
哪个更好:一个通用模型还是多个专用模型?
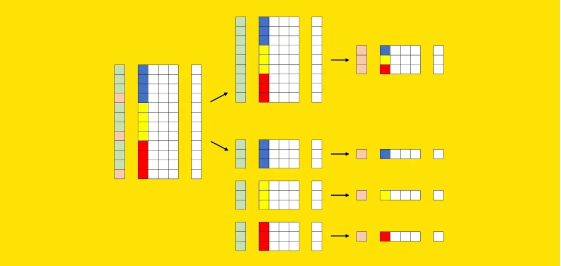
将所有数据提供给一个模型,也就是一个通用模型(general model); 为每个细分市场构建一个模型(在前面的示例中,品牌和国家/地区的组合),也就是许多专业模型(specialized models)。
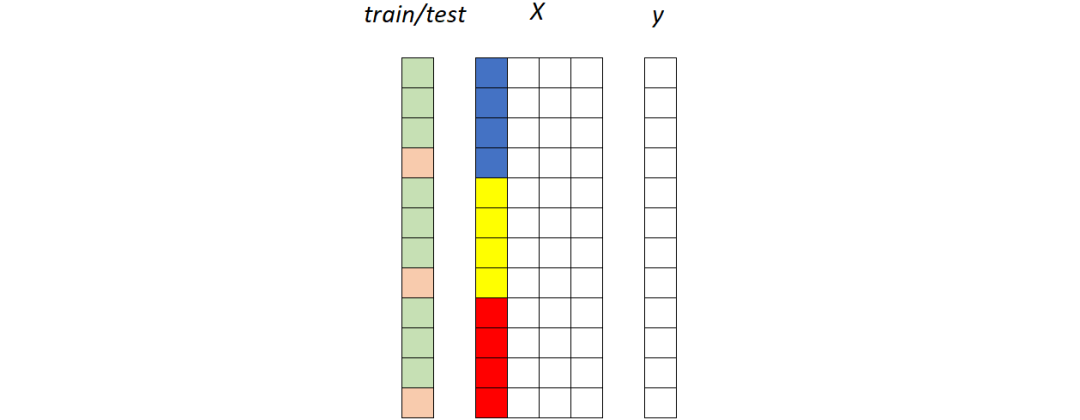
通用模型与专用模型

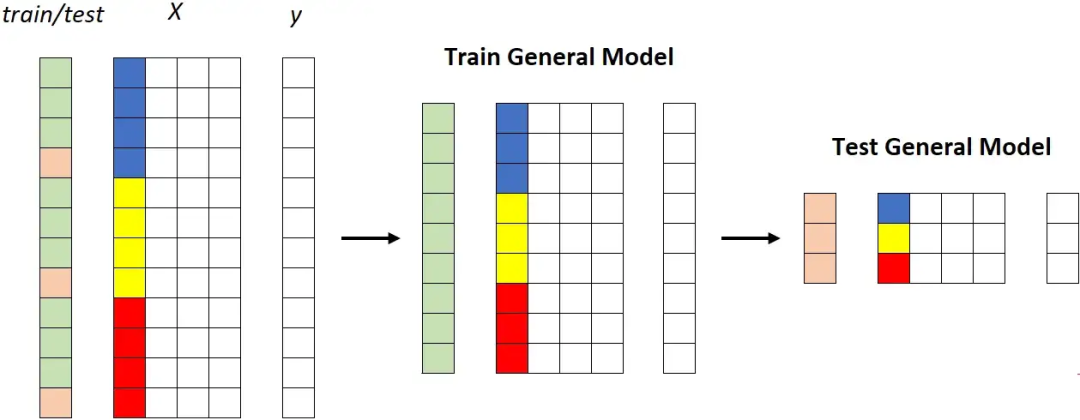
第一种策略:通用模型
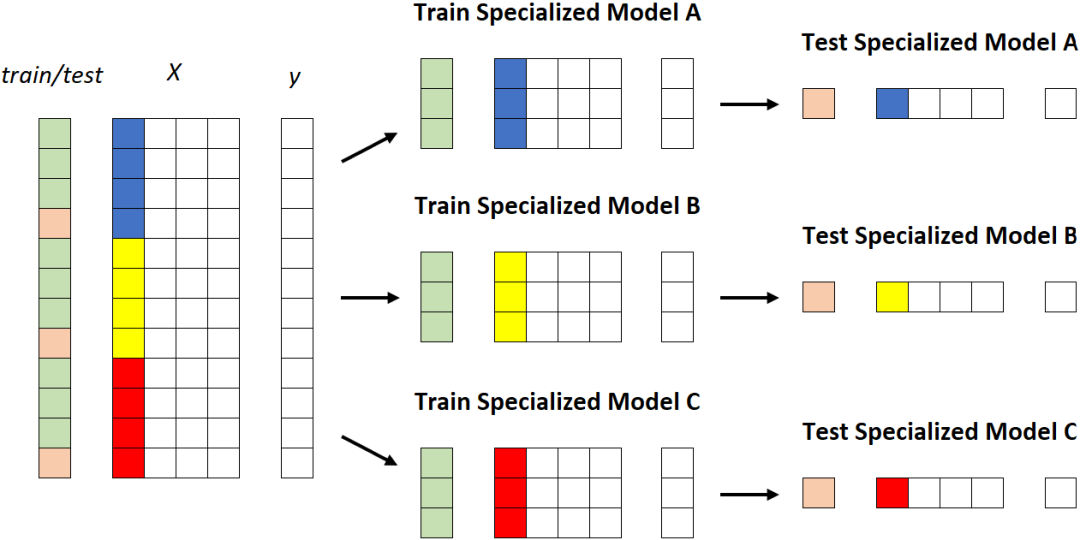 专用模型。每个段被馈送到不同的模型。[作者图片]
专用模型。每个段被馈送到不同的模型。[作者图片]更高的维护工作量; 更高的系统复杂度; 更高的(累积的)培训时间; 更高的计算成本: 更高的存储成本。
对通用模型的偏见
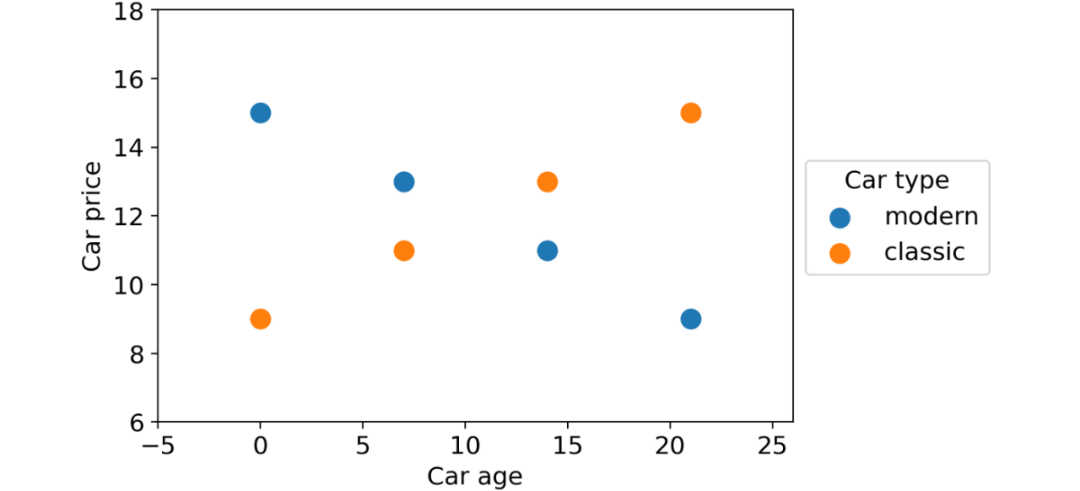
汽车类型(经典或现代); 汽车时代; 车价。
linear_regression?=?LinearRegression().fit(df[[?"car_type_classic"?,?"car_age"?]],?df[?"car_price"?]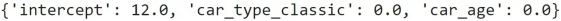
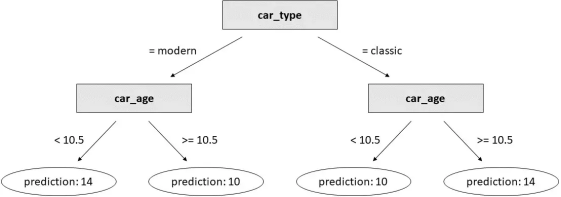
decision_tree = DecisionTreeRegressor(max_depth= 2 ).fit(df[[ "car_type_classic" , "car_age" ]], df[ "car_price" ])
?
实验细节
训练一个通用模型; 训练许多个专用模型。
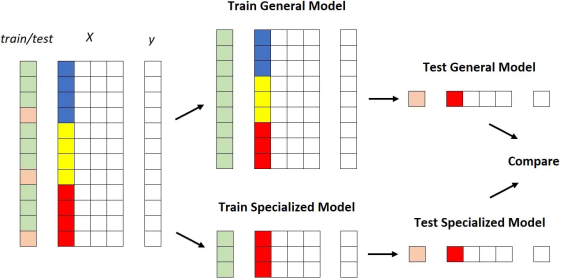
对于不同的数据集; 使用不同的列来分割数据集本身; 使用同一列的不同值来定义段。
for each dataset:train general model on the training setfor each column of the dataset:for each value of the column:train specialized model on the portion of the training set for which column = valuecompare performance of general model vs. specialized model
for dataset_name in tqdm(dataset_names):# get datay, num_features, cat_features, n_classes = get_dataset(dataset_name)# split index in training and test set, then train general model on the training setix_test = train_test_split(X.index, test_size=.25, stratify=y)model_general = CatBoostClassifier().fit(X=X.loc[ix_train,:], y=y.loc[ix_train], cat_features=cat_features, silent=True)pred_general = pd.DataFrame(model_general.predict_proba(X.loc[ix_test, :]), index=ix_test, columns=model_general.classes_)# create a dataframe where all the columns are categorical:# numerical columns with more than 5 unique values are binnizedX_cat = X.copy():, num_features] = X_cat.loc[:, num_features].fillna(X_cat.loc[:, num_features].median()).apply(lambda col: col if col.nunique() <= 5 else binnize(col))# get a list of columns that are not (statistically) independent# from y according to chi 2 independence testcandidate_columns = get_dependent_columns(X_cat, y)for segmentation_column in candidate_columns:# get a list of candidate values such that each candidate:# - has at least 100 examples in the test set# - is not more common than 50%vc_test = X_cat.loc[ix_test, segmentation_column].value_counts()nu_train = y.loc[ix_train].groupby(X_cat.loc[ix_train, segmentation_column]).nunique()nu_test = y.loc[ix_test].groupby(X_cat.loc[ix_test, segmentation_column]).nunique()candidate_values = vc_test[(vc_test>=100) & (vc_test/len(ix_test)<.5) & (nu_train==n_classes) & (nu_test==n_classes)].index.to_list()for value in candidate_values:# split index in training and test set, then train specialized model# on the portion of the training set that belongs to the segmentix_value = X_cat.loc[X_cat.loc[:, segmentation_column] == value, segmentation_column].indexix_train_specialized = list(set(ix_value).intersection(ix_train))ix_test_specialized = list(set(ix_value).intersection(ix_test))model_specialized = CatBoostClassifier().fit(X=X.loc[ix_train_specialized,:], y=y.loc[ix_train_specialized], cat_features=cat_features, silent=True)pred_specialized = pd.DataFrame(model_specialized.predict_proba(X.loc[ix_test_specialized, :]), index=ix_test_specialized, columns=model_specialized.classes_)# compute roc score of both the general model and the specialized model and save themroc_auc_score_general = get_roc_auc_score(y.loc[ix_test_specialized], pred_general.loc[ix_test_specialized, :])roc_auc_score_specialized = get_roc_auc_score(y.loc[ix_test_specialized], pred_specialized)=?results.append(pd.Series(data=[dataset_name,?segmentation_column,?value,?len(ix_test_specialized),?y.loc[ix_test_specialized].value_counts().to_list(),?roc_auc_score_general,?roc_auc_score_specialized],index=results.columns),ignore_index=True
结果
?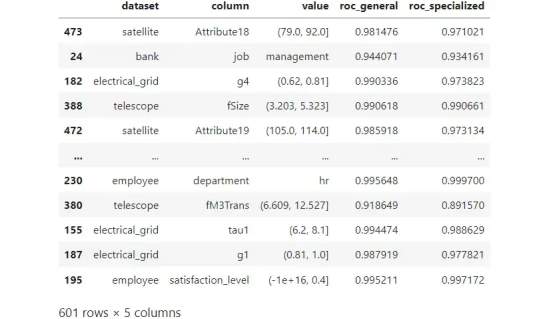 ?
?
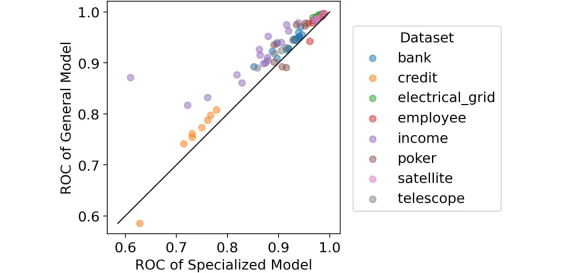
结论
https://towardsdatascience.com/what-is-better-one-general-model-or-many-specialized-models-9500d9f8751d??

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675