“目前水平最高”!Meta 挑战 ChatGPT

来源:数据观综合
继微软、谷歌之后,Facebook母公司Meta也宣布加入AI军备竞赛。

北京时间2月25日,脸书母公司 Meta CEO 扎克伯格在社交媒体宣布:推出最新的基于人工智能的大型语言模型(Large Language Model Meta AI,简称“LLaMA”)。


据Meta的首席 AI 科学家杨立昆介绍,一段时期以来一直批评ChatGPT“缺乏创新”,它匆忙推向大众,并且用RLHF(人类反馈强化学习)来纠正一些错误,并不能从根本上解决问题。他介绍说:“LLaMA 是 Meta AI - FAIR 的一种新的开源、高性能大型语言模型。Meta 致力于开放研究,并在 GPL v3 许可下向研究社区发布所有模型。”
对于Meta来说,大语言模型并不是一个陌生的赛道。早在去年5月,Meta就曾推出一款面向研究人员的名为OPT-175B的大型语言模型。去年11月,Meta又开发并上线了AI语言大模型Galactica,旨在运用机器学习来“梳理科学信息”。但此后却因散布了大量错误信息,在上线48小时后火速下线。
而ChatGPT的上线时间则为去年11月30日。也是因此,当ChatGPT爆火时,Yann LeCun还曾评论称,人们对于ChatGPT的态度比对Glacatica更宽容。
国外投资机构DA Davidson高级软件分析师Gil Luria认为:“Meta今天的公告似乎是测试他们生成式AI能力的一步,这样他们就可以在未来将它们应用到产品中。”他还补充道:“生成式AI作为AI的一种新应用,Meta对此经验较少,但显然对其未来的业务很重要。”

据悉,LLaMA 语言模型家族的参数量从 70 亿到 650 亿不等。相比之下,作为 AI“巨星”ChatGPT 的底层模型,OpenAI GPT-3 则拥有 1750 亿个参数。
根据 Meta 的说法,LLaMA 本质上不是聊天机器人,而是一种研究工具,可能会解决有关 AI 语言模型的问题。
据法新社称,按照 Meta 的表述,LLaMA 是一套“更小、性能更好”的模型,且不同于谷歌的 LaMDA 和 OpenAI 的GPT 机密训练资料和演算,LLaMA 是基于公开资料进行训练。
参数规模在 AI 领域非常重要,是负责在机器学习模型当中根据输入数据进行预测或分类的变量。语言模型中的参数规模往往直接决定其性能,较大的模型通常可以处理更复杂的任务、并产生更连贯的输出。然而,参数越多、模型占用的空间也越大,运行时消耗的算力也越夸张。因此,如果一个模型能够以更少的参数获得与另一模型相同的结果,则表示前者的效率有显著提高。
Meta 在官网表示,在大型语言模型中,像 LLaMA 这样的小型基础模型是可取的,因为测试新方法、验证他人的工作和探索新用例所需的计算能力和资源要少得多。基础模型基于大量未标记的数据进行训练,这使得它们非常适合于各种任务的微调。与其他大型语言模型一样,LLaMA 的工作原理是将一系列单词作为输入,并预测下一个单词以递归生成文本。
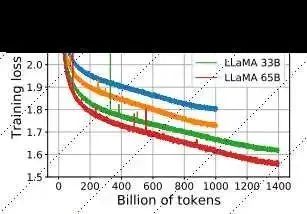
Meta 在其研究论文中指出,LLaMA-13B 在大多数基准测试中都优于 OpenAI 的 GPT-3 (175B),并且 LLaMA-65B 与最佳模型 DeepMind 的 Chinchilla70B 和谷歌的 PaLM-540B 具有竞争力。一旦经过更广泛的训练,LLaMA-13B 可能会成为希望在这些系统上运行测试的小型企业的福音,但是,它要让它脱离开发者独立工作,还有很长一段路要走。

LLaMA 与其他大模型参数对比
独立 AI 研究员 Simon Willison 在文章中评论称,“我认为,我们有望在未来一、两年内通过自己的(旗舰级)手机和笔记本电脑,运行具备 ChatGPT 中大部分功能的语言模型。”
Meta 称,将致力于这种开源模型的研究,新模型会开源给整个 AI 研究社区使用,并授予大学、非政府组织和行业实验室访问权限。另外,Meta 表示其还有更多研究需要做,以解决大型语言模型中的偏见、有害评论等风险。
Meta 训练其 LLaMA 模型所使用的是各类公开可用的数据集(例如 Common Crawl、维基百科以及 C4),意味着该公司可能会开源发布模型及其权重设置。在大语言模型行业当中,这代表着一波转折性的新发展,或将打破科技巨头在竞赛中永远把最好的 AI 技术“藏”起来的定式。
项目组成员 Guillaume Lample 在推文中指出,“与 Chinchilla、PaLM 或者 GPT-3 不同,我们只使用公开可用的数据集,这就让我们的工作与开源兼容且可以重现。而大多数现有模型,仍依赖于非公开可用或未明确记录的数据内容。”
Meta 将自己的 LLaMA 模型称为“基础模型”,意味着该公司打算以此为基础构建起更加完善的 AI 模型。这类似于 OpenAI 以 GPT-3 为基础构建 ChatGPT 的作法。Meta 方面希望 LLaMA 能在自然语言研究当中发挥作用,进而在“问答、自然语言理解或阅读理解、理解能力以及解决现有语言模型的局限性”等方面贡献力量。
虽然顶级 LLaMA 模型(LLaMA-65B,拥有 650 亿个参数)明显是在叫板竞争对手 DeepMin、谷歌及 OpenAI 的同类方案,但此次公布阵容中最有趣的反而可能是家族中的“小弟弟”LLaMA-13B,此外,Meta 也表示将提供 7B、13B、33B 和 65B 等参数尺寸的 LLaMA。
前面提到,LLaMA在多项基准测试时,在单 GPU 上运行的性能优于 GPT-3。而且跟 GPT-3 系列模型必须依赖于数据中心的庞大设施不同,LLaMA-13B 有望在不久的将来,让消费级硬件也能获得趋近 ChatGPT 的 AI 性能表现。
目前,精简版的 LLaMA 已经登陆 GitHub。要了解完整的代码的权重(即神经网络「学习」到的训练数据),Meta 已向感兴趣的研究人员开放访问申请表(https://forms.gle/jk851eBVbX1m5TAv5)。Meta 目前还未宣布更广泛的模型与权重公布计划。
LLaMA 项目地址:
红杉合伙人Sonya Huang、Pat Grady曾撰文称,当下行业正处于生成式AI第四波发展浪潮中——杀手级应用涌现阶段。随着各大平台发展成熟,AI模型继续变得更好、更快、更便宜,越来越多的模型免费、开源,应用层面将出现大爆发。
LLaMA 的发布,意味着Meta 正式加入微软、谷歌等硅谷公司的AI竞赛。不久前,谷歌刚刚推出了人工智能聊天机器人Bard,对标的竞品正是ChatGPT。此前,ChatGPT的走红被视为对搜索引擎的最大冲击,而谷歌恰恰是这一领域的霸主。
虽然Bard在演示中的意外“翻车”一度带崩了谷歌的股价,但这一动作传递出的信号已经不言而喻。谷歌在广告中表示,Bard使用谷歌的大型语言模型构建,并利用网络信息。谷歌还将其聊天机器人描述为“好奇心的发射台”,称它有助于简化复杂的话题。
作为ChatGPT“背后的人”,微软更是有效利用了这一波红利,宣布推出由ChatGPT支持的最新版本人工智能搜索引擎Bing(必应)和Edge浏览器。
公开信息显示,2019年,微软向OpenAI投资10亿美元,双方达成协议合作开发“通用人工智能”,同时微软获得将OpenAI的部分技术商业化的权限。今年1月,微软又表示,将对OpenAI进行为期数年、价值数以10亿计美元的投资,有知情人士透露,微软曾讨论向OpenAI投资至多100亿美元。
值得一提的是,微软旗下的OpenAI、谷歌旗下的DeepMind以及Meta旗下的FAIR也被公认为全球领先的三大AI实验室。硅谷三巨头在大语言模型上的对战,不是偶然,而是必然。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/



![脸红Dearie_最近最喜欢的颜色了[doge]](https://imgs.knowsafe.com:8087/img/aideep/2024/11/17/1fa0c8a5b60f80c1926b06be6605cf8c.jpg?w=250)


 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 习近平同马克龙交流互动的经典瞬间 7904043
- 2 解放军潜艇罕见集群机动 7809027
- 3 公考枪手替考89次敛财千万 7712865
- 4 2025你的消费习惯“更新”了吗 7618095
- 5 危险信号!俄数百辆保时捷突然被锁死 7522880
- 6 日本在与那国岛挖一锹土我军都能发现 7428636
- 7 连霍高速发生交通事故 造成9死7伤 7328720
- 8 今日大雪 要做这些事 7234206
- 9 15岁高中生捐赠南京大屠杀日军罪证 7140216
- 10 中疾控流感防治七问七答 7046111