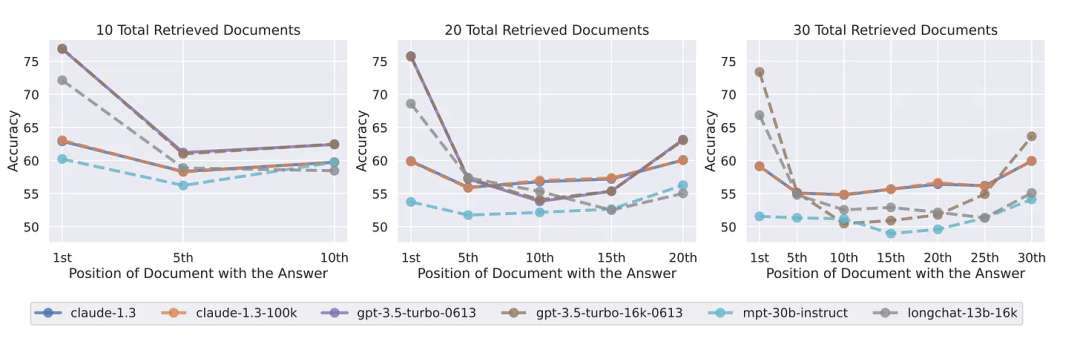
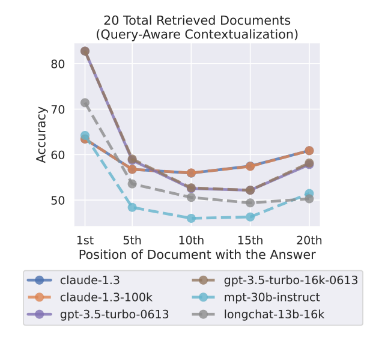
论文题目:Lost in the Middle: How Language Models Use Long Contexts论文链接:https://arxiv.org/pdf/2307.03172.pdf
目前 GPT-4 Turbo 的准确率与上下文长度哪怕是在 128k 的范围内也依然成反比,能利用各种手段少输入一些内容那么就少输入一些内容; 相比于在文档居中的部分,GPT-4 Turbo 还是更加擅长寻找开头与结尾的答案,我们不仅需要充分利用好比如论文摘要、引言与结论的结构化信息,还需要尽量把关键信息放置在上下文窗口的开头或结尾附近; 一般而言,当提供给 GPT-4 Turbo 的文档之间相关性很弱时,也会影响模型的性能,因此尽量给模型输入相关性比较强的内容; 提供更多的任务示例 maybe 相当于为模型提供了一个“便签”,有助于抵消随着上下文长度增加而导致的性能下降。 欢迎评论区的大家伙继续补充哇……



I start to understand why such a thing can make a human 10x human




关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675