
如何使用Python构建一个文档扫描器?



pip install OpenCV-Python imutils scikit-image NumPy

import cv2
import imutils
from skimage.filters import threshold_local
from transform import perspective_transform

# Passing the image path
original_img = cv2.imread('sample.jpg')
copy = original_img.copy()
# The resized height in hundreds
ratio = original_img.shape[0] / 500.0
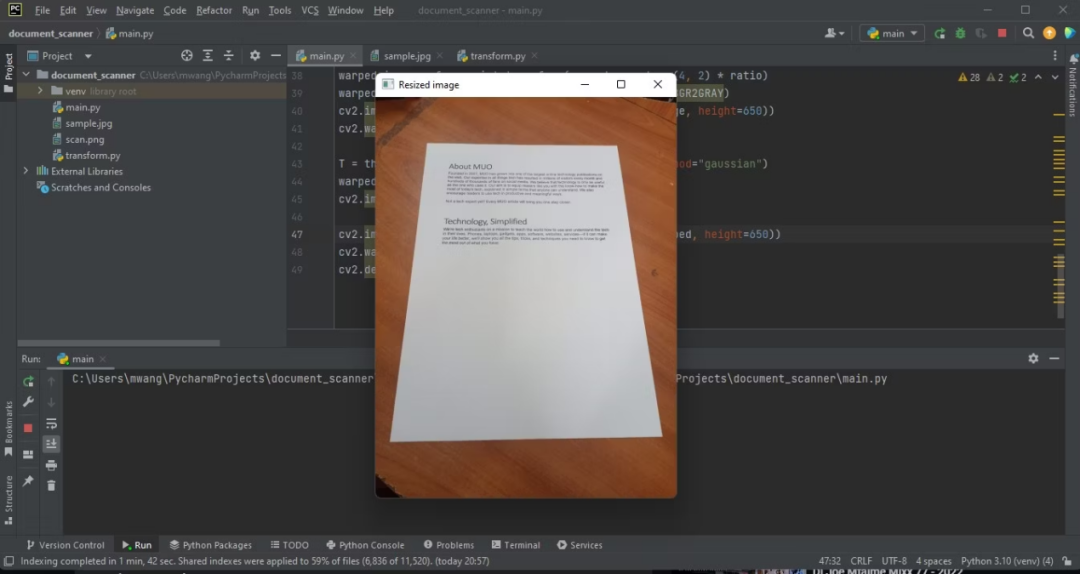
img_resize = imutils.resize(original_img, height=500)
# Displaying output
cv2.imshow('Resized image', img_resize)
# Waiting for the user to press any key
cv2.waitKey(0)

gray_image = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)
cv2.imshow('Grayed Image', gray_image)
cv2.waitKey(0)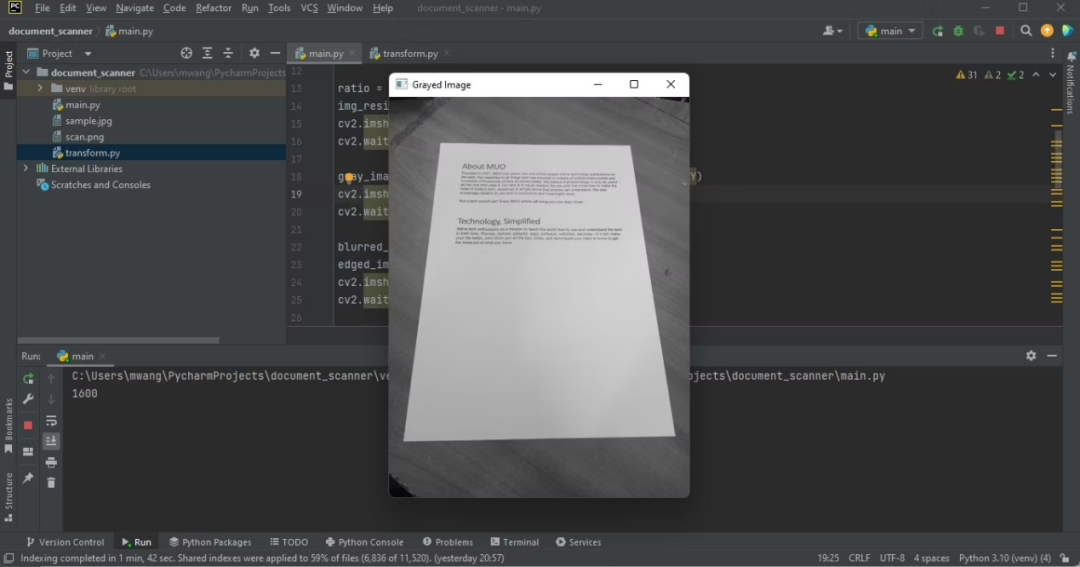

blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
edged_img = cv2.Canny(blurred_image, 75, 200)
cv2.imshow('Image edges', edged_img)
cv2.waitKey(0)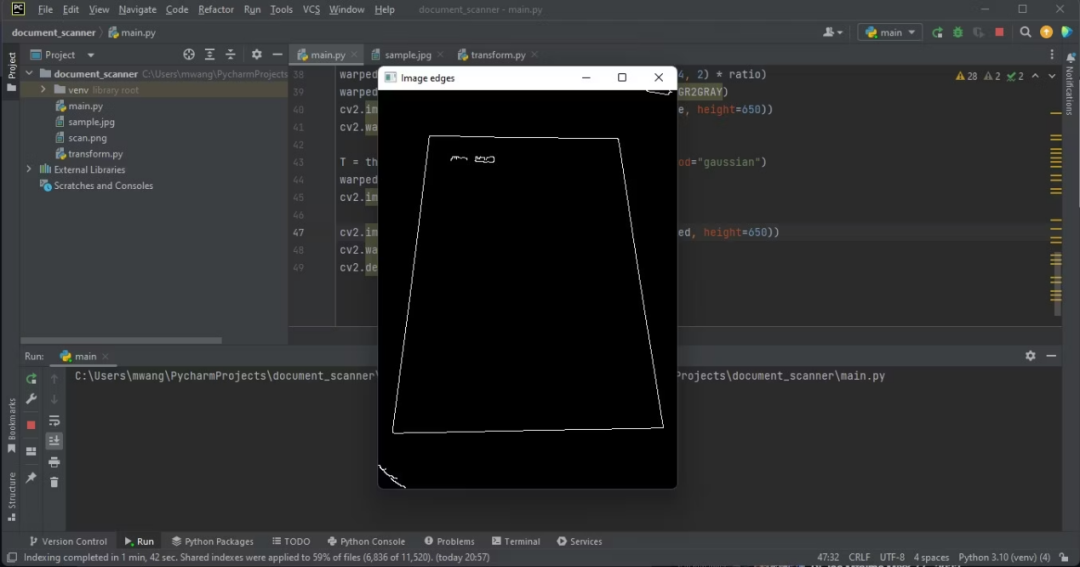

cnts, _ = cv2.findContours(edged_img, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
for c in cnts:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
if len(approx) == 4:
doc = approx
break
p = []
for d in doc:
tuple_point = tuple(d[0])
cv2.circle(img_resize, tuple_point, 3, (0, 0, 255), 4)
p.append(tuple_point)
cv2.imshow('Circled corner points', img_resize)
cv2.waitKey(0)

warped_image = perspective_transform(copy, doc.reshape(4, 2) * ratio)
warped_image = cv2.cvtColor(warped_image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Warped Image", imutils.resize(warped_image, height=650))
cv2.waitKey(0)
import numpy as np
import cv2
def order_points(pts):
# initializing the list of coordinates to be ordered
rect = np.zeros((4, 2), dtype = "float32")
s = pts.sum(axis = 1)
# top-left point will have the smallest sum
rect[0] = pts[np.argmin(s)]
# bottom-right point will have the largest sum
rect[2] = pts[np.argmax(s)]
'''computing the difference between the points, the
top-right point will have the smallest difference,
whereas the bottom-left will have the largest difference'''
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
# returns ordered coordinates
return rectdef perspective_transform(image, pts):
# unpack the ordered coordinates individually
rect = order_points(pts)
(tl, tr, br, bl) = rect
'''compute the width of the new image, which will be the
maximum distance between bottom-right and bottom-left
x-coordinates or the top-right and top-left x-coordinates'''
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
'''compute the height of the new image, which will be the
maximum distance between the top-left and bottom-left y-coordinates'''
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
'''construct the set of destination points to obtain an overhead shot'''
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# compute the perspective transform matrix
transform_matrix = cv2.getPerspectiveTransform(rect, dst)
# Apply the transform matrix
warped = cv2.warpPerspective(image, transform_matrix, (maxWidth, maxHeight))
# return the warped image
return warped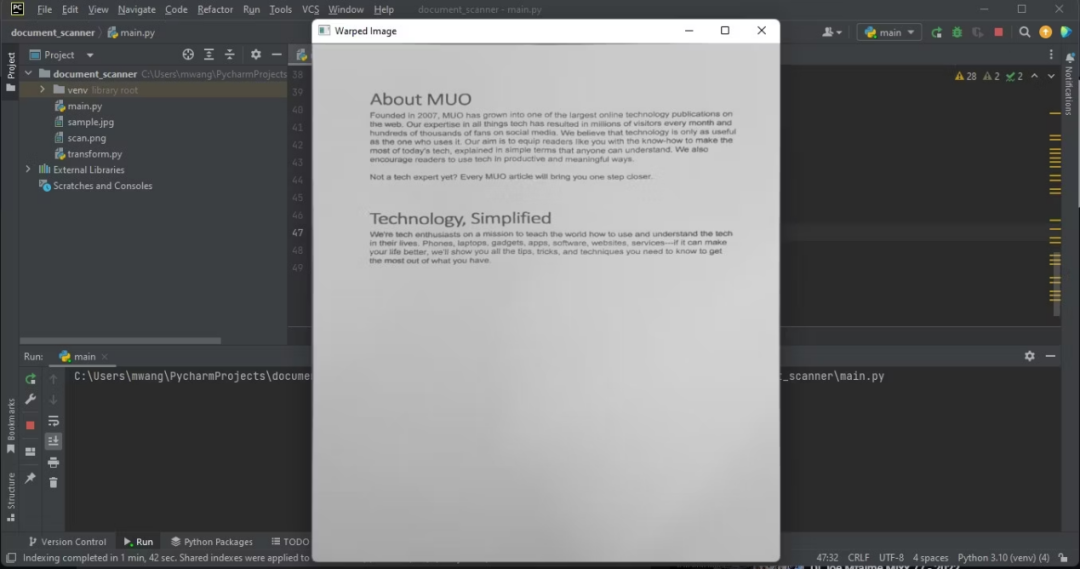

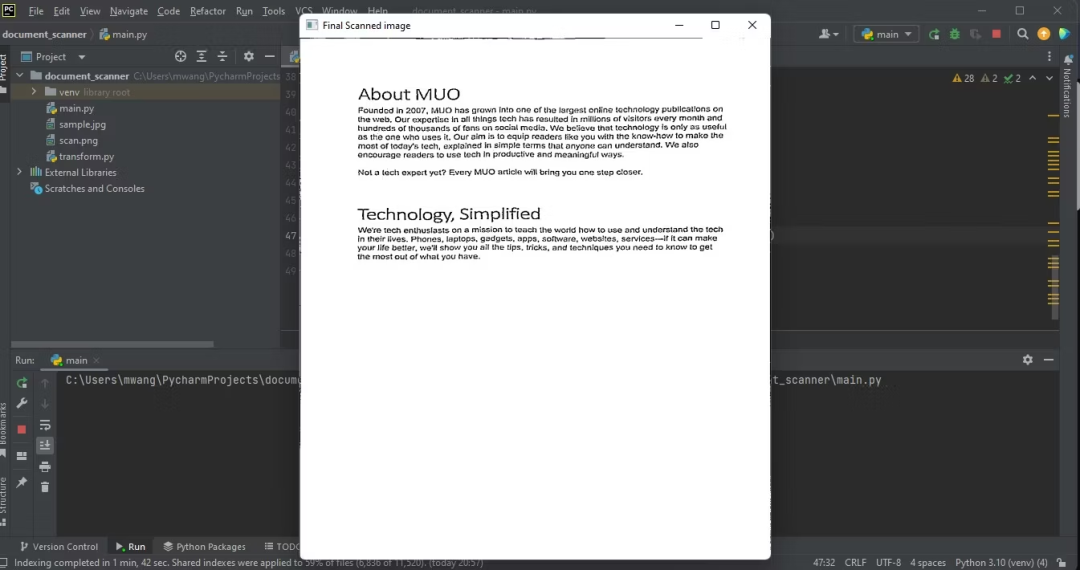
T = threshold_local(warped_image, 11, offset=10, method="gaussian")
warped = (warped_image > T).astype("uint8") * 255
cv2.imwrite('./'+'scan'+'.png',warped)
cv2.imshow("Final Scanned image", imutils.resize(warped, height=650))
cv2.waitKey(0)
cv2.destroyAllWindows()

原文链接:
https://www.makeuseof.com/python-create-document-scanner/

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/





 51CTO技术栈
51CTO技术栈
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675