作者:Wouter van Heeswijk, PhD诸如Q-learning和REINFORCE等强化学习算法问世已经几十年了,教科书仍然广泛围绕它们。然而这些算法暴露出的一些根本的缺陷,极大地增加了一个良好策略进行学习的难度。本文讨论经典强化学习算法的三个主要缺陷,以及克服这些缺陷的解决方案。问题描述
大多数RL算法在Q-learning算法基础上使用价值函数来捕获下游奖励,其中Q-learning算法的驱动机制是,它选择生成最高期望值的那个动作。由于初始化的不同,这种机制在尝试第一个操作时往往会卡住,所以通常选择概率为ϵ的随机操作,典型值设置为0.05左右。在极限情况下,会无限频次地尝试每个动作,直到Q收敛到真实值。然而,实际经常是使用有限的样本,Q值就带偏差,因此问题是Q-learning算法会持续地选择高估值的动作!想象一下,当玩两个相同的老虎机时,早期迭代中机器A碰巧给出了高于平均水平的奖励,所以它的Q值更高,继续玩机器A。于是,由于机器B使用更少,因此需要更长时间才能计算出Q值。即便实际上两台机器Q值相同。从一般意义上来说,价值函数并不总是完美的,虽然RL更喜欢执行估值较高的动作,但不排除可能有时候RL会“奖励”估值低的动作——这显然不是理想的属性。老虎机问题清楚证明了选择值溢出动作带来的影响[图源Bangyu Wang“Unsplash”杂志]解决方案
Q-learning算法的问题可以溯源到用相同的观察结果进行采样和更新的实践,通过使用一个策略进行采样并更新另一个策略来解耦这些步骤,这正是Q-learning(Van Hasselt,2010)所做的。双Q-learning对网络的动作进行采样,再用另一个网络的输出更新Q值,这一过程通过解耦出了采样和学习,解决了高估值问题。【资料来源:Van Hasselt(2010)]
一般来讲,与目标网络合作是一种不错的做法。目标网络是该策略的周期副本,用于生成训练的目标值(而不是使用完全相同的策略来生成观察和目标),这种方法降低了目标和观察结果之间的相关性。另一个解决方案是从Q-value估计不确定性的角度来考虑,不单单将动作的期望值制成表格,还可以跟踪观察结果的方差,从而知道它是否偏离了真实值。使用不确定性边界和知识梯度是实现这一目的的两种方法。这里不再是简单地选择具有最高期望Q值的动作,还应考虑可以从一个新的观察中学习到多少。利用这种智能采样方法可以探索具有高不确定性的动作。
问题描述
策略梯度算法已经存在了几十年,是所有演员-评论家模型的根源。传统的策略梯度算法,例如:REINFORCE,依靠梯度来确定权重更新的方向。高奖励和高梯度的结合会生成一个强大的更新信号。
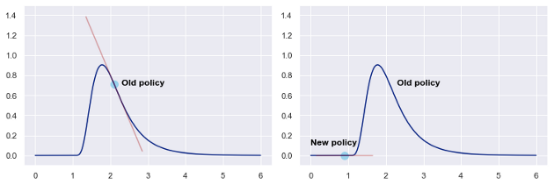
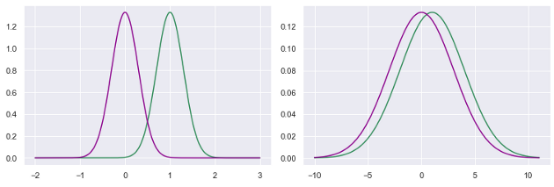
传统的策略梯度更新函数,基于目标函数梯度∇_θJ(θ)和步长α更新策略权值θ。这个想法似乎很自然,如果奖励函数的斜率很大,就会朝这个方向迈出一大步;如果奖励函数的斜率很小,那么执行大型更新就没有任何意义了。尽管这种逻辑看起来令人信服,但它从根本上也还存在缺陷。左:超调行为示例,执行一个错过奖励峰值的大策略更新。右:失速行为示例,被困在梯度接近0的局部最优中。[图片由作者提供]梯度只提供局部信息,它告诉我们斜坡有多陡,但不知道朝该方向走多远,可能会引发超调。此外,策略梯度并没有考虑到缺乏梯度信号可能会被困在一个次优的平台之中。更糟糕的是,无法通过强制更新某参数的局部权重来控制这种行为,例如,在下图中,相同大小的权重更新对策略有截然不同的影响。两个高斯策略更新的例子。尽管这两个更新的参数空间大小相同,但左边的策略显然比右边的策略受到的影响更大[图片由作者提供]解决方案
从简单的各种学习算法实验开始,传统随机梯度下降(SGD)算法只考虑一阶矩,现代学习算法(例如,ADAM)考虑二阶矩,大大提高了性能。
虽然没有彻底解决策略梯度更新不良问题,但性能还是得到了显著提高。熵正则化是防止常规策略梯度算法过早收敛的一种常用方法,简单地说,RL中的熵是动作选择不可预测性的一个度量标准。熵正则化为探索未知行为增添了一个奖项,当对系统了解较少时,熵的值会更高:更复杂的策略梯度算法的扩展会考虑二阶导数,它提供了函数的局部敏感性信息。在平缓的局部可以放心地前进多步;在一个陡峭的局部则倾向于谨慎地拾阶而下。自然策略梯度、TRPO和PPO等算法考虑了更新的敏感性,明确地或暗中地都考虑了二阶导数。目前,PPO是一种首选的策略梯度算法,它在实现难度,与速度性能之间,取得了良好的平衡。自然策略梯度的权重更新方案,费舍尔矩阵F(θ)包含关于局部灵敏度的信息,生成动态权重更新。
问题描述
某些植根于Q-learning的算法依赖于非策略学习,这意味着通过实际观察到的动作来执行更新。然而,非策略学习需要一个元组(s,a,r,s’,a’)——实际上,正如与它同名的SARSA算法一样——非策略学习使用动作a*而不是a’。因此,权重更新时只需要存储(s,a,r,s’),并学习独立于智能体动作的策略。通过特定的设置,非策略学习可以从过往重放缓冲区中提取元组来重复使用之前的观察,这为创建昂贵的观察结果(计算上)提供了方便。只需将状态输入策略,以获得动作a*,使用结果值更新 Q值,无需重新计算从s到s’的过渡状态。然而,即便已经在大型数据集上训练好了非策略强化学习算法,它在部署时的效果却往往还是不尽如人意,为什么会这样?这个问题可以归归纳出一个常见的统计学误区——假设训练集能代表真实的数据集。但情况发生变化,该数据集对应的策略无法反映智能体最终运行的环境策略——通常,真实数据集不同于训练集,更新后的策略生成了不同的状态-动作组合。解决方案
真正的非策略学习——例如,仅从静态数据集中学习好的策略——在强化学习中可能是根本不可行的,因为更新策略不可避免地会改变观察状态-动作组合的概率。由于不可能穷尽搜索空间,所以不可避免地会生成不可预见状态-动作组合的推断值。最常见的解决方案是不在一个完全静态的数据集上进行训练,而是用在新策略下生成的观察结果不断地丰富数据集。它有助于删除旧的样本,这些旧样本不再代表最新策略下生成的数据。另一种解决方案是重要性抽样,它本质上是根据当前策略下产生的概率来重新权衡观察结果。对于每个观测结果,可以计算其在原始策略和当前策略下产生的概率比,从而使来自类似策略的观测结果更有可能被采用。重要性抽样考虑了原始策略和目标策略之间的相似性,选择在与当前策略相似的策略下生成的具有更高概率的观察值。
本文探讨了传统RL算法中遇到的三个常见缺陷,以及解决这些问题的策略。I. 高估值的动作
- 基于值函数近似的算法,系统地选择估计价值高的动作。
- 使用目标网络来减少目标和观察之间的相关性(例如双Q-learning)。
- 在动作选择地价值估计中加入不确定性(如不确定性界限、知识梯度。)
II. 策略梯度更新不良
- 策略梯度算法通常执行更新步骤的能力较差,例如,停留在局部最优时的小步骤、超出并错过奖励峰值的大步骤。
- 使用ADAM学习算法取代标准的随机梯度下降,它除了跟踪一阶梯度外,还跟踪矩。
- 在奖励信号中添加熵奖励,鼓励更多对未知区域的探索。
- 部署包含二阶矩(显式或隐式)的算法,如自然策略梯度、TRPO或PPO。
III. 非策略学习性能欠佳
- 回放缓冲区中的过程不能代表外样本的过程,因此值被错误地外推,性能下降。
参考文献
问题一:值高估动作
哈塞尔特,H.(2010)。双q学习,神经信息处理系统的研究进展,23。Matiisen, Tambet (2015).揭开深度强化学习的神秘面纱。计算神经科学实验室。https://neuro.cs.ut.ee/demystifying-deep-reinforcement-learning/问题二:策略梯度更新不良
Mahmood,A. R.,Van Hasselt,H. P.,萨顿,R. S.(2014)。基于线性函数近似的非策略学习的加权重要性采样。神经信息处理系统研究进展,27。URL:https://optimization.cbe.cornell.edu/index.php?title=Adam问题三:非策略学习性能欠佳
藤本,南州,梅格, D., & Precup, D. (2019年5月)。非策略深度强化学习探索,国际机器学习会议。(pp.2052–2062).PMLR.Three Fundamental Flaws In Common Reinforcement Learning Algorithms (And How To Fix Them)https://towardsdatascience.com/three-fundamental-flaws-in-common-reinforcement-learning-algorithms-and-how-to-fix-them-951160b7a207
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/




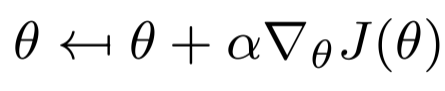
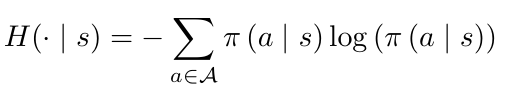

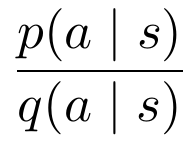







 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




