
拳打DALL-E 2脚踢Imagen,谷歌最新Muse模型刷新文本图像合成排行榜
 大数据文摘授权转载自将门创投
大数据文摘授权转载自将门创投近期火爆AI社区的文本图像合成模型家族又添新成员了,之前在这一领域占据上风的是以DALL-E 2[1]和Imagen[2]为代表的扩散模型,以及以Parti[3]为代表的自回归模型。为了进一步提升文本图像合成任务的效率,近日,谷歌研究院再度发布全新基于生成式Transformer架构的Muse模型。不得不说,这一领域发展实在是太卷太快了。

论文链接:
项目主页:
https://muse-model.github.io/
谷歌研究团队已经宣布,Muse模型目前已成为这一领域的新SOTA。
Muse在训练过程中加入了Mask建模任务,首先给定从预训练的大型语言模型(LLMs)中提取的文本嵌入,Muse会根据文本内容来预测生成随机Mask掉的图像tokens。与DALL-E 2和Imagen等像素空间扩散模型相比,Muse基于离散tokens的训练模式大大减少了模型迭代次数,与Parti等自回归模型相比,作者设计的并行编码方式有效提高了模型的生成效率。
此外,Muse可以从预训练的LLMs中获取细粒度的语言知识,从而转化为高精度的视觉概念识别能力。下面展示了一些Muse的文本图像生成效果。

Muse可以让”两个宇航员在埃菲尔铁塔前踢足球“,也可以让”两只喵喵一起做科学研究“。每张示例图像都展现了非常生动有趣的图像生成效果,并且每张图像都可以使用一张TPUv4在1.3秒内生成。
而对于AIGC应用的必备功能,图像编辑任务,Muse也可以胜任。用户可以指定一个Mask区域,随后输入编辑指令,如下图所示,Muse就可以直接将Mask区域更换为纽约或者巴黎。作者还强调,Muse无需对模型进行微调即可实现上述图像编辑功能,实现了”开箱即用“。

引言
以扩散模型为代表的文本图像合成模型的爆火,背后离不开新颖的深度学习训练范式,例如对语言和图像两种模态的Mask建模和重构任务等。但是这些工作需要极高的训练成本,而且在推理时仍然费事费力。本文提出的Muse模型在不损失图像生成效果的基础上,主打的就是模型推理效率。
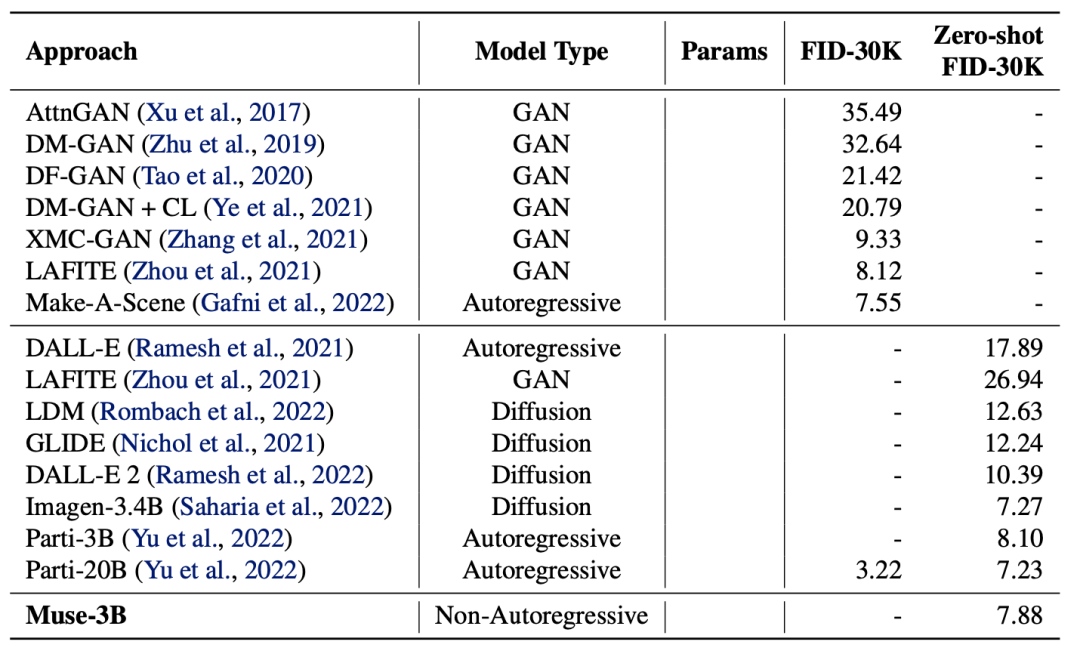
Muse凭借离散token编码和推理时的并行解码机制,在相同的硬件条件下(例如TPU-v4芯片)比Imagen-3B或Parti-3B模型的推理速度快10倍以上,比Stable Diffusion v1.4快3倍。此外,Muse为了同时兼顾生成图像的高层语义和低层图像细节,加入了双分辨率编码解码的机制,即同时对每张图像的256x256和512x512分辨率版本进行操作,尽管这样,Muse仍然相比其他扩散模型有明显的速度优势。虽然Muse主打模型效率,但是其图像合成质量仍然非常具有竞争力,Muse在目前公认的文本图像合成基准CC3M上以达到了6.06的FID分数,是目前业内的最高水平。
本文方法
之前的扩散模型或者自回归模型均需要庞大的参数量来存储从海量文本图像数据学习到的知识,这加重了模型的训练负担以及部署成本。Muse的提出,标志着另一种新型图像文本框架模式的诞生,作者将其概括为掩码生成式Transformer架构,即在训练时将输入图像的一部分像MAE那样随机Mask掉,然后设计预训练的文本任务来进行重构学习。下图为Muse的整体框架,其中内置了一个预训练文本编码器来对输入prompt进行编码,还包含一对VQGAN tokenizer模型,用来将输入图像编码为一系列离散tokens,两个VQGAN分别处理低分辨率(256x256)和高分辨率(512x512)。此外作者还设计了一个SuperRes Transformer,负责将低分辨率token转换为高分辨率token,实现超分辨率功能。下面我们将详细介绍这些模块。
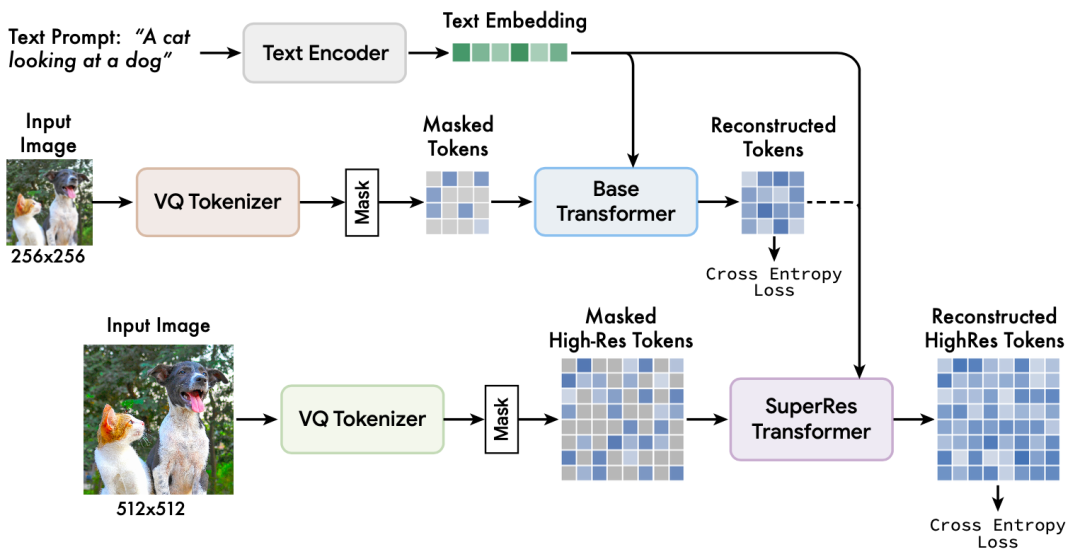
2.1 预训练文本编码器
作者在模型构建过程中发现,使用预训练的LLMs非常有利于生成高质量的图像,从LLMs中可以提取到图像中有关对象(名词)、动作(动词)、视觉属性(形容词)、空间关系(介词)和其他属性的丰富信息。因此作者在这里内置了一个预训练的T5-XXL[4]编码器,并且冻结其参数,可以对输入文本prompt进行编码,产生维度为4096的语言嵌入向量,这些向量随后被投影到下游的Transformer模型中。
2.2 VQGAN生成离散tokens
2.3 基础模型
2.4 超分辨率Transformer

2.5 动态遮蔽率和迭代并行编码

实验结果



总结
参考:
[1] Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
[2] Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., Ghasemipour, S. K. S., Ayan, B. K., Mahdavi, S. S., Lopes, R. G., et al. Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487, 2022.
[3] Yu, J., Xu, Y., Koh, J. Y., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B. K., et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789, 2022.
[4] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P. J., et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67, 2020.

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

![胡允恩中秋节大家吃月饼了嘛?祝大家中秋节快乐[心]](https://imgs.knowsafe.com:8087/img/aideep/2021/9/21/0df66dd32d4a9c80391c0c488cf486b7.jpg?w=250)




 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675