
比 OpenAI 更好!!谷歌发布 20 亿参数通用语音模型——USM

整理 | 禾木木 责编 | 王子彧
去年11月,谷歌曾宣布“1000 种语言计划”,通过建立一个机器学习模型,从而支持世界上使用人数最多的 1000 种语言。
近日,谷歌正式发布 20 亿参数通用语音模型——USM,可支持 100 多种语言自动识别内容检测。谷歌将其描述为“最先进的通用语音模型”,拥有 20 亿个参数,经过了 1200 万小时的语音、280 亿个句子和 300 多个语种数据集的预训练。
目前该模型在 Youtube 的字幕生成中已展现出来,可自动翻译和检测,如英语、普通话,甚至是阿塞拜疆语、阿萨姆语等小众语言。
谷歌表示:“与 OpenAI 的大型通用语音模型 Whisper 相比,USM 的数据训练时长更短,错误率更低。”

支持 100 多种语言,将面临两大挑战
随着微软和谷歌就 AI 聊天机器人展开讨论后,我们逐渐清楚,这并不是机器学习和大语言模型的唯一用途。
据传言,谷歌计划在今年的年度 I/O 大会上展示 20 多款由 AI 驱动的产品。为了实现“1000种语言计划”,谷歌表示他们目前需要解决自动语音识别(ASR)中的两大挑战。
一是传统的学习方法的缺乏可扩展性。将语音技术扩展到多语种的一个基本挑战便是需要足够的数据来训练高质量的模型,使用传统方法时,需要手动将音频数据进行标记,既耗时、价格又高。而对于那些小众冷门的语种,更难找到预先存在的来源收集。
二是在扩大语言覆盖范围和提高模型质量的同时,模型必须以高效的计算方法来改进。这就要求学习算法更加灵活、高效、可推广。这些算法需要使用来源广泛的数据,并在不用重复训练的情况下更新模型,再推广到新的语言中。

三个步骤降低错误率
据论文介绍,USM 使用的是标准的编码器-解码器架构,其中解码器是 CTC、RNN-T 或 LAS。编码器则使用的是 Conformer 或卷积增强 transformer。Conformer的关键组件是 Conformer 块,它由注意力模块、前馈模块和卷积模块组成。通过将语音信号的 log-mel 声谱图作为输入,进行卷积下采样,然后使用一系列的 Conformer 块和投影层得到最终的嵌入。
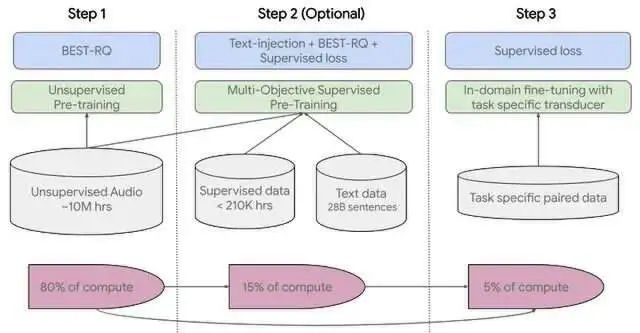
训练共分为三个步骤:
第一步,是使用 BEST-RQ 来对涵盖数百种语种的语音音频进行自我监督学习。
第二步,需要使用多目标监督预训练来整合来自于其他文本数据的信息。该模型引入了一个额外的编码器模块来输入文本,并引入额外层来组合语音编码器和文本编码器的输出,并在未标记语音、标记语音和文本数据上联合训练模型。
最后一步,需要 USM 对下游任务进行微调,包括 ASR(自动语音识别)和 AST(自动语音翻译)。

多项结果验证
YouTube Captions 上的多语言表现
谷歌通过预训练集成了 300 多种语言,并通过对 YouTube Captions 的多语言语音数据进行微调,证明了预先训练的编码器的有效性。
受监督的 YouTube 数据包括 73 种语言,平均每种语言的数据不到 3000 小时。尽管监督数据有限,但 USM 在 73 种语言中实现了小于 30% 的单词容错率(WER)。与当前内部最先进的模型相比,还要低 6%。与最近发布的大型模型 Whisper (large-v2)相比,USM 在 18 种语言中的错误率只有32.7%,同样低于 Whisper。


对下游 ASR 任务的可推广性
在公开可用的数据集上,USM 在 CORAAL (非裔美国人方言英语)、SpeechStew (en-US)和 FLEURS(102种语言)的数据集上的 WER 要比 Whisper 更低。不管是否接受过域内数据训练,USM 的 WER 都更低。


自动语音翻译(AST)
对于语音翻译,谷歌在 CoVoST 数据集上对 USM 进行微调。通过有限的监督数据达到了最佳性能。为了评估模型性能的广度,谷歌根据资源可用性将 CoVoST 数据集中的语言划分为高、中、低三种,并计算每个部分的 BLEU 得分(越高越好)。
如下图所示,USM 在所有细分领域的表现都优于 Whisper。

团队表示,谷歌的使命是整合全球信息并使人人皆可访问。而 USM 的开发便是实现这一使命的关键步骤。基于 USM 基础模型框架和训练 pipeline,未来谷歌可以将语音建模扩展至 1000 种语言。

结语
目前,USM 支持 100 多种语言。团队表示,谷歌的使命是整合全球信息并使人人皆可访问。
USM 的开发便是实现这一使命的关键步骤。
相信不久,谷歌可以将语音建模扩展至 1000 种语言。
参考链接:
https://analyticsindiamag.com/google-usm-shatters-language-barriers-with-multilingual-speech-recognition-model/
https://arxiv.org/abs/2303.01037
https://www.theverge.com/2023/3/6/23627788/google-1000-language-ai-universal-speech-model
https://ai.googleblog.com/2023/03/universal-speech-model-usm-state-of-art.html

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675