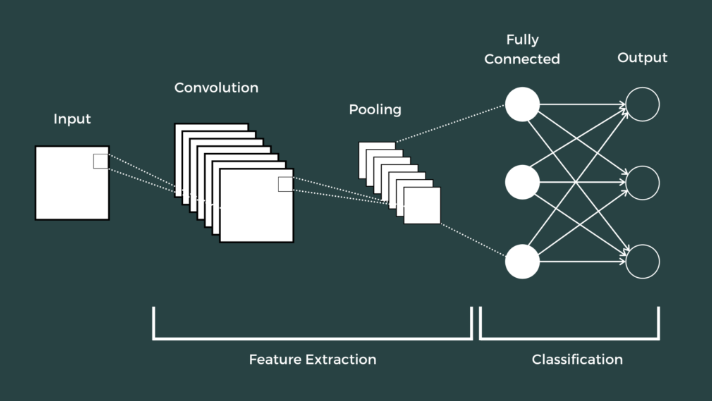
2022年有专家曾经预测:在视觉领域,卷积神经网络(CNN)会和Transformer平分秋色。随着Vision Transformers (ViT)成像基准SOTA模型的发布, ConvNets的黎明业已到来,这还不算:Meta和加州大学伯克利分校的研究认为, ConvNets模型的性能优越于ViTs。在视觉建模中,虽然Transformer很快取代了递归神经网络,但是对于那些小规模的ML用例, ConvNet的使用量会出现陡降。而小型Transformer+ CNN(卷积神经网络)的混合模型,即谷歌的MaxViT模型,具备475 M参数,几乎与ConvNet-7完全匹配(89.5 3%),在ImageNet上的性能为90.88%,位居第一。卷积神经网络的灵感来自神经科学家D.H.Hubel和T.N.Wiesel,他们在研究哺乳动物的视觉皮层时发现视觉皮层由多层神经元组成,这些层以分层结构排列,从而组成复杂的神经元。神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有位移或轻微变形的时候,也能完成识别。卷积神经网络是一种多层的监督学习神经网络,基础的CNN由 卷积(Convolution)、激活(Activation)和池化(Pooling)三种结构组成。隐含层的卷积层和池采样层是实现卷积神经网络特征提取功能的核心模块。该网络模型通过采用梯度下降法求最小化损失函数,对网络中的权重参数逐层反向调节,通过频繁的迭代训练提高网络的精度。卷积神经网络的低层由卷积层和最大池采样层交替组成,高层是全连接层对应传统多层感知器的隐含层和逻辑回归分类器。第一个全连接层的输入是由卷积层和子采样层进行特征提取得到的特征值,最后一层输出层是一个分类器,可以采用逻辑回归Softmax回归甚至是支持向量机对输入进行分类。CNN输出的结果是每幅图像的特定特征空间。当处理图像分类任务时,通常会把CNN输出的特征空间作为全连接层或全连接神经网络(Fully Connected Neural Network, FCN)的输入,用全连接层来完成从输入图像到标签集的映射,即分类。当然,整个过程最重要的工作就是如何通过训练数据迭代调整网络权重,也就是后向传播算法。目前主流的卷积神经网络(CNN)都是由简单的CNN调整、组合而来。图1 卷积神经网络的基础架构(来源:网络)
卷积神经网络中最基础的操作是卷积(Convolution)运算,卷积运算是卷积神经网络与其它神经网络相区别的一种运算,再精确一点,基础CNN所用的卷积是一种2-D卷积。卷积操作通过一个称为“卷积核“的窗口函数对输入进行过滤和特征提取,卷积核是一个维度更小的窗口函数,通过卷积核在二维空间的上下平移,计算出卷积核覆盖区域的点乘积,卷积的结果称为特征图或激活图。在实际使用中,经常在多个轴上使用卷积,因此上式也需要根据实际情况进行修改。例如,如果使用二维图像作为输入,会用到二维内核K:卷积之后,通常会加入偏置(Bias), 并引入非线性激活函数(Activation Function),这里定义偏置为b,激活函数是 h() ,经过激活函数后,得到如下结果:类似于其它深度学习算法,卷积神经网络通常使用修正线性单元(Rectified Linear Unit, ReLU),其它类似ReLU的变体包括有斜率的ReLU(Leaky ReLU, LReLU)、参数化的ReLU(Parametric ReLU, PReLU)、随机化的ReLU(Randomized ReLU, RReLU)、指数线性单元(Exponential Linear Unit, ELU)等 。在ReLU出现以前,通常利用Sigmoid函数和双曲正切函数(Hyperbolic Tangent)作为激活函数。池化(Pooling),是一种降采样操作(Subsampling),主要目标是降低特征映射空间的维度,即高维空间到低维空间的降维,或者可以认为是降低特征映射的分辨率。由于特征映射参数太多,不利于高层特征的抽取,池化操作可以降低卷积层的空间复杂性,降低学习的权重,从而加快训练的时间。历史上,曾经使用过不同的池化技术,主要的池化操作有:- 最大值池化( Max pooling):2 * 2的最大值池化就是取4个像素点中最大值保留
- 平均值池化( Average pooling): 2 * 2的平均值池化就是取4个像素点中平均值值保留
- L2池化( L2 pooling): 即取均方值保留
通常,最大值池化是首选的池化技术,池化操作会减少参数,降低特征图的分辨率,在计算力足够的情况下,这种强制降维的技术是非必须的,只有一些大型的CNN 网络会用到池化技术。如果卷积网络输入是224×224×3的图像,经过一系列的卷积层和池化层(卷积层增加深度维度,池化层减小空间尺寸),尺寸变为7×7×512,之后需要输出类别分值向量,计算损失函数。假设类别数量是1000(ImageNet是1000类),则分值向量可表示为特征图1×1×1000。如何将7×7×512的特征图转化为1×1×1000的特征图呢?最常用的技巧是全连接方式,即输出1×1×1000特征图的每个神经元(共1000个神经元)与输入的所有神经元连接,而不是局部连接。每个神经元需要权重的数量为7×7×512=25088,共有1000个神经元,所以全连接层的权重总数为:25088×1000=25088000,参数如此之多,很容易造成过拟合,这是全连接方式的主要缺点。全连接层的实现方式有两种:一种方式是把输入3D特征图拉伸为1D向量,然后采用常规神经网络的方法进行矩阵乘法;另一种方式是把全连接层转化成卷积层,这种方法更常用,尤其是在物体检测中。卷积神经网络(CNN)是前馈神经网络,层间无反馈,CNN 可以有效解决图像分类等模式识别问题。通常,CNN 的前面是较深的多层卷积层,后接较浅的全连接层,各种实验表明,增加卷积神经网络的深度比增加卷积神经网络的宽度能更加有效地提高准确率,使得CNN的深度越来越深,随着网络深度的增加,如何有效传递误差梯度,避免梯度消失或梯度爆炸已成为CNN 需要面对的首要问题。编辑:于腾凯
校对:王欣
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/





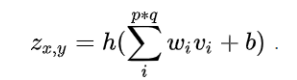







 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




