
Absolut! 能不受约束地生成抗体-抗原结构,指导用于抗体特异性预测的机器学习方法
机器学习 (ML) 是准确预测抗体-抗原结合的关键技术。两个正交问题阻碍了 ML 在抗体特异性预测及其基准测试中的应用:缺乏免疫抗体特异性预测问题的统一 ML 形式化,以及无法使用大规模合成数据集来对现实世界相关的 ML 方法和数据集设计进行基准测试。
奥斯陆大学 (University of Oslo) 的研究人员开发了 Absolut! 软件套件,能够基于参数不受约束地生成基于合成的晶格三维抗体-抗原结合结构,并具有对构象互补位、表位和亲和力的地面实况访问。
研究人员将常见的免疫抗体特异性预测问题形式化为 ML 任务,并确认对于基于序列和基于结构的任务,基于实验数据训练的 ML 方法的基于准确性的排名适用于基于 Absolut! 生成的数据训练的 ML 方法。Absolut! 框架有可能实现生物治疗设计的 ML 策略的现实世界相关开发和基准测试。
该研究以「Unconstrained generation of synthetic antibody–antigen structures to guide machine learning methodology for antibody specificity prediction」为题,于 2022 年 12 月 19 日发布在《Nature Computational Science》。

抗体疗法在感染、癌症和自身免疫的治疗方面取得了令人瞩目的医学突破。抗体通过三维 (3D) 结合界面以高特异性结合外来分子(抗原),该界面由抗体侧的互补位和抗原侧的表位决定。抗体 CDRH3(重链的互补决定区三)区域主要对互补位有贡献。在原子水平上解析的 3D 抗体-抗原复合物代表了描述抗体-抗原结合的黄金标准,但它们的生成需要大量时间和成本。目前,只有大约 10^3 个非冗余抗体-抗原结构,这比抗体序列的多样性 (>10^13) 小很多数量级。
此外,对于大多数 3D 结构数据集和从库或基于库的筛选方法获得的抗原特异性抗体序列,亲和力值仍然不可用。缺乏结构性抗体-抗原结合数据,加上抗体-抗原结合和蛋白质-蛋白质对接的复杂性,是抗体-抗原结合预测仍未解决的一些主要原因。
预测抗体特异性是指识别哪些抗体序列或结构与哪些抗原结合,反之亦然。特别是,预测抗体-抗原对的 3D(构象)互补位或表位对于解决计算抗体和疫苗设计中长期存在的问题至关重要。机器学习 (ML) 越来越多地用于抗体-抗原结合预测,因为它能够推断出高复杂性蛋白质-蛋白质相互作用背后隐藏的非线性规则;规则包括结合界面氨基酸之间的长距离依赖性。
此类 ML 方法包括基于序列的互补位预测和互补位-表位链接预测,但结构信息的包含程度各不相同。如果有足够大的抗原(表位)特异性抗体数据集可用,则基于结构或序列的结合预测可能是可行的。目前,ML 应用程序是在非常小或不完整的知识数据集上开发的(互补位、表位和亲和力的联合信息不可用,数据集的大小通常小于 10,000 个抗体)。受限的实验数据集既不允许对 ML 方法进行基准测试和压力测试,也不允许验证 ML 结论是否推广到其他数据集。
模拟允许生成合成的完整知识地面实况数据集(即生成规则已知并因此包含要学习的验证属性的数据集),其中包含反映实验设置和生物学机制的所需信号和噪声水平。在大规模数据集可用于理清 ML 假设和确定未来实验设计的优先级之前,模拟数据集已用于方法论开发和校准。对于抗体-抗原结合预测,模拟可能有助于准确而有意义地定义不同的真实世界抗体-抗原结合问题,这需要实验数据中尚不可用的注释级别。
此外,真实完整知识数据集的模拟对于基准测试或排名 ML 预测策略至关重要。由于 ML 编码跨越序列到结构再到混合形式化,模拟的抗体-抗原数据集需要:(1) 概括实验性抗体-抗原结合的复杂结构水平(尤其是定义互补位和表位);(2) 能够生成大规模数据集;(3) 允许将序列和结构信息整合到混合编码中。
在这里,奥斯陆大学的研究团队提供了确定性 3D 抗体-抗原结合模拟框架 Absolut!,它支持在参数化的大规模数据集上进行 ML 方法开发和形式化。合成抗体-抗原结构是作为 3D 晶格中能量最佳的结合结构生成的,并概括了抗体-抗原结合生理学固有的许多复杂程度。它们允许对各种类型的 ML 架构和数据集设计进行基准测试,这些设计在很大程度上无法通过实验生成。



值得注意的是,Absolut! 既不适合也不旨在直接预测抗体序列是否以及在何处与现实世界中的抗原结合。相反,Absolut! 的开发前提是,针对实验(现实世界)数据集的成功 ML 抗体结合策略也应该在合成数据集上表现良好(反之亦然)。
因此,合成数据集应该足够复杂,以便可以将基于准确性的 ML 方法排名从合成数据集转移到实验数据集。具体来说,研究人员生成了 690 万个鼠类 CDRH3 序列与 159 种抗原(约 10 亿个抗体-抗原结合对)的合成结合结构,该团队通过三个例子,研究了在多大程度上需要 1D 序列和 3D 结构信息来实现抗体-抗原结合的高预测准确性:结合的二元和多类分类,以及互补位-表位预测。研究人员发现,在计算机上研究的条件预测会增加抗体特异性预测,这反映了 ML 在实验抗体-抗原序列和结构数据上的性能。

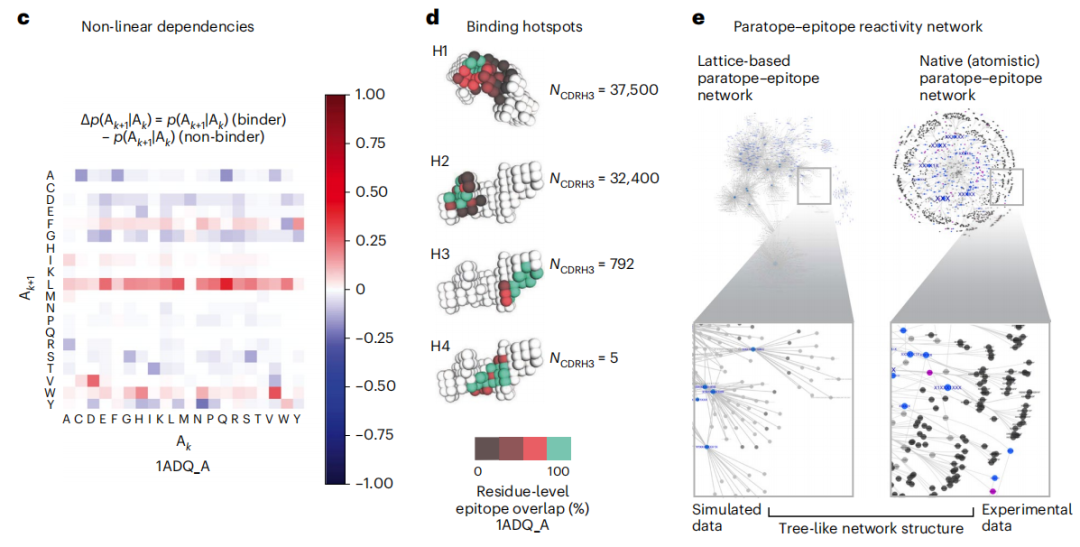
研究表明,Absolut! 数据集概括了实验性抗体-抗原数据集中存在的八个复杂性级别,改进了先前广泛使用的抗体-抗原结合的或多或少的抽象粗粒度表示。事实上,变分自动编码器 (VAE) 生成的针对不同抗原的单特异性结合序列的潜在空间并没有聚集抗原特异性抗体,而是聚集了相似的抗体序列,突出了结合规则的复杂性超出了 Absolut! 数据集中存在的相似性。
尽管经过训练的模型在互补位-表位预测方面实现了很高的预测精度,但研究人员观察到,在训练中预测未见实例是一项重大挑战,并且准确性是由与其他合作伙伴在训练数据集中描述的表位驱动的。由于互补位-表位预测的编码相似性,数据泄漏的影响很小,这表明可以学习绑定规则,而不仅仅是相似性。
尽管 Absolut! 框架包括上述水平的复杂性,但考虑到真实世界的抗体-抗原结合的主要局限性是:(1)蛋白质不符合固定的氨基酸间距离和严格的 90° 角;(2) 不包括溶剂化、电荷的 3D 分布和取决于结合抗体的抗原结构的可能灵活性;(3) 仅模拟了 CDRH3 环(与完整的重链和轻链相反),这是抗体特异性最可变的链,因此忽略了与其他 CDR 环或恒定区的拓扑限制。
因此,Absolut! 合成数据生成不允许对原子分辨率数据集的 ML 方法进行基准测试,也不允许在微调之前依赖现有结构工具(如 AlphaFold2)进行训练的方法。不考虑具有不同水平体细胞超突变的亲和力成熟数据集。使用相同的离散化抗原从生发中心模拟生成亲和力成熟库,有助于理解 ML 方法是否使用体细胞超突变模式来识别高亲和力序列而不是结合规则本身。
随着这些数据集规模的增加,在合成数据集上训练的模型有越来越多地学习合成设计偏差的风险,不能排除这种情况。Absolut! 数据集上的超参数优化或 ML 策略的广泛开发也可能有利于更适应此类偏差的模型。然而,只有在降低可迁移性的情况下,学习偏差才是一个问题。

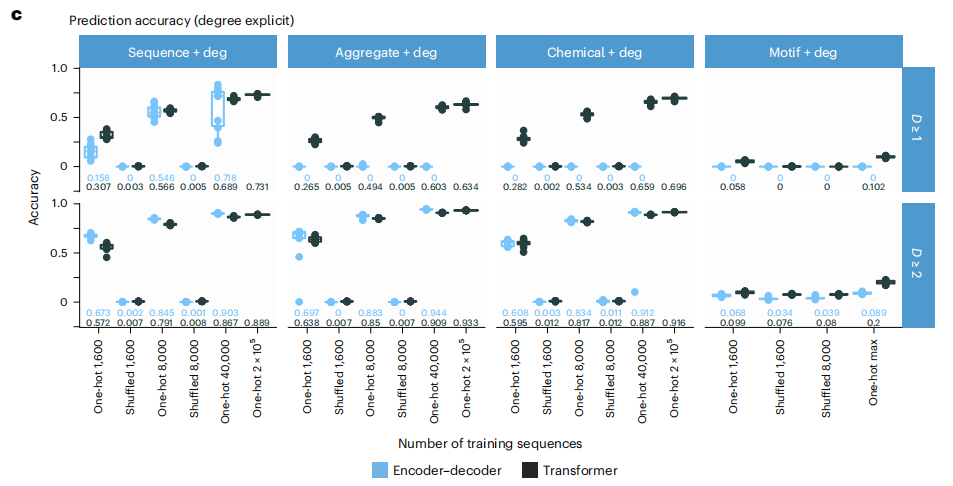
由于在该研究所示的一系列特定用例中观察到了 ML 方法排名的可转移性,因此它支持这样一种观点,即对于测试的用例,偏差在一定程度上可以忽略不计。此外,大型数据集上序列编码的低互补位-表位预测准确性表明 ML 模型无法学习晶格偏差。生成具有增强(结构对接)或降低复杂性的合成数据集将揭示模拟精度与可转移性的相对影响。
Absolut! 框架未来可能的改进如下:(1) 在晶格框架内,可以在连续的氨基酸组中添加局部几何或角度约束。(2) 90°角可以细化为更大的一组角。(3) 几何约束可以包含在 CDRH3 的末端之间。(4) 在多个循环之间包含结构约束可以同时模拟 CDRH3 和 CDRL3 链,尽管目前其计算成本似乎不切实际。(5) 一旦有更多的实验亲和力分布可用,就可以包括相邻氨基酸的能量贡献之间的其他能量势或非线性。基于对接的亲和力不直接适用于此目的。
总而言之,即使存在未来的大型真实世界数据集,模拟方法也将保留其用于评估和理解 ML 方法稳健性和相对排名的有用性。
论文链接:https://www.nature.com/articles/s43588-022-00372-4
人工智能?×?[?生物 神经科学?数学 物理 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/



![蔡文静很开心的一晚 [比耶]@时尚芭莎 #芭莎无界电影之夜# ](https://imgs.knowsafe.com:8087/img/aideep/2025/7/26/b9503ee2b7df177e142445f19903f3bf.jpg?w=250)


 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675