
日增百亿数据,查询结果秒出,Apache Doris 在 360商业化的统一 OLAP 应用实践

360 商业化为助力业务团队更好推进商业化增长,实时数仓共经历了三种模式的演进,分别是 Storm + Druid + MySQL 模式、Flink + Druid + TIDB 的模式 以及 Flink + Doris 的模式,基于 Apache Doris 的新一代架构的成功落地使得 360 商业化团队完成了实时数仓在 OLAP 引擎上的统一,成功实现广泛实时场景下的秒级查询响应。本文将为大家进行详细介绍演进过程以及新一代实时数仓在广告业务场景中的具体落地实践。
作者|窦和雨、王新新,360商业化数据团队
360 公司致力于成为互联网和安全服务提供商,是互联网免费安全的倡导者,先后推出 360 安全卫士、360 手机卫士、360 安全浏览器等安全产品以及 360 导航、360 搜索等用户产品。
360 商业化依托 360 产品庞大的用户覆盖能力和超强的用户粘性,通过专业数据处理和算法实现广告精准投放,助力数十万中小企业和 KA 企业实现价值增长。360 商业化数据团队主要是对整个广告投放链路中所产生的数据进行计算处理,为产品运营团队提供策略调整的分析数据,为算法团队提供模型训练的优化数据,为广告主提供广告投放的效果数据。

业务场景
在正式介绍 Apache Doris 在 360 商业化的应用之前,我们先对广告业务中的典型使用场景进行简要介绍:
实时大盘:实时大盘场景是我们对外呈现数据的关键载体,需要从多个维度监控商业化大盘的指标情况,包括流量指标、消费指标、转化指标和变现指标,因此其对数据的准确性要求非常高(保证数据不丢不重),同时对数据的时效性和稳定性要求也很高,要求实现秒级延迟、分钟级数据恢复。
广告账户的实时消费数据场景:通过监控账户粒度下的多维度指标数据,及时发现账户的消费变化,便于产品团队根据实时消费情况推动运营团队对账户预算进行调整。在该场景下数据一旦出现问题,就可能导致账户预算的错误调整,从而影响广告的投放,这对公司和广告主将造成不可估量的损失,因此在该场景中,同样对数据准确性有很高的要求。目前在该场景下遇到的困难是如何在数据量比较大、查询交叉的粒度比较细的前提下,实现秒级别查询响应。
AB 实验平台:在广告业务中,算法和策略同学会针对不同的场景进行实验,在该场景下,具有报表维度不固定、多种维度灵活组合、数据分析比较复杂、数据量较大等特点,这就需要可以在百万级 QPS 下保证数据写入存储引擎的性能,因此我们需要针对业务场景进行特定的模型设计和处理上的优化,提高实时数据处理的性能以及数据查询分析的效率,只有这样才能满足算法和策略同学对实验报表的查询分析需求。

实时数仓演进
该阶段的实时数仓是基于 Storm + Druid + MySQL 来构建的,Storm 为实时处理引擎,数据经 Storm 处理后,将数据写入 Druid ,利用 Druid 的预聚合能力对写入数据进行聚合。

面对数据量的持续增长,数据仓库压力空前剧增,已无法满足实时数据的时效性要求。 MySQL 的分库分表维护难度高、投入成本大,且 MySQL 表之间的数据一致性无法保障。
第二代架构

架构痛点:
Flink + TIDB 无法实现端到端的一致性,原因是当其面对大规模的数据时,开启事务将对 TiDB 写入性能造成很大的影响,该场景下 TiDB 的事务形同虚设,心有余而力不足。 Druid 不支持标准 SQL ,使用有一定的门槛,相关团队使用数据时十分不便,这也直接导致了工作效率的下降。 维护成本较高,需要维护两套引擎和两套查询逻辑,极大增加了维护和开发成本的投入。
新一代实时数仓架构
第二次升级我们引入 Apache Doris 结合 Flink 构建了新一代实时数仓架构,借鉴离线数仓分层理念对实时数仓进行分层构建,并统一 Apache Doris 作为数仓 OLAP 引擎,由 Doris 统一对外提供服务。


基于 Apache Doris 高性能、极简易用、实时统一等诸多特性,助力 360 商业化成功构建了新一代实时数仓架构,本次升级不仅提升了实时数据的复用性、实现了 OLAP 引擎的统一,而且满足了各大业务场景严苛的数据查询分析需求,使得整体实时数据流程架构变得简单,大大降低了其维护和使用的成本。我们选择 Doris 作为统一 OLAP 引擎的重要原因大致可归结为以下几点:
物化视图:Doris 的物化视图与广告业务场景的特点契合度非常高,比如广告业务中大部分报表的查询维度相对比较固定,利用物化视图的特性可以提升查询的效率,同时 Doris 可以保证物化视图和底层数据的一致性,该特性可帮助我们降低维护成本的投入。
数据一致性:Doris 提供了 Stream Load Label 机制,我们可通过事务的方式与 Flink 二阶段提交进行结合,以保证幂等写入数据,另外我们通过自研 Flink Sink Doris 组件,实现了数据的端到端的一致性,保证了数据的准确性。
SQL 协议兼容:Doris 兼容 MySQL 协议,支持标准 SQL,这无论是对于开发同学,还是数据分析、产品同学,都可以实现无成本衔接,相关同学直接使用 SQL 就可以进行查询,使用门槛很低,为公司节省了大量培训和使用成本,同时也提升了工作效率。
优秀的查询性能:Apache Doris 已全面实现向量化查询引擎,使 Doris 的 OLAP 性能表现更加强悍,在多种查询场景下都有非常明显的性能提升,可极大优化了报表的询速度。同时依托列式存储引擎、现代的 MPP 架构、预聚合物化视图、数据索引的实现,在低延迟和高吞吐查询上,都达到了极速性能
运维难度低:Doris 对于集群和和数据副本管理上做了很多自动化工作,这些投入使得集群运维起来非常的简单,近乎于实现零门槛运维。

Apache Doris 目前广泛应用于 360 商业化内部的多个业务场景。比如在实时大盘场景中,我们利用 Doris 的 Aggregate 模型对请求、曝光、点击、转化等多个实时流进行事实表的 Join ;依靠 Doris 事务特性保证数据的一致性;通过多个物化视图,提前根据报表维度聚合数据、提升查询速度,由于物化视图和 Base 表的一致关系由 Doris 来维护保证,这也极大的降低了使用复杂度。比如在账户实时消费场景中,我们主要借助 Doris 优秀的查询优化器,通过 Join 来计算同环比......
各维度之间组合灵活度很高,例如需要对从 DSP 到流量类型再到广告位置等十几个维度进行分析,完成从请求、竞价、曝光、点击、转化等几十个指标的完整流量漏斗。 数据量巨大,日均流量可以达到百亿级别,峰值可达百万 OPS(Operations Per Second),一条流量可能包含几十个实验标签 ID。

数据落地
当面对一条流量可能包含几十个实验标签 ID 的情况时,从分析角度出发,只需要选中一个实验标签和一个对照实验标签进行分析;而如果通过 like 的方式在几十个实验标签中去匹配选中的实验标签,实现效率就会非常低。
最初我们期望从数据入口处将实验标签打散,将一条包含 20 个实验标签的流量拆分为 20 条只包含一个实验标签的流量,再导入 Doris 的聚合模型中进行数据分析。而在这个过程中我们遇到一个明显的问题,当数据被打散之后会膨胀数十倍,百亿级数据将膨胀为千亿级数据,即便 Doris 聚合模型会对数据再次压缩,但这个过程会对集群造成极大的压力。因此我们放弃该实现方式,开始尝试将压力分摊一部分到计算引擎,这里需要注意的是,如果将数据直接在 Flink 中打散,当 Job 全局 Hash 的窗口来 Merge 数据时,膨胀数十倍的数据也会带来几十倍的网络和 CPU 消耗。

数据一致性保障
数据的准确性是 AB 实验平台的基础,当算法团队呕心沥血优化的模型使广告效果提升了几个百分点,却因数据丢失看不出实验效果,这样的结果确实无法令人接受,同时这也是我们内部不允许出现的问题。那么我们该如何避免数据丢失、保障数据的一致性呢?
自研 Flink Sink Doris 组件

在 Flink 中做到数据端到端的一致性有两种方式,一种为通过至少一次结合幂等写,一种为通过恰好一次的二阶段事务。
应用展示
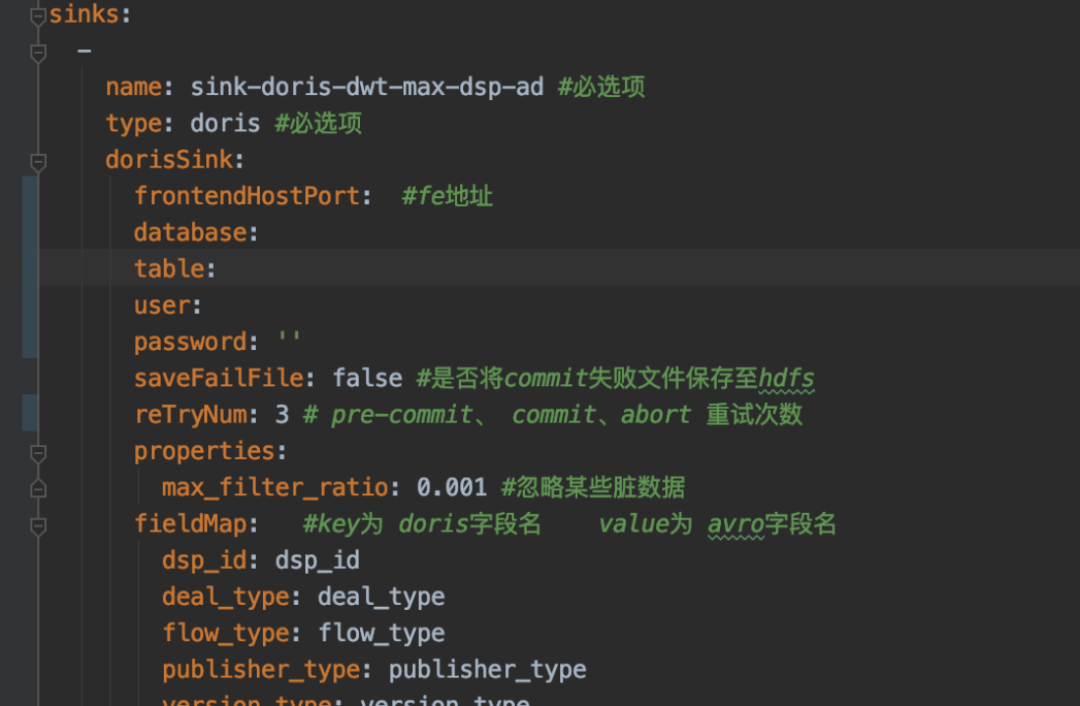

集群监控
在集群监控层面,我们采用了社区提供的监控模板,从集群指标监控、主机指标监控、数据处理监控三个方面出发来搭建 Doris 监控体系。其中集群指标监控和主机指标监控主要根据社区监控说明文档进行监控,以便我们查看集群整体运行的情况。除社区提供的模板之外,我们还新增了有关 Stream Load 的监控指标,比如对当前 Stream Load 数量以及写入数据量的监控,如下图所示:



总结与规划
目前 Apache Doris 主要应用于广告业务场景,已有数十台集群机器,覆盖近 70% 的实时数据分析场景,实现了全量离线实验平台以及部分离线 DWS 层数据查询加速。当前日均新增数据规模可以达到百亿级别,在大部分实时场景中,其查询延迟在 1s 内。同时,Apache Doris 的成功落地使得我们完成了实时数仓在 OLAP 引擎上的统一。Doris 优异的分析性能及简单易用的特点,也使得数仓架构更加简洁。
开源技术论坛:http://forum.selectdb.com/
推荐阅读:
▶百度也要造手机了,小度科技确认发布AI智能手机;iPhone 16 Pro将采用固态按键;Wasmer 3.3发布|极客头条
▶对话凯文·凯利:AI 会取代人的 90% 技能,并放大剩余的 10%
▶Orillusion引擎正式开源!AIGC时代下的WebGPU轻量级3D渲染引擎!

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
![周也:上海又见面啦[好喜欢] ](https://imgs.knowsafe.com:8087/img/aideep/2021/7/11/d8fe8ff35749e3a269cd8ee0f7bf0af1.jpg?w=250)





 CSDN
CSDN
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675