

刚刚过去的22年被媒体誉为“AIGC元年”,这一年中AI绘画和 chatGPT相继引爆了全球科技界,成为人工智能领域的两大里程碑事件,特别是 chatGPT的推出,又重新点燃了人们对通用人工智能 AGI的新一轮期待,chatGPT所表现出来的前所未有的逻辑能力和推理能力,让众多AI领域的专家和研究人员不禁为之赞叹。与此同时,更多的企业和机构也开始尝试将 chatGPT应用于自己的业务中,希望通过人工智能的力量来提升工作效率和解决难题。chatGPT是基于 GPT3.5开发的纯文本单模态的语言模型,对于它的下一代更新,我们之前猜测除了文本能力的继续提升外,从单模态过渡到多模态将是更为关键的一点,今年3月15日 GPT4的推出,证实了我们的推测:GPT4做为新一代的 GPT模型,增加了对视觉模态输入的支持,这意味着它能够理解图像并进行相应的自然语言生成。增加了多模态能力的 GPT4也带来了应用层面的更多可能,比如在电商领域中,商家可以将产品图像输入 GPT4进行描述生成,从而为消费者提供更加自然的商品介绍;在娱乐领域中,GPT4可以被用于游戏设计和虚拟角色创造,为玩家带来更加个性化的游戏体验和互动快乐。视觉能力一向被视为一个通用人工智能 AGI智能体所需必备的基础能力,而 GPT4则向人们生动展示了融合视觉能力的 AGI的雏形。
实际上 GPT4并不是第一个将视觉与文本模态相融合的工作,CV、NLP以及机器人等领域的科研人员长久以来一直在探寻各种方法将多个不同模型的信息相融合的方法,像 VQA、Visual Captioning、Visual Grounding等都已经是多模态下细分的专业研究领域。具体到将视觉能力融入语言模型 LLM的 MLLM(Multimodal Large Language Model),相关的研究路线主要分为两条:一条是原生多模态路线,模型设计从一开始就专门针对多模态数据进行适配设计,代表性的工作有 MSRA的KOSMOS-1[1]和 Google Robotics的 PALM-E[2],均在今年3月份公开;另一条是单模态专家模型缝合路线,通过桥接层将预训练的视觉专家模型与预训练的语言模型链接起来,代表性的工作有 Deepmind的Flamingo[3],Saleforce的BLIP-2[4],以及近期的 LLAVA[5]和 miniGPT4[6]等工作。 
以 KOSMOS-1和 PALM-E为代表的原生多模态路线,模型结构主体均为Transformer堆叠。下图为 KOSMOS-1的模型结构和训练方案,其中除了image encoder部分使用的是预训练的 CLIP ViT-L/14外,模型主体 MLLM部分是24层的 Transformer堆叠,使用原生的多模态数据从头训练。多模态数据由三部分组成:a)纯文本,以 Pile和 Common Crawl为主;b)image-text pair数据,以 LAION-2B,LAION-400M,COYO-700M, and Conceptual Captions为主;c)图文混合数据(Interleaved Image-Text Data),包含71M页图文网页数据。通过将 image embedding以如下格式与 text embedding相连缀:<s><image>Image Embedding </image>WALL-E giving potted plant to EVE. </s>
KOSMOS-1用自回归loss对图文数据进行统一建模。
PALM-E与 KOSMOS-1相比,模型结构和对多模态数据的建模方式基本相同,下图3为 PALM-E的模型结构和训练方案,其中为机器人的状态估计向量。与 KOSMOS-1相比最大的不同在于,PALM-E使用单模态语言模型PALM的权重对模型进行了初始化。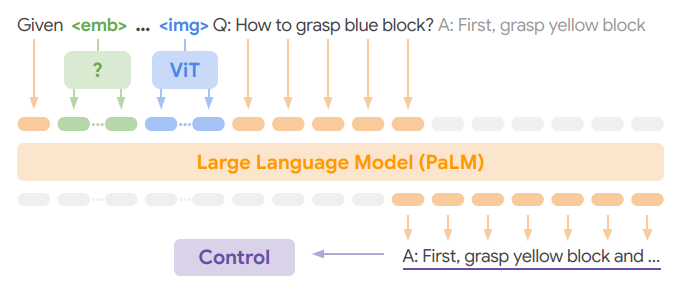
原生多模态路线的优势在于,模型结构原生适配多模态数据,在数据量充足的情况下效果优秀,相关领域的经验也表明这种方式的性能上限更高,但缺点也很明显,不能充分复用各个单模态领域的已有成果,训练需要的计算资源和数据资源都非常大。与原生多模态路线相对的,以 Flamingo、BLIP-2、LLAVA/miniGPT4为代表的单模态专家模型缝合路线,从一开始模型的设计思路就是尽可能复用各个单模态领域的已有成果特别是近期发展迅速的 LLM的预训练模型。Flamingo是 Deepmind在22年11月发表的工作,在 freeze住 vision encoder和LM的基础上,通过在 LM中插入多个 cross-attention层来实现视觉信息与文本信息的对齐和联合学习。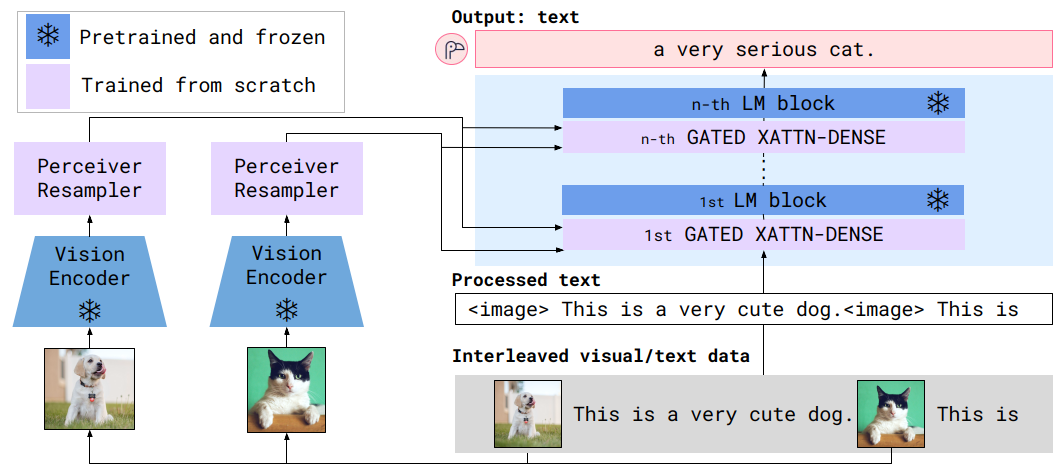
与 KOSMOS-1相比,Flamingo这种缝合方案充分利用了 CV领域和 NLP领域的已有成果,vision encoder和 LM均不需要训练,只需要对做为不同模态信息之间做为桥接的 cross-attention层(图4中的 GATED XATTN-DENSE)进行训练,因此至少在模型训练成本上就有很明显的优势。而23年1月 salesforce发表的 BLIP-2工作以及后续衍生的 LLAVA、miniGPT4等工作则将这一思路进一步简化到 vision encoder和 LM之间只通过单个桥接层进行链接,下图5是 BLIP-2的模型结构,其中视觉侧和文本侧分别使用预训练的 CLIP ViT-G/14模型和 FLAN-T5模型,仅中间的起桥接作用的 Q-Former参与训练,训练需要的成本和数据量进一步降低,BLIP-2的训练数据量仅129M,16卡A100训练9天。后来的 LLAVA工作更是将这一思路简化到极致,仅通过一个 projection layer将 CLIP ViT-L/14和 Vicuna语言模型缝合在一起,训练数据仅用了595K图文对以及158K指令微调数据。miniGPT4则是在复用 BLIP-2的 vision encoder + Q-Former的基础上,通过一层 project layer缝合了 Vicuna语言模型,训练数据仅用了5M的图文对数据+3.5K的指令微调数据。
与原生多模态路线相比,单模态专家模型缝合路线最明显的优势是可以充分复用各个单模态领域的已有成果,成本低,见效快,有研究人员猜测 GPT4可能也是基于缝合路线实现的视觉理解能力。但基于缝合路线的缺陷也显而易见,尤其像 BLIP-2、LLAVA、miniGPT4这样简单的浅层融合方案,最终训练得到的MLLM模型能力通常只能做单轮或多轮对话,不具备像 Flamingo这种深层融合方案以及 KOSMOS-1、PALM-E等原生多模态方案所展现出的多模态 in-context learning能力。
SEEChat项目(https://github.com/360CVGroup/SEEChat)的重点是将视觉能力与已有的 LLM模型相融合,打造侧重视觉能力的多模态语言模型 MLLM。在多模态能力的实现路线上,我们选择了能够充分复用不同领域已有成果的单模态专家模型缝合路线(Single-modal Experts Efficient integration),这也是 SEEChat项目的命名来源。SEEChat v1.0的模型结构如下图6所示,通过 projection layer桥接层,将vision encoder: CLIP-ViT-L/14与开源的中文 LM:chatGLM6B缝合到一起。
SEEChat v1.0的训练分为两个阶段:第一阶段是图文对齐训练,使用我们之前开源的高质量中文图文对数据集 Zero[7],总共2300万样本进行训练;第二阶段是人机对齐训练,使用 miniGPT4+LLAVA开源的指令微调数据经英-中翻译后,对第一阶段训练好的模型进行指令微调。下图7~9是关于 SEEChat v1.0在图文对话、代码生成和目标分类能力的简单展示。可以看到,SEEChat一方面继承了 chatGLM语言模型在对话方面的能力(当然也继承了其缺点),另一方面表现出了令人印象深刻的图文对齐和视觉理解能力。


SEEChat并不是第一个开源的中文多模态对话模型,同期5月份,已经有中科院自动化所的 X-LLM[8]和清华 KEG组的 VisualGLM[9]相继开源。与之相比,SEEChat v1.0不论在路线选择还是模型结构上与前述两个工作大体相同,只在模型细节和训练数据与方法上存在不同。我们认为,对于当前的浅层融合方案,一个很关键的点在于训练用的数据质量而不是数量。我们在 image captioning任务上将 SEEChat v1.0与相关的多个工作进行了对比:从中文Zero数据集中随机选取1000张中文互联网图像,已排除训练集数据
使用ChineseCLIP[10]计算图文相关性得分(为避免训练数据重叠带来的偏置,我们没有使用自己训练的R2D2中文跨模态模型,而是选取了第三方训练的跨模态模型进行图文相关性得分的评价)
上图为七种公开方法(我们将数据原生的互联网文本做为其中一种方法看待)的图文相关性得分胜出情况
可以看到,使用高质量图文数据集 Zero训练的 SEEChat v1.0,胜出率甚至大比例超过原生文本。
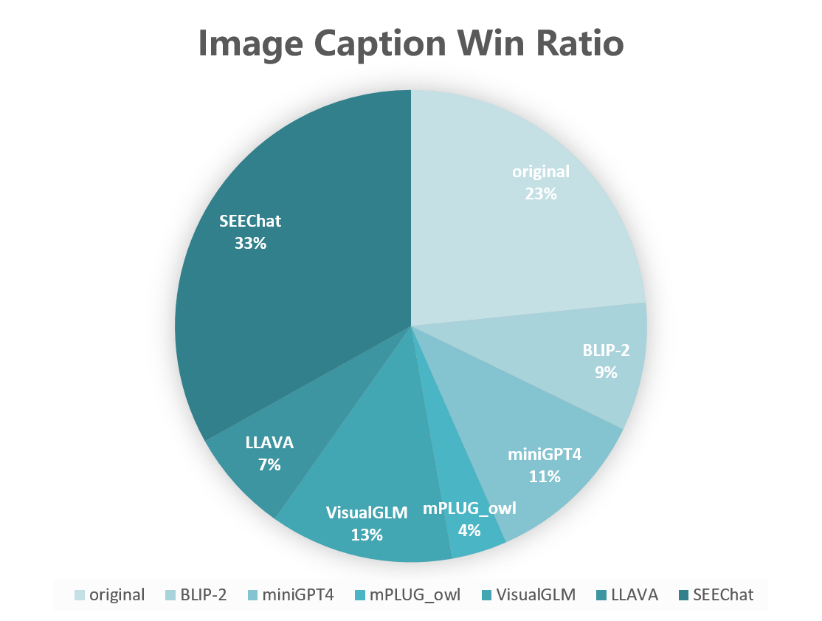
图10 不同模型在Image Captioning任务上的对比
SEEChat项目包含两个版本:内部闭源版本使用企业内部数据训练,主打业务生产力;外部开源版本使用公开数据训练,主打能力展示和社区影响。目前 SEEChat v1.0的内部版本已在集团内部业务落地,并在5月31日以“360智脑-CV多模态大模型”的品牌对外发布。如前所述,SEEChat项目的重点是将视觉能力与已有的 LLM模型相融合,打造侧重视觉能力的多模态语言模型 MLLM,v1.0验证了基础的图文对齐和视觉理解能力,接下来我们将逐步为 MLLM添加目标检测能力、跨模态能力以及开放词表的目标检测与识别能力,模态融合方案也将从浅层融合向深层融合过渡,敬请期待。360 人工智能研究院隶属于 360 技术中台。自 2015 年成立以来积累了大量人工智能与机器学习前沿能力,范围包括但不限于自然语言理解、机器视觉与运动、语音语义交互等方面,技术水平行业领先,核心成员和团队多次荣获 AI 相关比赛冠军 / 提名奖项,发表顶会、顶刊论文数十篇。业务落地方面,研究院提供智能安全大数据、互联网信息分发、企业数字化、AIoT、智能汽车等 360 集团全量业务场景支持,支持千万级硬件设备,亿级用户,产生千亿规模数据量。2023 年着重攻坚大语言模型、CV 大模型和多模态大模型,为 360 集团和行业 AIGC 技术发展应用提供底层技术支撑。冷大炜:360视觉引擎部负责人,带领CV团队在大模型+zero/few shot以及多模态+跨模态方向展开研发工作。[1] Huang, Shaohan, et al. "Language is not all you need: Aligning perception with language models." arXiv preprint arXiv:2302.14045 (2023).[2] Driess, Danny, et al. "Palm-e: An embodied multimodal language model." arXiv preprint arXiv:2303.03378 (2023).[3] Alayrac, Jean-Baptiste, et al. "Flamingo: a visual language model for few-shot learning." Advances in Neural Information Processing Systems 35 (2022): 23716-23736.[4] Li, Junnan, et al. "Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models." arXiv preprint arXiv:2301.12597 (2023).[5] Liu, Haotian, et al. "Visual instruction tuning." arXiv preprint arXiv:2304.08485 (2023).[6] Zhu, Deyao, et al. "Minigpt-4: Enhancing vision-language understanding with advanced large language models." arXiv preprint arXiv:2304.10592 (2023).[7] Zero, https://zero.so.com/[8] Chen, Feilong, et al. "X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages." arXiv preprint arXiv:2305.04160 (2023).[9] VisualGLM, https://github.com/THUDM/VisualGLM-6B[10] ChineseCLIP, https://github.com/OFA-Sys/Chinese-CLIP推荐阅读:
▶技术规模化、复杂化?看作业帮如何利用OpenCloudOS解决技术难题!
▶30 岁“古董”电脑,因 ChatGPT 被迫“复工”:在 Windows 3.1 里用上 ChatGPT!
▶AI 正在杀死旧 Web?
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/


![萱萱Cecillia等一双温柔眼睛,河岸边洒满了婆娑的树影[微风] ](https://imgs.knowsafe.com:8087/img/aideep/2023/11/24/d49ee5b9581ed6aa36358a8945db0cca.jpg?w=250)




 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




