
NLP 中的语言模型,动辄涉及百亿参数,为何需要这么大的模型呢?近日,Google 研究者发表了题为“大型语言模型的涌现能力”(Emergent Abilities of Large Language Models)的论文,考察了以 GPT-3 为代表的语言模型,发现语言模型的表现并非随着模型规模增加而线性增长,而是存在临界点,只有当模型大到超过特定的临界值,才会涌现出较小的模型不具备的能力。语言模型的这种涌现能力意味着,大型语言模型可能进一步扩展语言模型的功能。
论文标题:
Emergent Abilities of Large Language Models
论文链接:
https://openreview.net/forum?id=yzkSU5zdwD
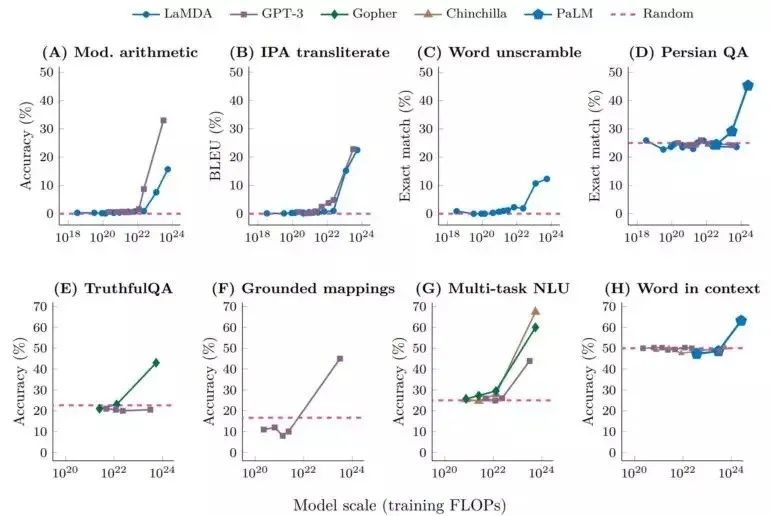
在过去二十年里,人工智能领域的大部分研究都集中在训练神经网络来完成一个特定的任务,例如,分类一张图片是否包含一只猫,总结一篇新闻文章,中英文翻译等。然而近年来 NLP 的进展,得益于语言模型,它根据句子中先前出现的单词,简单地预测句子中下一个单词。经过海量数据训练后,语言模型可以被“提示”执行任意的任务。例如,将一个英语短语翻译成斯瓦希里语的任务,可以被重新定义为下一个单词的预测: ‘人工智能’的法语翻译是......?语言模型代表了一种范式转变,从训练基于特定任务的模型,到训练可执行多任务的模型。例如,GPT-3 表明,语言模型可以成功地进行两位数乘法,即使它们没有被明确地训练这样做。然而,这种执行新任务的能力只发生在具有一定数量的参数、并在足够大的数据集上进行训练的模型中。这样的涌现现象在复杂系统中普遍出现。例如当生态系统的复杂性降低到阈值之下时,系统的稳定性会显著降低。最早指出该现象的,是菲利普·安德森的经典论文“多者异也”。涌现指的是一个研究对象表现出组成它的部分要素本身所不具备的特性。例如,这些行为或能力只有通过各个部分的相互作用才能显现出来。该研究中,作者对语言模型的涌现能力给出了如下定义:“如果一种能力不存在于较小的模型中,而存在于较大的模型中,那么这种能力就是涌现出来的。”可以通过不同的方式对模型大小进行测量,包括训练时计算量(FLOPs)、参数数量或训练数据大小。图1显示了涌现能力的三个例子:运算能力、参加大学水平的考试(多任务 NLU),以及识别一个词的语境含义的能力。在每种情况下,语言模型最初表现很差,并且与模型大小基本无关,但当模型规模达到一个阈值时,语言模型的表现能力突然提高。图1. 在多步计算、多任务语言理解和语境中的词汇含义三任务上,语言模型的准确度只有当模型规模(训练时的FLOPs)超过一个阈值时才突然提高。另一类涌现能力包括提示策略(prompting strategy)以增强语言模型的能力。这些策略之所以出现,是因为较小的模型无法成功地使用这些策略,只有足够大的语言模型才可以。例如“思维链提示”(chain-of-thought prompting),其中模型被提示在给出最终答案之前生成一系列中间步骤。图2A总结了思维链提示ーー它显著提高了大型语言模型的推理能力,使它们能够解决需要抽象推理的多步骤问题。如图2B所示,在一个小学数学问题的基准上,思维链提示比直接返回最终答案要差,直到模型大小达到一个临界值(1022?FLOPs),之后模型的表现会好得多。图2. (A) 思维链提示的案例,(B) 模型大小和思维链提示带来的准确性折线图。研究者发现,语言模型的涌现能力是一个普遍现象而非特例,文中总结了GPT-3模型具有的137项涌现能力,对于更传统的NLP基准模型,例如 BIG-Bench,其具有的涌现能力也包括67项。图3展示了不同模型在多种任务上,准确性和模型大小都呈现相变(phase transition)。而另一项相关研究,关注GPT-3在类比推断上的涌现能力,发现在抽象模式归纳、匹配等需要类比思维的问题上,足够大的语言模型即使没有直接训练,也可以展现出超越人类的准确性。Emergent Analogical Reasoning in Large Language Modelshttps://arxiv.org/abs/2212.09196
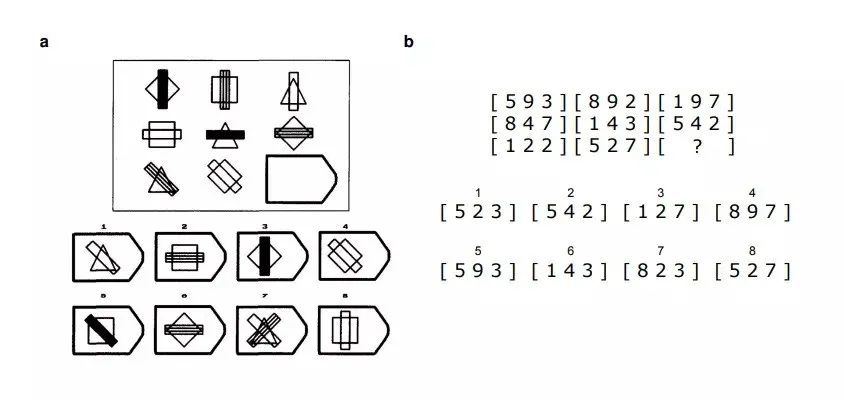
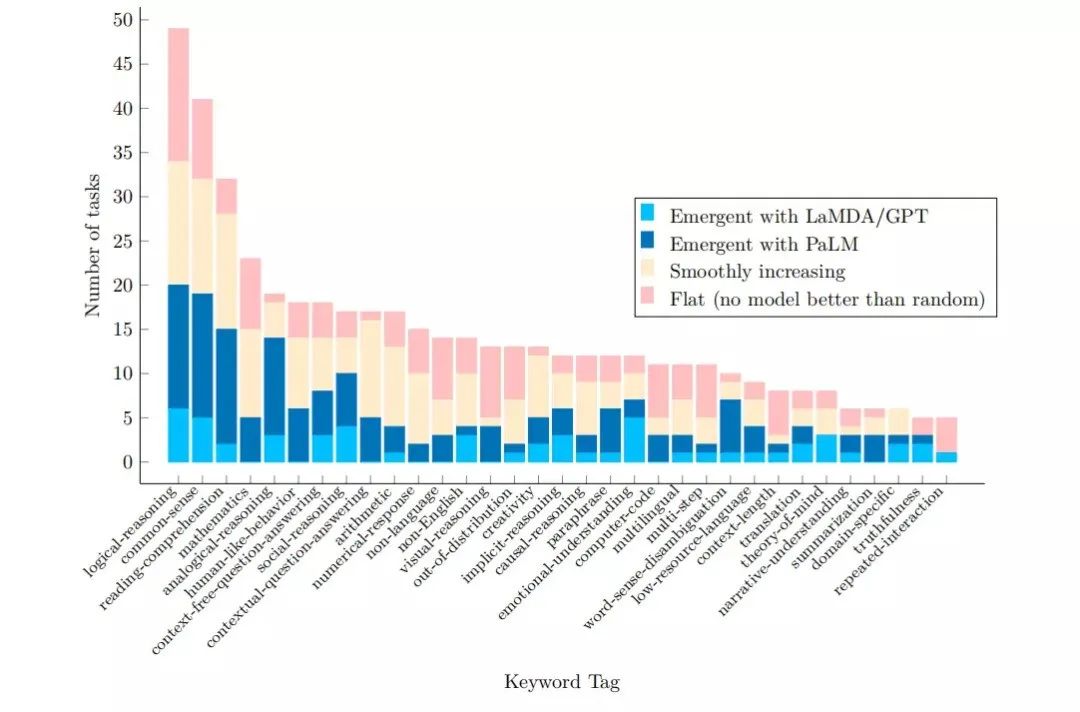
图5. 在生成及多选这两类问题上,需要运用的规则越多,GPT-3 的表现就越优于人类语言模型之所以必须足够大,才能进行类比推理,可以用解决问题需要的规则必须存储在足够多的参数中加以解释。例如需要同时使用三条规则进行类比的问题,就需要模型的参数能同时存储三条规则。然而语言模型的类比能力完全来自于预测人类文本,语言充满了类比,因此准确地预测自然语言可能需要一种能力。但是我们没有理由假设同样的系统,如果没有人类产生的输入,会自发形成类比式的思维能力。在某种程度上,大型语言模型捕获了成年人类的类比能力,它们的类比能力从根本上来说寄生在人类的自然智力上。语言模型的涌现能力,也并非全然是好事,语言模型带来的社会问题,例如歧视女性、不文明用语等,也具有涌现的特性。即当模型较小时不会出现,只有模型足够大时才会呈现。可以肯定的是,在可预见的未来,大型语言模型仍将是机器学习研究的主流。语言模型在零次学习(zero shot learning)上的涌现能力,已让它们得以进入实际应用领域(例如chatGPT),并在自然语言处理研究领域之外有许多新的应用。例如,语言模型通过提示将自然语言指令转换为机器人可执行操作的命令,或促进多模态推理(根据文字作画)。为此,我们需要继续研究它们的涌现能力和局限性,建立对涌现能力的一般性理解(目前缺少令人信服的解释),并探索未实现的潜力及最终极限。涌现能力具有重要的科学意义,如果涌现能力是没有尽头的,那么只要模型足够大,强 AI 的出现就是必然的。对现有语言模型涌现特征的研究发现,语言模型的表现和模型大小之间的关系是不可线性外推的,有理由相信,随着模型大小的增加,模型将会变得更加鲁棒。不同类型的任务中,具有涌现特征的比例相差巨大(图6),也不存在明确的趋势表明哪些类型的任务是最具涌现特征的。然而语言模型在逻辑推理和因果推断中,具有涌现特征的比例最低,可能反映了语言模型并没有真正把握因果关系。图6. 在BIG Bench模型中,在各类任务中,具有涌现特征(蓝色)、性能随模型大小线性增长(浅黄色)、以及所有模型都无法超过随机水平(橙红色)的任务个数。在类比推理、词义消歧、真实性、社会推理和情感理解这些任务中,具有涌现特征的任务比例最高;算术和数学相对较低;在逻辑推理、因果推理和视觉相关的任务中,具有涌现特征的任务比例最低。在论文中,研究人员讨论了语言模型的涌现能力面临的限制,包括硬件和数据瓶颈。有些能力甚至可能不会随着模型规模变大而出现,例如在远离训练数据集分布的任务上。此外,一旦某种能力出现,涌现特征并不能保证它会随着规模的扩大而继续提高。随着机器学习社区朝着创建更大的语言模型的方向发展,人们越来越担心大语言模型的研究和开发将集中在少数几个拥有财政和计算资源来训练和运行这些模型的组织中。通过对特定任务数据集的小型模型进行微调,可以使用小模型替代大语言模型。该研究的作者指出:一旦一种能力被发现,进一步的研究可能会使这种能力适用于小尺度模型。随着我们继续训练越来越大的语言模型,降低涌现能力发生相变的门槛,对于让社区更广泛地获得这种能力的研究将变得更加重要。未来关于涌现能力的研究方向包括训练更有能力的语言模型(例如改进模型结构和训练程序,可以促进具有涌现能力的高质量模型,同时减少计算成本;使用数据增强,在更小的模型上重现涌现能力),以及通过理解涌现能力的来源,开发可用于更好地支持语言模型执行任务的提示策略。研究者还可以使用交叉熵、困惑度(preplexity)等新的测量方式,研究语言模型及多模态模型的涌现能力。未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
??如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/











 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




