
Nature|AI检测器又活了?成功率高达98%,吊打OpenAI

新智元报道
新智元报道
【新智元导读】OpenAI都搞不定的问题,被堪萨斯大学的一个研究团队解决了?他们开发的学术AI内容检测器,准确率高达98%。如果将这个技术再学术圈广泛推广,AI论文泛滥的可能得到有效缓解。
现在AI文本检测器,几乎没有办法有效地区分AI生成的文字和人类的文字。
就连OpenAI开发的检测工具,也因为检测准确率太低,在上线半年后悄悄下线了。

但是最近,Nature报导了堪萨斯大学的一个团队的研究成果,他们开发的学术AI检测系统,能有效分辨论文中是否含有AI生成的内容,准确率高达98%!
文章地址:https://www.nature.com/articles/d41586-023-03479-4
研究团队的核心思路是,不追求制作一个通用的检测器,而只是针对某个具体领域的学术论文,来构建一个真正有用的AI文字检测器。

论文地址:https://www.sciencedirect.com/science/article/pii/S2666386423005015?via%3Dihub
研究人员表示,通过针对特定类型的写作文本定制检测软件,可能是通向开发出通用AI检测器的一个技术路径。
「如果可以快速、轻松地为某个特定领域构建检测系统,那么为不同的领域构建这样的系统就不那么困难了。」

研究人员提取了论文写作风格的20个关键特征,然后将这些特征数据输入XGBoost模型进行训练,从而就能区分人类文本和AI文本。
而这二十个关键特征,包括句子长度的变化、某些单词和标点符号的使用频率等等要素。
研究人员表示「只需使用一小部分特征就能获得很高的准确率」。
正确率高达98%
研究小组之所以选择「引言(Introduction)」部分,是因为如果ChatGPT能够获取背景文献,那么论文的这一部分就相当容易撰写。
研究人员用100篇已发表的引言作为人类撰写的文本对工具进行了训练,然后要求ChatGPT-3.5以ACS期刊的风格撰写200篇引言。
对于GPT-3.5撰写的200篇引言,其中的100篇,提供给了GPT-3.5论文标题来要求撰写,而对于另外100篇,则提供了论文摘要作为写作的依据。
最后,让检测器对同一期刊上由人类撰写的引言和由人工智能生成的引言进行测试时。
检测器识别出ChatGPT-3.5基于标题撰写的引言部分的准确率为 100%。对于基于摘要撰写的ChatGPT生成的引言,准确率略低,为 98%。
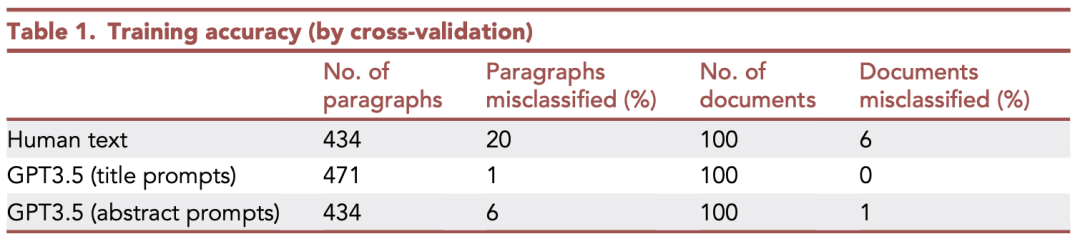
该工具对GPT-4撰写的文本也同样有效。

相比之下,通用AI检测器ZeroGPT识别AI撰写的引言的准确率只有35-65%左右,准确率取决于所使用的ChatGPT版本以及引言是根据论文标题还是摘要生成的。

由OpenAI制作的文本分类器工具(论文发表之时,OpenAI已经把这个检测器下架了)也表现不佳,它能识别AI撰写的引言的准确率只有10-55%。
这个新的ChatGPT检测器甚至在处理未经过训练的期刊时也有很出色的表现。
它还能识别出专门为了迷惑AI检测器的提示生成的AI文本。
不过,虽然这个检测系统对于科学期刊论文来说性能非常好,当被用来检测大学报纸上的新闻文章时,识别效果就不太理想了。

柏林应用科学大学(HTW Berlin University of Applied Sciences)研究学术剽窃的计算机科学家Debora Weber-Wulff给予了这个研究非常高度的评价,他认为研究人员正在做的事情 「非常吸引人」。
论文细节
提取的 20 个特征包括 :
(1) 每段落的句子数、(2) 每段落的单词数、(3) 是否存在括号、(4) 是否存在破折号、(5) 是否存在分号或冒号,(6)是否存在问号,(7)是否存在撇号,(8)句子长度的标准偏差,(9)段落中连续句子的(平均)长度差异,(10 ) 存在少于 11 个单词的句子,(11) 存在超过 34 个单词的句子,(12) 存在数字,(13) 文本中存在两倍以上的大写字母(与句点相比)段落,并且存在以下词语:(14)虽然,(15)但是,(16)但是,(17)因为,(18)这个,(19)其他人或研究人员,(20)等。
具体通过XGBoost训练检测器的详细过程可以参见论文原文中的Experimental Procedure部分。
作者在之前做过一篇类似的工作,但原始工作的范围非常有限。
为了将这种有前途的方法应用于化学期刊,需要根据该领域多个期刊的各种手稿进行审查。
此外,检测AI文本的能力受到提供给语言模型的提示的影响,因此任何旨在检测AI写作的方法都应该针对可能混淆AI使用的提示进行测试,之前的研究中没有评估这个变量。
最后,新版的ChatGPT即GPT-4已经推出,它比GPT-3.5有显著改进。AI文本检测器需要对来自GPT-4等新版本的语言模型的文本有效。
为了扩大了AI检测器的适用范围,这里的数据收集来自13个不同期刊和3个不同出版商、不同的AI提示以及不同的AI文本生成模型。
使用真实人类的文本和AI生成的文本训练XGBoost分类器。然后通过真人写作、 AI提示以及GPT-3.5和GPT-4等方式来生成新的范例用于评估模型。
结果表明,本文提出的这种简单的方法非常有效。它在识别AI生成的文本方面的准确率为98%–100%,具体取决于提示和模型。相比之下,OpenAI最新的分类器的准确率在10% 到56% 之间。
本文的检测器将使科学界能够评估ChatGPT对化学期刊的渗透,确定其使用的后果,并在出现问题时迅速引入缓解策略。
结果与讨论
包括《无机化学》、《分析化学》、《物理化学杂志A》、《有机化学杂志》、《ACS Omega》、《化学教育杂志》、《ACS Nano》、《环境科学与技术》、《毒理学化学研究》和《ACS化学生物学》。
使用每个期刊中10篇文章的引言部分,训练集中总共有100个人类写作样本。选择介绍部分是因为在适当的提示下,这是最有可能由ChatGPT撰写的文章的部分。
每个期刊仅使用10篇文章是一个异常小的数据集,但作者认为这并不是一个问题,恰恰相反,假设可以使用如此小的训练集开发有效的模型,则可以使用最小的计算能力快速部署该方法。
而之前类似的模型使用了1000万份文档进行模型训练。
提示设计是这些研究中的一个关键方面。对于每个人类编写的文本,AI比较器都会使用两种不同的提示生成,这两种提示都旨在要求ChatGPT像化学家一样写作。
提示1是:「请以ACS期刊的风格为标题为xxx的文章写一篇300到400字的简介」。
提示2是:「请以ACS期刊的风格为带有此摘要的文章写一篇300到400字的简介」。
正如预期的那样,ChatGPT将摘要中的许多关键事实和词汇纳入了本集中的介绍中。
整个训练数据集包含100个人工生成的介绍和200个ChatGPT生成的介绍;每个段落都成为一个「写作示例」。
从每个段落中提取了20个特征的列表,这些特征涉及段落的复杂性、句子长度的变化、各种标点符号的使用以及在人类科学家或ChatGPT著作中可能更频繁出现的「流行词」。
该模型使用留一法交叉验证策略(leave-one-out cross-validation strategy)进行优化。

上表显示了这些写作样本分类的训练结果,包括完整文档级别和段落级别。
最容易正确分类的文本类别是在提示1(标题)之下由ChatGPT生成的介绍。
该模型在单个段落级别的准确率是99%,在文档级别的准确率是100%。
而在提示2(摘要)作用下的ChatGPT文本的分类精度略低。
人类生成的文本更难正确分配,但准确性仍然相当不错。作为一个群体,人类的写作风格比ChatGPT更加多样化,这可能导致使用这种方法正确分类其写作样本的难度增大。
实验的下一阶段是使用训练中未使用的新文档来测试模型。
作者设计了简单测试和困难测试。
简单测试使用的测试数据与训练数据性质相同(选取同一期刊的不同文章),使用新选择的文章标题和摘要来提示ChatGPT。
而在困难测试中,使用GPT-4代替GPT-3.5来生成AI文本,由于已知GPT-4比GPT-3.5更好,那么分类精度是否会下降呢?

上面的表格显示了分类的结果。与之前的结果相比,性能几乎没有下降。
在完整文档级别,人工生成文本的分类准确率达到94%,提示2的AI生成文本准确率为98% , 提示1的AI文本分类正确率达到100%。
训练集和测试集对于段落级别的分类精度也非常相似。
底部的数据显示了使用GPT-3.5文本特征训练的模型对GPT-4文本进行分类时的结果。所有类别的分类准确性都没有下降,这是一个非常好的结果,证明了方法在GPT-3.5和GPT-4上的有效性。
虽然这种方法的整体准确性值得称赞,但最好通过将其与现有的人工智能文本检测器进行比较来判断其价值。这里使用相同的测试集数据测试了两种效果领先的检测工具。
第一个工具是ChatGPT的制造商OpenAI提供的文本分类器。OpenAI承认该分类器并不完美,但仍然是他们最好的公开产品。
第二个检测工具是ZeroGPT。其制造商声称检测人工智能文本的准确率达到98%,并且该工具接受了1000万份文档的训练。在目前的许多评估中,它是性能最好的分类器之一。而且,ZeroGPT制造者表示他们的方法对GPT-3.5和GPT-4都有效。
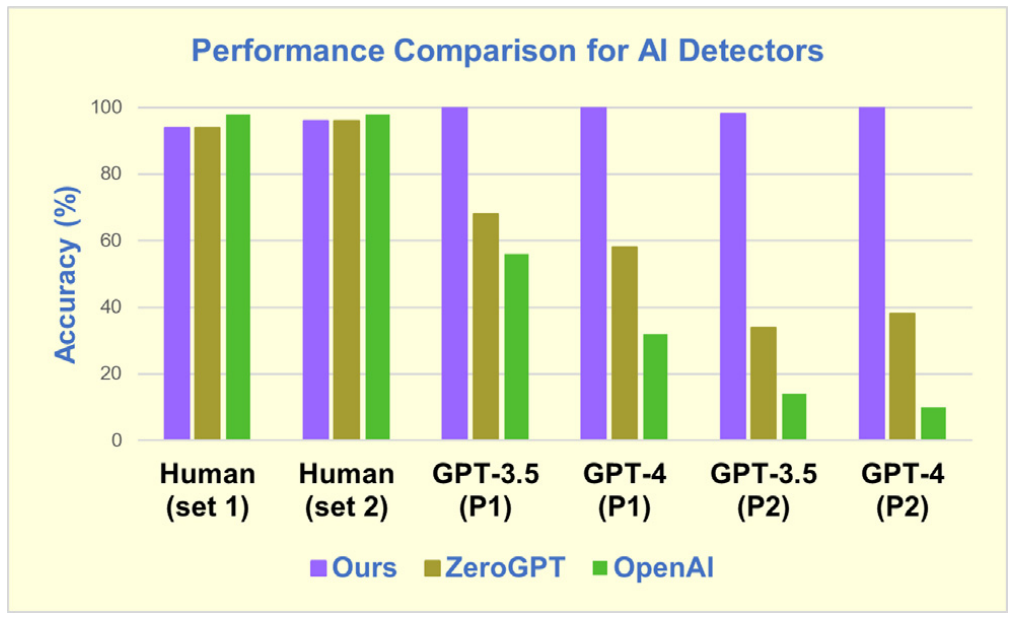
上图显示了本文的工具和上述两个产品在完整文档级别的性能比较。
三个检测器在人类文本的识别上都有着相似的高精度;然而,在评估AI生成的文本时,三个工具存在显著差异。
在使用提示1的情况下,本文的工具对GPT-3.5和GPT-4都有100% 的准确率,但ZeroGPT对于GPT-3.5文本的失败率为32%,对于GPT-4文本的失败率为42%。OpenAI产品的表现更差,在GPT-4文本上的失败率接近70%。
在使用更难的提示2生成的AI文本时,后两种方法的分类正确率进一步下降。
相比之下,本文的检测器在该组测试的100个文档中只犯了1个错误。
那么,该方法能否准确检测不属于训练集的期刊中的ChatGPT写作,以及如果使用不同的提示,该方法仍然有效吗?
作者从三个期刊中选出了150篇新文章的介绍:Cell Reports Physical Science,Cell Press期刊;Nature Chemistry,来自自然出版集团;以及Journal of the American Chemical Society,这是一份未包含在训练集中的ACS期刊。
此外,还收集了由大学生于2022年秋季撰写并发表在10种不同大学报纸上的一组100篇报纸文章。由于本文的检测器是专门针对科学写作而优化的,因此可以预计新闻报道不会被高精度地分类。

从图中可以看到,应用相同的模型,并使用ACS期刊的文本对这组新示例进行训练后,正确分类率为92%–98%。这与训练集中得到的结果类似。
也正如预期的那样,大学生撰写的报纸文章没有被正确归类为人类生成的文章。
事实上,当使用本文描述的特征和模型进行评估时,几乎所有文章都比人类科学文章更类似于人工智能生成的文本。
但是本方法旨在处理科学出版物上的检测问题,并不适合将其扩展到其他领域。



关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675