
谷歌大模型团队并入DeepMind!誓要赶上ChatGPT进度

明敏 发自 凹非寺
量子位 | 公众号 QbitAI


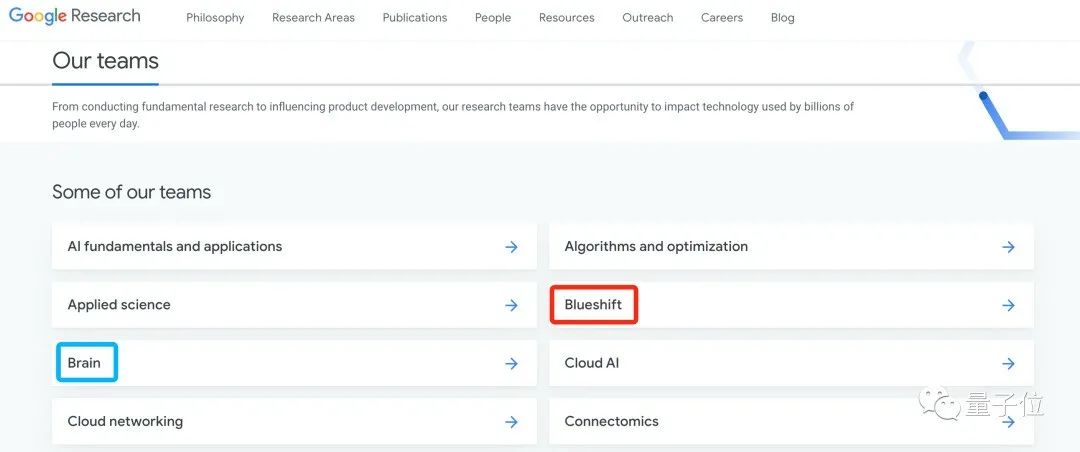
蓝移团队是谁?









谷歌还有多少后手?
这次蓝移团队的调动,也不免让外界猜测是否是谷歌为应对ChatGPT的最新举措。
ChatGPT引爆大模型趋势后,谷歌几乎是最先打响“阻击战”的大厂。
尽管加急发布的Bard效果确实有失水准,但这并不意味着谷歌会就此丧失竞争力。
诚如OpenAI之于微软,谷歌也有DeepMind。
DeepMind还是上一轮AI浪潮的引爆者。
消息显示,DeepMind手里也有聊天机器人。
去年9月,他们介绍了一个对话AI麻雀(Sparrow),它的原理同样是基于人类反馈的强化学习,能够依据人类偏好训练模型。

DeepMind创始人兼CEO哈萨比在今年早些时候说,麻雀的内测版本将在2023年发布。
他表示,他们将会“谨慎地”发布模型,以实现模型可以开发强化学习功能,比如引用资料等——这是ChatGPT不具备的功能。

但具体的发布时间还没有透露。
蓝移团队的加入公告中提到,他们是为了加速提升DeepMind乃至谷歌的LLM能力,不知这一动向是否会加速该对话模型的发布。
与此同时,谷歌也没有把目光完全局限在自家开发能力上。
本月初,劈柴哥重磅宣布,斥资3亿美元,紧急投资ChatGPT竞品公司Anthropic——由GPT-3核心成员出走创办。
1月底,该公司内测聊天机器人Claude,

目前,这家公司的最新估值已经达到50亿美元。
总而言之,谷歌虽然在Bard上栽了跟头,但也没把鸡蛋放在一个篮子里。接下来它在大模型上还有哪些新动作?还很有看头。
参考链接:
[1]https://twitter.com/bneyshabur/status/1629150056715816962
[2]https://research.google/teams/blueshift/
[3]https://www.deepmind.com/blog/building-safer-dialogue-agents
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675