作者:符尧、Tushar Khot、彭昊、李如寐等符尧(yao.fu@ed.ac.uk),爱丁堡大学 (University of Edinburgh) 博士生,本科毕业于北京大学。他与 Tushar Khot、彭昊在艾伦人工智能研究院 (Allen Institute for AI) 共同完成英文原稿,与李如寐(美团 NLP 中心) 共同翻译为中文。感谢 Aristo teammates, Jingfeng Yang, and Yi Tay 的讨论与建议。请同时参考 CoT 团队的博客[1]
注:本文完成于 ChatGPT 上线之前的一个月,当时作者意识到大模型非同小可,所以写下本文,希望引起更多人关注到大模型有可能带来的研究范式转变。一个月之后,ChatGPT 上线,全网轰动,范式从此转变。
最近,人们对大型语言模型所展示的强大能力(例如思维链[2]、便签本[3])产生了极大的兴趣,并开展了许多工作。我们将之统称为大模型的突现能力[4],这些能力可能[5]?只存在于大型模型中,而不存在于较小的模型中,因此称为 “突现”。其中许多能力都非常令人印象深刻,比如复杂推理、知识推理和分布外鲁棒性,我们将在后面详细讨论。值得注意的是,这些能力很接近 NLP 社区几十年来一直寻求的能力,因此代表了一种潜在的研究范式转变,即从微调小模型到使用大模型进行上下文学习。对于先行者来说,范式转变可能是很显然的。然而,出于科学的严谨性,我们确实需要非常明确的理由来说明为什么人们应该转向大型语言模型,即使这些模型昂贵[6]、难以使用[7],并且效果可能一般[8]。在本文中,我们将仔细研究这些能力是什么,大型语言模型可以提供什么,以及它们在更广泛的 NLP / ML 任务中的潜在优势是什么。原文链接:yaofu.notion.site/A-Closer-Look-at-Large-Language-Models-Emergent-Abilities-493876b55df5479d80686f68a1abd72f- 预训练、精调、提示(普通从业者应具备的自然语言处理 / 深度学习能力)
- 思维链提示、便签本(普通从业者可能不太了解,但不影响阅读)
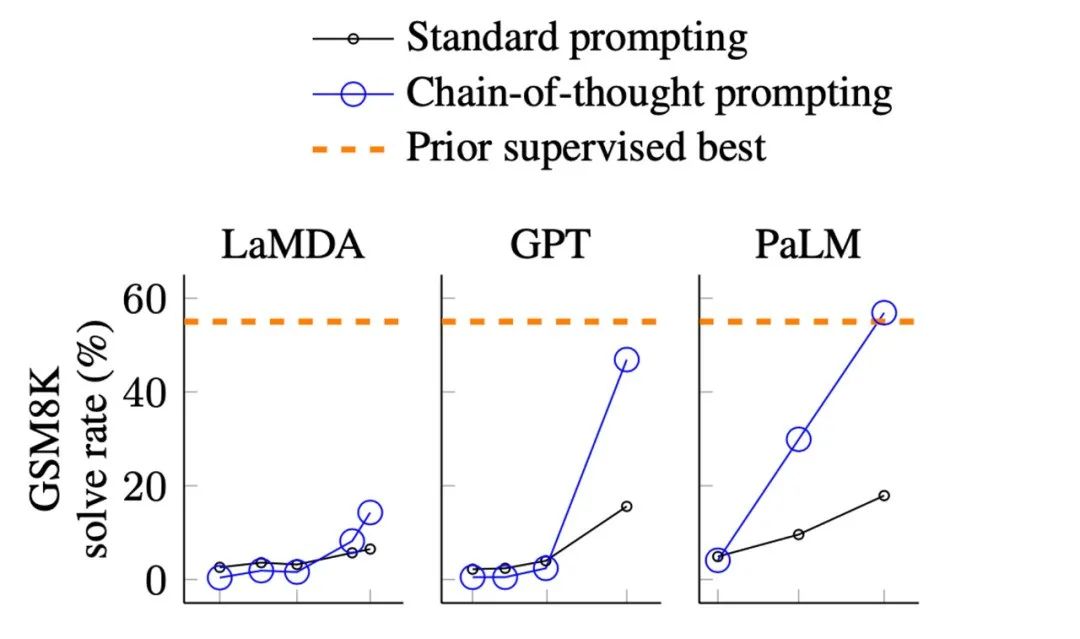
图片来自于 Wei. et. al. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models。X 轴为模型大小。GSM8K 是是一个小学水平的数学问题集。?这从根本上说明,某些能力可能不存在于小模型中,而是在大模型中获得的。有很多种突现能力,比如 Wei 等人在 2022 年[9]所梳理的。有些能力很有意思,但我们在本文不会讨论,比如把一串单词的最后一个字母拼起来,我们认为这是 Python 而不是语言模型要做的任务;或者 3 位数加法,我们认为这是计算器而不是语言模型要做的事。1. NLP 社区近几年都关注,但之前的 NLP 模型很难达到的能力2. 源自于人类语言最深层的本质的能力(能力的深度)3. 可能达到人类智力的最高水平的能力(能力的上限)很多有意思的能力都可以归到上文提到的类别里,在它们之中,我们主要讨论以下三种典型能力:下面是一个 GSM8K 数据集中,用提示词显著超过精调的例子:?虽然这道题对于 10 岁的孩子来说很容易,但对语言模型来说却很难,主要是由于数学和语言混合在一起。GSM8K 最初由 OpenAI 于2021 年 10 月[10]提出。当时他们用第一版[11]GPT3 在全部训练集上进行了精调,准确率约为 35%。这个结果让作者相当悲观,因为他们的结果显示了语言模型的缩放规律:随着模型大小呈指数增长,性能呈线性增长(我之后会讨论)。因此,他们在第 4.1 节中思考:
“175B 模型似乎需要至少额外两个数量级的训练数据才能达到?80% 的求解率。”
三个月后,即2022 年 1 月,Wei 等人[12]?基于540BPaLM 模型,仅使用了 8 个思维链提示示例便将准确率提高到 56.6%(无需将训练集增加两个数量级)。之后在 2022 年 3 月,Wang 等人[13]?基于相同的 540B PaLM 模型,通过多数投票的方法将准确率提高到74.4%。当前的 SOTA 来自我自己在 AI2 的工作(Fu et. al. Nov 2022[14]),我们通过使用复杂的思维链在 175B Codex 上实现了 82.9%?的准确率。从以上进展可以看到,技术进步确实呈指数级增长。思维链提示是一个展示模型随着规模突现出能力的典型例子:- 从突现能力来看:只有模型大于 100B ,才能使思维链的效果大于的仅有回答提示。所以这种能力只存在于大型模型中。
- 从效果来看:思想链提示的性能明显优于其之前的精调[15]方法。
- 从标注效率上来看:思维链提示只需要 8 个示例的注释,而微调需要完整的训练集。
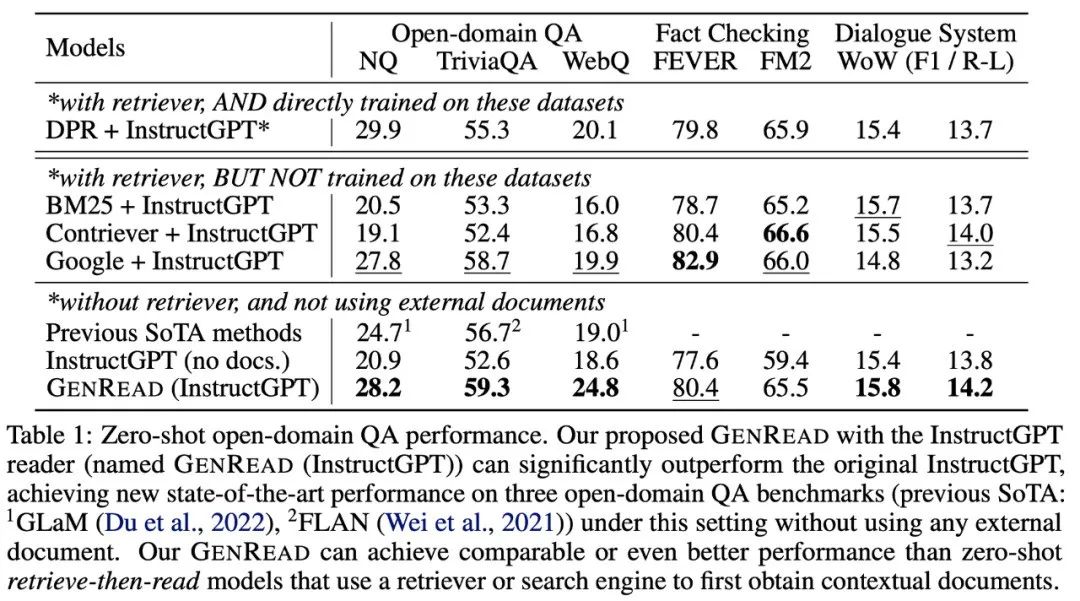
有些同学可能会认为模型能做小学数学代表不了什么(从某种意义上说,他们确实没有那么酷)。但 GSM8K 只是一个开始,最近的工作已经把前沿问题推向了高中[16]、大学[17],甚至是国际数学奥林匹克问题[18]。现在更酷了吗?下一个例子是需要知识的推理能力(例如问答和常识推理)。在这种情况下,对大型模型进行提示不一定优于精调小型模型(哪个模型更好还有待观察)。但是这个情况下的注释效率被放大了,因为:- 在许多数据集中,为了获得所需的背景 / 常识知识,(以前很小的)模型需要一个外部语料库 / 知识图谱来检索[19],或者需要通过多任务学习在增强[20]的数据上进行训练
- 对于大型语言模型,可以直接去掉检索器[21],仅依赖模型的内部知识[22],且无需精调
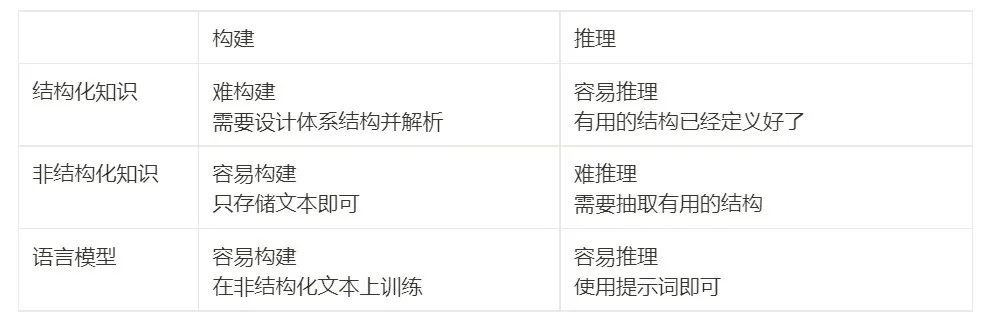
图片来自于 Yu et. al. 2022. 以前的 SOTA 模型需要从外部知识源中检索。GPT-3 的性能与以前的模型相当 / 优于以前的模型,且无需检索。?如表中所示,与数学题的例子不同,GPT-3 并没有明显优于之前的精调模型。但它不需要从外部文档中检索,本身就包含了知识[23]。?为了理解这些结果的重要性,我们可以回顾一下历史:NLP 社区从一开始就面临着如何有效编码知识的挑战。人们一直在不断探究把知识保存在模型外部或者内部的方法。上世纪九十年代以来,人们一直试图将语言和世界的规则记录到一个巨大的图书馆中,将知识存储在模型之外。但这是十分困难的,毕竟我们无法穷举所有规则。因此,研究人员开始构建特定领域的知识库,来存储非结构化文本、半结构化(如维基百科)或完全结构化(如知识图谱)等形式的知识。通常,结构化知识很难构建(因为要设计知识的结构体系),但易于推理(因为有体系结构),非结构化知识易于构建(直接存起来就行),但很难用于推理(没有体系结构)。然而,语言模型提供了一种新的方法,可以轻松地从非结构化文本中提取知识,并在不需要预定义模式的情况下有效地根据知识进行推理。下表为优缺点对比:??我们讨论的第三种能力是分布外的鲁棒性。在 2018 年至 2022 年期间,NLP、CV 和通用机器学习领域有大量关于分布偏移 / 对抗鲁棒性 / 组合生成的研究,人们发现当测试集分布与训练分布不同时,模型的行为性能可能会显著下降。然而,在大型语言模型的上下文学习中似乎并非如此。Si 等人[24]?在 2022 年的研究显示:?数据来自于 Si et. al. 2022. 虽然 GPT-3 在同分布设置下比 RoBERTa 要差,但在非同分布设置下优于 RoBERTa,性能下降明显更小。?同样,在此实验中,同分布情况下基于提示词的 GPT-3 的效果并没有精调后的 RoBERTa 要好。但它在三个其他分布(领域切换、噪声和对抗性扰动)中优于 RoBERTa,这意味着 GPT3 更加鲁棒。??此外,即使存在分布偏移,好的提示词所带来的泛化性能依旧会继续保持。比如:?图片来自于 Fu et. al. 2022. 即使测试分布与训练分布不同,复杂提示也始终比简单提示的表现更好。?Fu 等人 2022 年[25]?的研究显示,输入提示越复杂,模型的性能就越好。这种趋势在分布转移的情况下也会继续保持:无论测试分布与原分布不同、来自于噪声分布,或者是从另一个分布转移而来的,复杂提示始终优于简单提示。?在上文中,我讨论了只有大型模型才有的三种突现能力。它们是:- 复杂推理,大型模型在没有使用全部训练数据的情况下便显著优于以前的小型模型。
- 知识推理,大型模型可能没有小模型效果好,但大模型不需要额外的知识来源(知识可能很昂贵,或者很难从非结构化数据中抽取)。
- 分布外鲁棒性,这是之前进行模型精调时需要努力解决的问题。大型模型虽然在同分布情况下的效果不如以前的方法,但非同分布情况下的泛化性能却好得多。
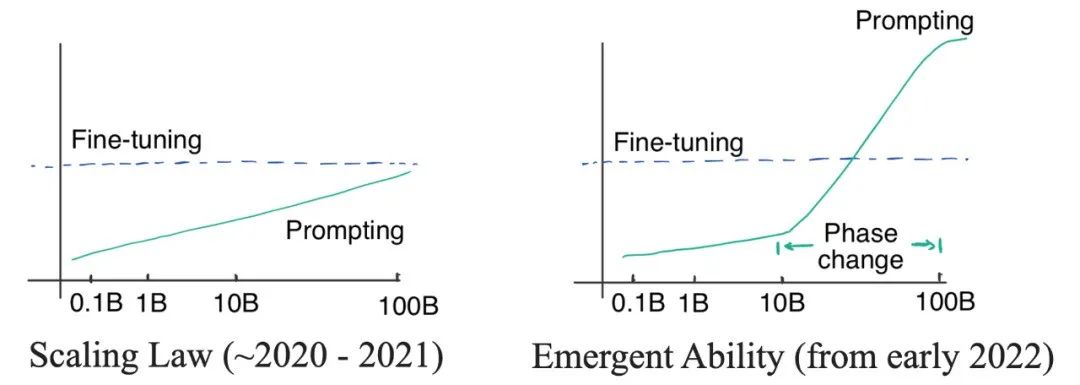
鉴于上文列出的优点,大家可能会开始觉得大型语言模型确实很好了。在进一步讨论之前,让我们再回顾一下之前的工作,就会发现一个很奇怪的问题:GPT-3 在 2020 年就发布了,但为什么直到现在我们才发现并开始思考范式的转变?这个问题的答案就藏在两种曲线中:对数线性曲线和相变曲线。如下图:左图:比例定律。当模型大小呈指数增长时,相应的模型性能呈线性增长。右图:当模型尺寸达到一定规模时,会出现突现能力,让性能急剧增加。?最初,(OpenAI)的研究者认为语言模型的性能与模型尺寸的关系可以通过对数线性曲线预测,即模型尺寸呈指数增长时,性能会随之线性增加。这种现象被称为语言模型的缩放定律,正如 Kaplan 等人在 2020 年[26]?最初[27]?的 GPT3 文章中讨论的那样。重要的是,在那个阶段,即便最大的 GPT-3 在有提示的情况下也不能胜过小模型精调。所以当时并没有必要去使用昂贵的大模型(即使提示词的标注效率很高)。直到 2021 年,Cobbe 等人[28]?发现缩放定律同样适用于精调。这是一个有点悲观的发现,因为它意味着我们可能被锁定在模型规模上?—— 虽然模型架构优化可能会在一定程度上提高模型性能,但效果仍会被锁定在一个区间内(对应模型规模),很难有更显著的突破。在缩放定律的掌控下(2020 年到 2021),由于 GPT-3 无法胜过精调 T5-11B,同时 T5-11B 微调已经很麻烦了,所以 NLP 社区的关注点更多的是研究更小的模型或者高效参数适应。Prefix tuning[29]?就是提示和适应交叉的一个例子,后来由 He 等人[30]?在 2021 统一。当时的逻辑很简单:如果精调效果更好,我们就应该在高效参数适应上多下功夫;如果提示词的方法更好,我们应该在训练大型语言模型上投入更多精力。之后在 2022 年 1 月,思维链的工作被放出来了。正如作者所展示的那样,思维链提示在性能 - 比例曲线中表现出明显的相变。当模型尺寸足够大时,性能会显著提高并明显超越比例曲线。当使用思维链进行提示时,大模型在复杂推理上的表现明显优于微调,在知识推理上的表现也很有竞争力,并且分布鲁棒性也存在一定的潜力。要达到这样的效果只需要 8 个左右的示例,这就是为什么范式可能会转变(注:本文完成于 ChatGPT 上线之前的一个月;在 ChatGPT 上线之后,整个领域为之震撼,意识到范式已经转变了)。范式转变究竟意味着什么?下面我们给出精调和提示词方法的对比:提示词的好处很明显:我们不再需要繁琐的数据标注和在全量数据上进行精调,只需要编写提示词并获得满足要求的结果,这比精调要快很多。- 相似之处在于,上下文学习也需要像训练数据一样的示例
- 不同之处在于,上下文学习的泛化行为并不同于监督学习,这使得之前的泛化理论(例如 Rademancher Complexity 或 Neural Tangent Kernel)均不适用。
- 大多数提示词和精调的对比都只比了 提示词 + 大模型 vs 精调 + 小模型,但公平的对比应该是 提示词 + 大模型 vs 精调 + 大模型,且对比时的基座模型应该一样。所以在最初的思维链文章中,如果 Wei 等人要说明提示词好于精调,他们应该对比精调后的 PaLM,而不是 GPT3。
- 我的假设是:精调可以提高分布内的性能,但会损害分布外的鲁棒性。提示词在分布转化的场景中表现更好,但在同分布场景下不如精调。
- 如果假设是真的,那么一个值得研究的问题就是如何在不牺牲其上下文学习能力的情况下进行精调
- 注意分布外精调的效果同样会随着模型尺寸变化。比如 Yang 等人在 2022 年的工作中,第四张表就显示,Bart-based 的分布外泛化能力会下降,但 Bart-large 则提升。对于大模型,当测试集的分布和训练集相差不大时,分布内的精调效果也应该会提升。
再回顾一下前文提到的的逻辑:如果精调更好,我们应该努力研究如何进行参数高效的优化;如果提示词更好,我们应该努力去训练更好的大型语言模型。所以,尽管我们相信大型语言模型有巨大的潜力,仍然没有确凿的证据表明精调和提示词哪种方法更好,因此我们不确定范式是否真的应该转变、或应该转变到什么程度。仔细比较这两种范式,使我们对未来有一个清晰的认识,是非常有意义的。我们将更多讨论留到下一篇文章。- 模型至少需要 62B,使思维链的效果才能大于标准的提示词方法。
- 模型至少需要 175B(GPT3 的尺寸),思维链的效果才能大于精调小模型(T5 11B)的效果。
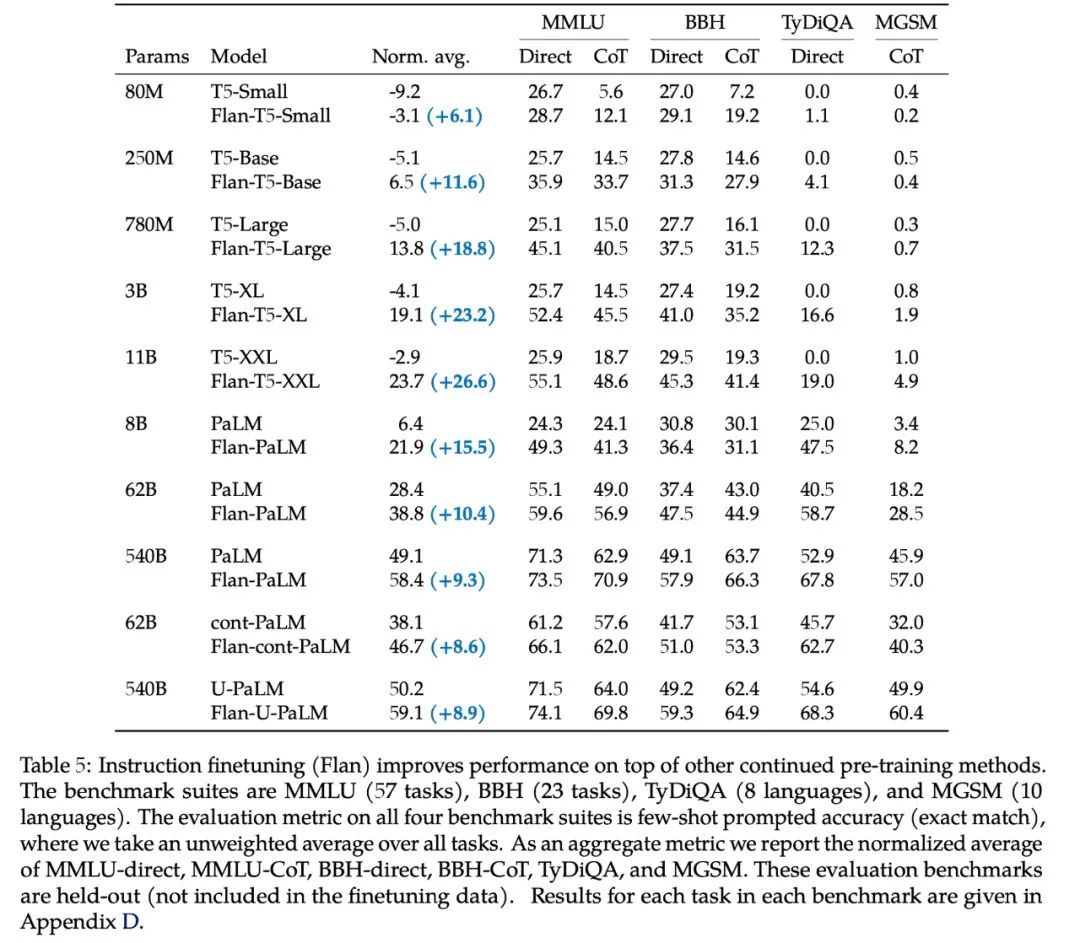
62B 这个数字来自于 Chung 等人 2022 年[31]?工作的第五张表:对于所有小于 62B 的模型,直接用提示词都好于思维链。第一个用思维链更好的模型是 Flan-cont-PaLM 62B 在 BBH 上的结果。540B 的模型使用思维链会在更多任务上得到好的效果,但也不是全部任务都好于精调。另外,理想的尺寸可以小于 540B,在 Suzgun 等人 2022 年[32]的工作中,作者展示了 175B 的 InstructGPT 和 175B 的 Codex 使用思维链都好于直接用提示词。综合以上结果,我们得到了 63B 和 175B 两个数字。所以,如果想要参与这场游戏,首先要有一个大于平均尺寸的模型。不过,还有其他大型模型在思维链下的表现差了很多,甚至不能学到思维链,比如 OPT、BLOOM 和 GPT-3 的第一个版本。他们的尺寸都是 175B。这就引出了我们下一个要讨论的问题。规模是一个必要但不充分的因素。有些模型足够大(比如 OPT 和 BLOOM,都是 175B),但并不能做思维链。- GPT3 系列的模型,包括 text-davinci-002 和 code-davinci-002 (Codex)。这是仅有的两个具有强大突现能力并可公开访问的模型。?
- ?除了以上两个模型,其他 GPT3 模型,包括原来的 GPT3,text-davinci-001,以及其他更小的 GPT-3 模型,都不能做思维链。
- 当说 “能做思维链” 时,我们是指使用思维链方法的效果比直接用提示词、精调 T5-11B 效果更好。
- 另外要注意的是,code-davinci-002 在语言任务上的性能始终优于[34] text-davinci-002。这个观察非常有趣且耐人寻味。这表明基于代码数据训练的语言模型可以胜过根据语言训练的语言模型。目前为止我们还不知道是为什么。
- PaLM 系列模型,包括 PaLM、U-PaLM、Flan-PaLM 和 Minerva。这些模型目前还未开放访问(此处 @谷歌,快开源吧)。
为什么会有突现能力目前还不清楚,但我们找出了一下可能产生突现能力的因素:- 指令精调:GPT-3 text-davinci-002 就是用指令 + 强化学习[35]?精调的产物。在这之前,text-davinci-001 做思维链的效果并不好。同时 PaLM[36]?在经过指令精调后[37]的效果也有提升。
- 在代码上精调:Codex code-davinci-002 是在代码上进行精调的,它的效果持续好于 text-davinci-002。PaLM 也在代码上进行了调整。从表面上看,代码与语言关系不大,但似乎起了很大作用,我们会在之后的文章进行讨论。
- 用思维链精调:在 text-davinci-002 发布时,谷歌已经发布 PaLM 3 个月了。所以 OpenAI 应该看到了思维链相关的工作。还有一些工作[38]?表明,直接用思维链数据进行精调可以激发模型的思维链能力。
然而,所有这些因素在现阶段都是推测。揭示如何训练才能让模型产生突现能力是非常有意义的,我们将更多讨论留到下一篇文章。在本文中,我们仔细研究了语言模型的突现能力。我们强调了复杂推理、知识推理和分布外鲁棒性的重要性和其中存在的机会。突现能力是非常令人兴奋的,因为它们可以超越比例定律,并在比例曲线中表现出相变。我们详细讨论了研究范式是否会真的从精调转向上下文学习,但我们目前还没有确切答案,因为精调和上下文学习在分布内、分布外场景下的效果仍有待对比。最后,我们讨论了产生突现能力的三个潜在因素:指令精调、代码精调和思维链精调。非常欢迎大家提出建议和讨论。- 我们是如何训练大模型,才能让模型具备突现能力、思维链能力?
[1] https://www.jasonwei.net/blog/emergencehttps://www.yitay.net/blog/emergence-and-scaling[2] Wei et. al. 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models?[3] https://lingo.csail.mit.edu/blog/arithmetic_gpt3/[4] Wei et. al. 2022. Emergent Abilities of Large Language Models?[5] 截止到 2022 年 11 月,仍没有严格的证据表明这些能力存在于小模型?[6] 在 2022 年 11 月,在 text-davinci-002 上评估 GSM8K 测试集需要 $50?[7] Google 不提供对 PaLM 的公共访问;OpenAI 不允许一些国家的研究人员访问 GPT3 和 Codex(截至 2022 年 11 月)?[8] GPT-3 的第一个版本(2020 年 5 月)在许多任务上无法胜过精调 T5?[9]? Wei et. al. 2022. Emergent Abilities of Large Language Models.?[10] Cobbe et. al. 2021. Training Verifiers to Solve Math Word Problems?[11]? GPT3 一直在持续更新。最新版本 text-davinci-002 现在与 2020 年的原始版本有很大不同。?[12] Wei et. al. 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models?[13] Wang et. al. 2022. Self-Consistency Improves Chain of Thought Reasoning in Language Models?[14]? Fu et. al. 2022. Complexity-Based Prompting for Multi-step Reasoning?[15]? 目前还没有能公平对比提示词和微调的工作。但当思维链被提出的时候,尽管他们对于提示和精调的比较可能是不公平的,但它们比精调效果要好。?[16] Chung et. al. 2022. Scaling Instruction-Finetuned Language Models?[17] Lewkowycz et. al. 2022. Minerva: Solving Quantitative Reasoning Problems with Language Models?[18]? Jiang et. al. 2022. Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs?[19] Xu et. al. 2021. Fusing Context Into Knowledge Graph for Commonsense Question Answering?[20] Khashabi et. al. 2020. UnifiedQA: Crossing Format Boundaries With a Single QA System?[21] Yu et. al. 2022. Generate rather than Retrieve: Large Language Models are Strong Context Generators?[22] Jung et. al. 2022. Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations?[23]? 虽然这些知识可能过时或者不可信,但选择哪种可信知识源超出了本文的讨论范围?[24] Si et. al. 2022. Prompting GPT-3 to be Reliable.?[25] Fu et. al. 2022. Complexity-based Prompting for Multi-Step Reasoning?[26] Kaplan et. al. 2020. Scaling Laws for Neural Language Models?[27] Brown et. al. 2020. anguage Models are Few-Shot Learners.?[28] Cobbe et. al. 2021. Training Verifiers to Solve Math Word Problems?[29] Li and Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation?[30] He et. al. 2021. Towards a Unified View of Parameter-Efficient Transfer Learning?[31] Chung et. al. 2022. Scaling Instruction-Finetuned Language Models?[32]? Suzgun et. al. 2022. Challenging BIG-Bench tasks and whether chain-of-thought can solve them?[33]? 在本文发布的两个月之后,更多的模型被公布,很多新的模型也都可以做思维链,比如 UL2, FlanT5?[34]? Suzgun. et. al. 2022. Challenging Big-Bench tasks and whether chain-of-thought can solve them?Fu et. al. 2022. Complexity-Based Prompting for Multi-Step Reasoning?Madaan et. al. 2022. Language Models of Code are Few-Shot Commonsense Learners?[35]? Ouyang et. al. 2022. Training language models to follow instructions with human feedback?[36]? Chowdhery et. al. 2022. PaLM: Scaling Language Modeling with Pathways?[37]? Chung. et. al. 2022. Scaling Instruction-Finetuned Language Models?[38]? Chung. et. al. 2022. Scaling Instruction-Finetuned Language Models?Huang et. al. 2022. Large Language Models Can Self-Improv
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
??如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/













 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





