
万字长文:AI产品经理视角的ChatGPT全解析

作者/做产品的马丁
最近一段时间持续在关注两个技术方向:
2.Diffusion算法对图像领域的推动
今天这篇会先展开说一说ChatGPT,大致上包含以下方面:
4.AI产品经理在这波浪潮中可以做些什么
全文10389个字
对技术不感兴趣的可以直接滑动到屏幕将近一半的位置阅读第三部分和第四部分。
丨前言 一个AI产品经理的触动
2022年11月30日,chatgpt发布,5天内涌入100W用户。
他拥有持续的上下文对话能力,同时支持文章写作、诗词生成、代码生成等能力。
如果用旧技术去理解他,我们通常会认为他的背后是由复合Agent组合起来支撑的。
复合Agent是什么意思呢?即有若干个术业有专攻的Agent:有一个负责聊天对话的,一个负责诗词生成的,一个负责代码生成的, 一个负责写营销文案的等等等等。
每个Agent只擅长做自己的那部分事情,而在用户使用的过程中,系统会先判定用户的意图是什么,应该是哪个Agent,然后再将用户的命令分发给对应的agent去解决并提供答案。
因此看起来是很厉害的机器人,背后其实是若干个术业有专攻的机器人。事实上Siri、小爱、小度,小冰甚至包括各个平台的客服机器人都是这种模式。这样当你要上线一个新能力(例如写古诗),你只需要新增训练一个Agent,然后将这个Agent接入到总控的分类意图器下就行。
这也是当前时代的一个缩影,不管外行人如何看待你从事的行业,不管媒体是如何一次次人云亦云地说警惕AI取代人类,你一直都知道,你在做的只是训练出一个术业有专攻的机器人而已,离真正的人工智能十万八千里。
但ChatGPT的能力不再是这种模式了,他所采用的模式是大语言模型+Prompting。所有的能力通过一个模型实现,背后只有一个什么都会的机器人(即大语言模型),并支持用户借助文字下达命令(即Prompting,提示/指示)。
虽然这种能力的表现还不算完美,但是他开启了一条一种通向“通用型人工智能”的道路,曾经科幻故事里的Jarvis,moss好像真的有了那么一点可能。而这才是7年前,我踏入这个行业所憧憬的东西啊。
可能你对我的震撼有点无法理解,我接下来会讲明白他的技术原理,带你慢慢感知这项技术的牛逼之处,下面正式进入正文。
01
ChatGPT的技术原理
比如说,“我今天被我老板___”,经过大量的数据训练后,AI预测空格出会出现的最高概率的词是“CPU了”,那么CPU就会被填到这个空格中,从而答案产生——“我今天被我老板CPU了”
虽然非常不可思议,但事实就是这样,现阶段所有的NLP任务,都不意味着机器真正理解这个世界,他只是在玩文字游戏,进行一次又一次的概率解谜,本质上和我们玩报纸上的填字游戏是一个逻辑。只是我们靠知识和智慧,AI靠概率计算。
而在目前的“猜概率”游戏环境下,基于大型语言模型(LLM,Large Language Model)演进出了最主流的两个方向,即Bert和GPT。
其中BERT是之前最流行的方向,几乎统治了所有NLP领域,并在自然语言理解类任务中发挥出色(例如文本分类,情感倾向判断等)。
而GPT方向则较为薄弱,最知名的玩家就是OpenAI了,事实上在GPT3.0发布前,GPT方向一直是弱于BERT的(GPT3.0是ChatGPT背后模型GPT3.5的前身)。
接下来我们详细说说BERT和GPT两者之间的差别。
BERT:双向 预训练语言模型+fine-tuning(微调)
GPT:自回归 预训练语言模型+Prompting(指示/提示)
每个字都认识,连到一起就不认识了是吗哈哈。没关系,接下来我们把这些术语逐个拆解一遍就懂了:
丨「预训练语言模型」
我们通常认知里的AI,是针对具体任务进行训练。例如一个能分辨猫品种的Agent,需要你提供A-缅因猫,B-豹猫这样的数据集给他,让它学习不同品种之间的特征差异,从而学会分辨猫品种这项能力。
但大语言模型不是这样运作的,他是通过一个大一统模型先来认识这个世界。再带着对这个世界的认知对具体领域进行降维打击。
在这里让我们先从从NLP领域的中间任务说起。像中文分词,词性标注,NER,句法分析等NLP任务。他们本身无法直接应用,不产生用户价值,但这些任务又是NLP所依赖的,所以称之为中间任务。
在以前,这些中间任务都是NLP领域必不可少的。但是随着大型语言模型的出现,这些中间任务事实上已经逐步消亡。而大型语言模型其实就是标题中的“语言预训练模型”。
他的实现方式是将海量的文本语料,直接喂给模型进行学习,在这其中模型对词性、句法的学习自然而然会沉淀在模型的参数当中。我们看到媒体对ChatGPT铺天盖地的宣传里总是离不开这样一句话——在拥有3000亿单词的语料基础上预训练出的拥有1750亿参数的模型。
这里面3000亿单词就是训练数据。而1750亿参数就是沉淀下来的AI对这个世界的理解,其中一部分沉淀了Agent对各类语法、句法的学习(例如应该是两个馒头,而不是二个馒头,这也是中间任务为什么消亡的原因)。而另外一部分参数参数则储存了AI对于事实的认知(例如美国总统是拜登)。
也就是经过预训练出一个这样的大语言模型后,AI理解了人类对语言的使用技巧(句法、语法、词性等),也理解了各种事实知识,甚至还懂得了代码编程,并最终在这样的一个大语言模型的基础上,直接降维作用于垂直领域的应用(例如闲聊对话,代码生成,文章生成等)。
而BERT和GPT两者都是基于大语言模型的,他们在这一点上是相同的。他们的不同在于双向/自回归,fine-tuning/Prompting这两个维度,我们接下来会重点弄明白这四个术语。
丨「双向 VS 自回归」
BERT:双向。双向是指这个模型在“猜概率的时候”,他是两个方向的信息利用起来同时猜测。例如“我__20号回家”,他在预测的时候,是同时利用“我”+“20号回家”两端的信息来预测空格中的词可能为“打算”。有点像我们做英文的完形填空,通常都是结合空格两端的信息来猜测空格内应该是哪个单词。
GPT:自回归。自回归就是猜概率的时候从左往右做预测,不会利用文本中右侧的内容,和BERT相反。这就有点像我们写作文的时候,我们肯定是一边写一边想。
两者基本理念的区别导致BERT在之前更擅长自然语言理解类任务,而GPT更擅长自然语言生成类任务(例如聊天、写作文)。——注意,我说的是之前,后面的章节我会介绍现在的情况发生了什么变化。
丨「fine-tuning VS Prompting」
假设现在预训练好的大模型要针对具体领域工作了,他被安排成为一名鉴黄师,要分辨文章到底有没有在搞黄色。那么BERT和GPT的区别在哪里呢?
BERT:fine-tuning(微调)。微调是指模型要做某个专业领域任务时,需要收集相关的专业领域数据,做模型的小幅调整,更新相关参数。
例如,我收集一大堆标注数据,A-是黄色,B-没有搞黄色,然后喂给模型进行训练,调整他的参数。经过一段时间的针对性学习后,模型对于分辨你们是否搞黄色的能力更出色了。这就是fine-tuning,二次学习微调。
GPT:Prompting。prompt是指当模型要做某个专业领域的任务时,我提供给他一些示例、或者引导。但不用更新模型参数,AI只是看看。
例如,我提供给AI模型10张黄色图片,告诉他这些是搞黄色的。模型看一下,效果就提升了。大家可能会说,这不就是fine-tuning吗?不是一样要额外给一些标注数据吗?
两者最大的区别就是:这种模式下,模型的参数不会做任何变化升级,这些数据就好像仅仅是给AI看了一眼——嘿,兄弟,参考下这个,但是别往心里去。
不可思议吧,但他成功了!而更令人疯狂的是,到目前为止,关于prompt明明没有对参数产生任何影响,但确实又明显提升了任务的效果,还是一个未解之谜。暂时而言大家就像程序员对待bug一样——I don't know why , but it work lol .
这种Prompt其实就是ICT(in-Context Learning),或者你也可以称为Few shot Promot,用大白话说就是“给你一点小提示”。
同时还有另外一种Promot,称之为Zero shot Promot。ChatGPT就是Zero shot promot模式,目前一般称之为instruct了。
这种模式下用户直接用人类的语言下达命令,例如“给我写首诗”,“给我做个请教条”,但是你可以在命令的过程中用一些人类语言增强AI的效果,例如“在输出答案之前,你先每一步都想一想”。就只是增加这样一句话,AI的答案效果就会明显提升。
你可能会问这是什么魔法咒语?!
有一个比较靠谱的猜测是这句话可能让AI回想起了学习的资料中那些推理知识好像前面都会有这句话。
然后这一切莫名激活起了他死去的记忆,不自觉开始仿造那些严密的推理过程中一步步推导。而这些推导会将一个复杂问题分解成若干子问题,AI因为对这些子问题的推导,从而导致最终答案效果提升。
综上对比下来,你会发现好像GPT这种模式比起BERT模式更符合我们对人工智能的想象:通过海量的知识成长起来,然后经过稍微引导(Prompt),他就能具备不同领域的强大能力。
最后总结一下,ChatGPT背后的GPT模型是什么?
在一个超大语料基础上预训练出的大语言模型(LLM),采用从左到右进行填字概率预测的自回归语言模型,并基于prompting(提示)来适应不同领域的任务。
如果只基于上面的描述,你可能大概弄懂了他背后的原理,但是对于为什么他这么牛逼,你仍然无法理解。没关系,我们接着进入第二部分。
02
GPT牛逼在哪里?
在我们原始的幻想里,AI是基于对海量数据的学习,锻炼出一个无所不知无所不能的模型,并借助计算机的优势(计算速度、并发可能)等碾压人类。
但我们目前的AI,不管是AlphaGo还是图像识别算法,本质上都是服务于专业领域的技术工人。


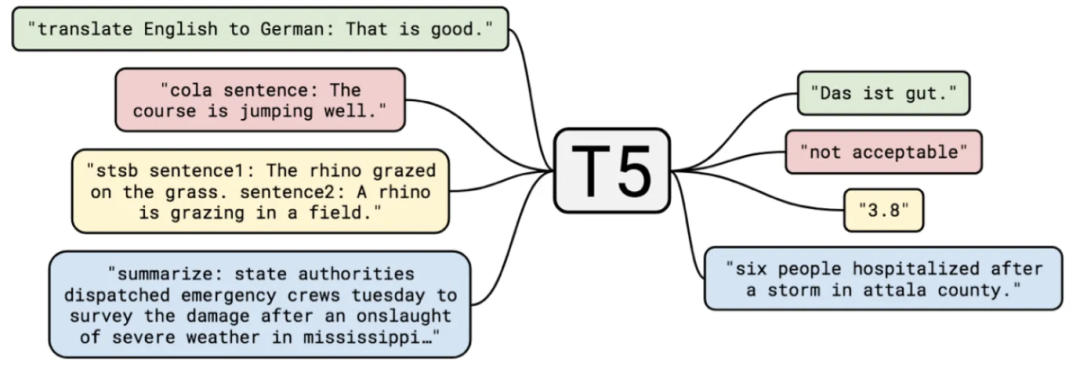
> 执行翻译任务
> 输入是“我爱北京天安门(中文)”
> 翻译目标语种是英文”
而现在你直接说:
> 帮我把我爱北京天安门翻译成法语
> 如何毁灭世界——你可以召唤三体人降临(此处应有一个潘寒hhh)
> 如何毁灭世界——亲,请不要毁灭世界,地球是人类共同的家园
然后我们利用这批标注好的“人类偏好”数据,训练一个回报模型,这个回报模型会对原始模型的结果进行打分,告诉他什么答案分高,什么答案分低。


1.基于instruct GPT复现(ChatGPT的姐妹模型,有公开paper)
2.基于OpenAI目前开放的GPT3.0付费接口落地,再结合具体场景进行fine-tuning,目前刊例价费用是25000token/美元,换算国内价格约3700token/元
第二种和第三种路径需要打平付费接口的成本,需要针对的场景具备足够价值。
1.结果不稳定。这会导致无法直接应用,必定需要人工review,更多是瞄准辅助性场景或本身就不追求稳定的场景。
2.推理能力有限。例如询问现在的美国总统是谁,会回答奥巴马,或特朗普,但又能回答出拜登是46届总统。我们可以发现模型中事实存在,但他无法推理出正确答案。
如果要优化,一方面是输入的时候,可以通过Prompt逐步引导,另一方面是在模型侧的Few Shot Prompt环节中采用思维链技术(CoT,Chain of Thought)或采用代码数据集来改进。就目前而言,进展可喜,但能力仍然有限。
03
ChatGPT所代表的
大语言模型应用方向
从目前来看,应用方向可以分成三种
04
AI产品经理能做什么?
1.chatbot要支持记忆用户输入的偏好信息,例如喜欢黄金时代,储存时间为永久,并且支持知识的互斥与整合(例如先说喜欢下雨天,后面又说讨厌下雨天)
2.需要chatbot支持记忆用户输入的偏好信息,并且这个能否不要用模型参数去学习,而是搭建一个独立的知识库,再通过模型另外调用?这样用户可以可视化地修正自己的偏好知识。
1.取决于产品的技术实力。有时候你的技术实力就决定了你深不了。没关系,其实到第三个层次并不是必须的,一般到第二个层次就够用了,甚至到不了第二层次,就在第一个层次上你把需求讲明白,也是能跑的下去。只是这样产品的权威性,你对需求的判断,ROI的平衡判断都会产生很大的问题。
2.取决于需求的目的,例如第一个层次的需求没有专门提及知识库,那这个时候用模型去学习记录也可以,用知识库也可以。但是第二个需求中就明确要求了基于知识库的实现方法,因为他需要用户可视化修改自己的偏好知识。(甚至有时候最后不一定是用知识库的方法,但没关系,提出你的idea,与算法团队深入讨论,多少都是一种启发)
但是自己练习一下还是可以的,有一个具现的产品做逻辑推导的练习,会比只阅读理论文章来得更有效。
END
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 腾讯创业
腾讯创业
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675