
针对日本网络钓鱼活动溯源分析

原文信息提取:
攻击方式:
攻击者冒充日本国家税务局针对日本用户分发钓鱼短信,包含诱导欺骗的文字以及指向恶意网站的短链接,后续会根据不同的设备类型去重定向到不同的钓鱼页面
iphone:重定向到克隆日本国家税务局的网站,通过伪造的弹窗提示,诱导用户填写个人身份信息和V-Preca卡详细信息 Android:重定向到虚假的"AU"(日本移动运营商)网站,诱导用户下载安装恶意apk从而达到进一步窃取信息的目的
差异在于Android比较容易从网页下载安装恶意程序,而iphone上如果直接使用网页安装软件比较麻烦且需要获得签名,成本更高,所以直接伪造钓鱼网站窃取个人信息
IOC:
手机号:09061661959
短链接:https://cutt.ly/YXZfAMP
apk:8b6c4fea9e4a6d8761c1c53525a91374
代理服务器:220105.top
C&C:192.186.11.120:6666
钓鱼网站:ntagoi-jp.qgvvtoq.cn
同时文章中也披露了很多针对东京国税局官网域名https://www.nta.go.jp的钓鱼网站,URL均以"ntagoi-jp"为子域名,通用格式为:"ntagoi-jp.[a-zA-Z0-9]{5,7}.cn"
威胁检测情报(IP和域名扩线):
从已知攻击行动中提取信息:
从已知IOC入手进一步挖掘/复现攻击链,以提取更多钓鱼网站相关信息
短链接(cutt.ly/YXZfAMP):
该短链接由cuttly生成,使用短链接的优势在于攻击者可以隐藏真实域名并且短链接的URL可以随时更改以规避静态检测,同时短链接后台可以统计链接的点击量,方便查看钓鱼效果,以短链接为出发点,尝试还原一下攻击者整条攻击链 首先需要确定的是短链接解析重定向到的真实域名地址,可以直接在浏览器中查看网络日志,或者可以直接通过攻击者生成短链接的平台cuttly的官方网站去解析
首先需要确定的是短链接解析重定向到的真实域名地址,可以直接在浏览器中查看网络日志,或者可以直接通过攻击者生成短链接的平台cuttly的官方网站去解析
重定向的域名:
(myffdvfuom.duckdns.org)
查看重定向到的第一个域名页面的代码,直接在前端使用Javascript再次进行重定向跳转到另一个页面
(ufjxfdxtbv.duckdns.org)
跳转到的这个新页面主要是对不同的手机设备类型做一个判断,根据http请求"UserAgent"中包含的"iPhone"或者是"Android"字段去进行匹配并分别跳转到不同的钓鱼页面,iphone设备将会跳转到一个新的域名,而安卓设备则直接跳转到当前域名的"78.html"页面 如果是使用电脑浏览器访问则因为无法在"UserAgent"中匹配到指定的字符串而无法继续重定向跳转,所以显示为空白页面,因为攻击者目标仅为Android和iPhone设备,所以仅有这2种设备类型会继续按照既定的流程访问攻击者设置的钓鱼页面,Windows平台访问页面被非主观的规避了
<!doctype?html>
<html>
<head>
????<meta?charset="utf-8">
????<title></title>
</head>
<body>
????<script>
????????if(navigator.userAgent.match(/(iPhone)/i)){
????document.location.href?=?"http://pkpmwlyrvz.duckdns.org";
????????}?else?if?(navigator.userAgent.match(/(Android)/i))?{
????????????document.location.href?=?"78.html";
????????}
????</script>
</body>
</html>
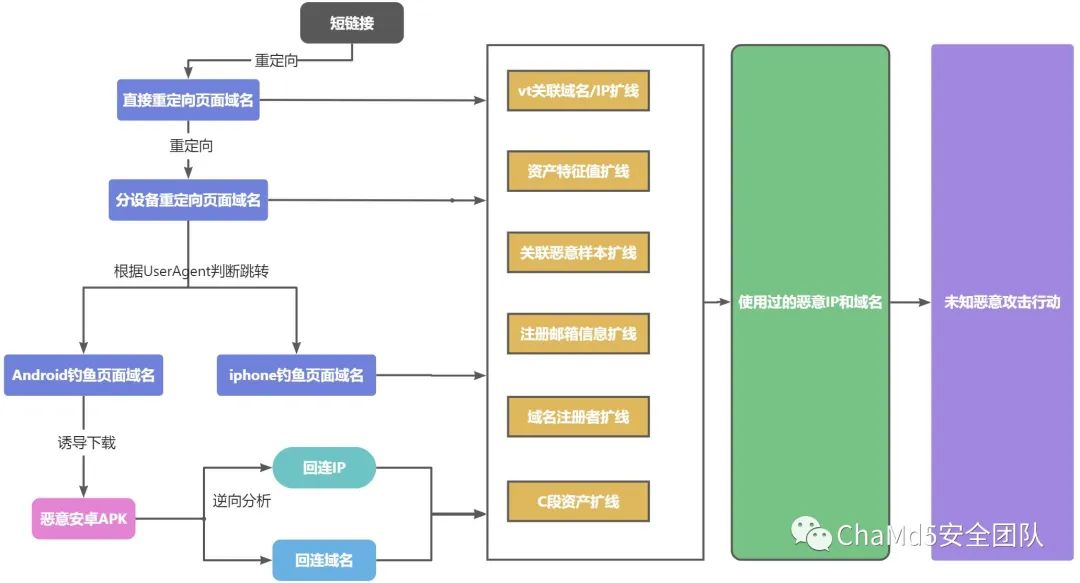
后续的钓鱼网站跳转都由这个"分设备重定向页面"控制,猜测攻击者可能需要定期对该页面进行代码更新维护从而变换重定向到的钓鱼页面链接,到目前为止,攻击者总共使用了三种类型的域名,"跳转重定向域名","iPhone钓鱼域名"和"Android钓鱼域名",据此根据具体域名和ip的关系及进一步情报挖掘和分析
| 类型 | 域名 | IP |
|---|---|---|
| 重定向页面 | myffdvfuom.duckdns.org | 103.80.134.89 |
| 分设备重定向页面/Android钓鱼页面 | ufjxfdxtbv.duckdns.org | 103.80.134.91 |
| iphone钓鱼页面 | pkpmwlyrvz.duckdns.org | 185.212.68.4 |
python提取攻击链中所有重定向域名:
目前来看,攻击者在此条攻击链中暴露的域名资产以及具体流程大致为: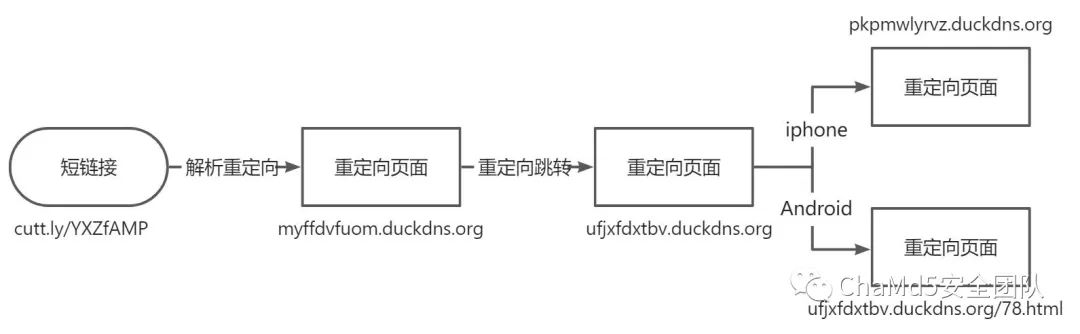 一般来说为了规避检测和黑名单,此类钓鱼域名数量大且存活时间不长,会经常更换域名,并且通过搜索域名解析到的IP发现大量类似攻击活动 以做威胁情报的目的来说,应该通过Python等自动化工具,编写出可以自动获取其重定向域名并储存的流程,方便后续提取关联相同类型的攻击活动,直接一步到位将重定向域名以及后续钓鱼域名全部保存下来
一般来说为了规避检测和黑名单,此类钓鱼域名数量大且存活时间不长,会经常更换域名,并且通过搜索域名解析到的IP发现大量类似攻击活动 以做威胁情报的目的来说,应该通过Python等自动化工具,编写出可以自动获取其重定向域名并储存的流程,方便后续提取关联相同类型的攻击活动,直接一步到位将重定向域名以及后续钓鱼域名全部保存下来
脚本逻辑:
按行读取指定文件中的url 发送请求并判断是否成功访问页面 直接重定向页面,提取10行的重定向链接并再次请求网页,重复上面的操作 分设备重定向页面,提取11行和14行的iphone钓鱼域名&Android钓鱼域名 不是已知的特定格式页面,将网页代码保存下来进行人工分析 (根据攻击者改动而增加的功能)安卓重定向跳转的页面还会再有一次重定向跳转,将其域名也记录下来 是,分别去判断属于?直接重定向页面(第10行是否包含重定向)/分设备重定向页面(第11行和14行是否包含重定向) 否,属于无法访问页面的情况,将无法访问的域名保存下来
python代码:
import?re
import?pandas?as?pd
import?time
import?threading
import?requests
#?请求网站判断是否访问成功
def?access_request(urls):
????headers?=?{'User-Agent':?'Mozilla/5.0?(Windows?NT?6.1;?WOW64;?rv:23.0)?Gecko/20100101?Firefox/23.0'}
????try:
????????req?=?requests.get(url=urls,?headers=headers)
????????print(req.url+"访问成功?"+str(req.status_code))
????????return?req
????except?Exception?as?e:
????????print(e)
????????print(str(urls)+"无法访问")
????????return?False;
#?正则匹配重定向的URL字符串
def?match_href(line):
????matchObj?=?re.findall(r'(?<=document.location.href?=?").*?(?=\")',?line,re.S)
????return?matchObj
#?将数据按照指定格式保存到execl
def?write2Execl(path,?redirectiondomain,?selectdomain,?iphonedomain,?androiddomain,androidre_Url):
????original_data?=?pd.read_excel(path)
????data1?=?{"直接重定向域名":?[redirectiondomain],"重定向到的域名":[selectdomain],"iphone钓鱼域名":[iphonedomain],"Android钓鱼域名":[androiddomain],"Android重定向域名":[androidre_Url]}
????data1?=?pd.DataFrame(data1)
????#?将新数据与旧数据合并起来
????save_data?=?original_data.append(data1,ignore_index=True)
????save_data.to_excel(path,?index=False)
#?判断是不是直接重定向的页面
def?redirection_Page(html1,?url):
????#?判断第10行是否包含重定向语句
????try:
????????url1?=?match_href(html1[10])
????#?如果没有第十行则异常,说明不是特定页面
????except:
????????return?False
????if?url1:
????????print("特定直接重定向的页面")
????????redirectionurl?=?str(url)
????????print("重定向域名:"?+?str(url1[0]))
????????selectdomain?=?url1[0]
????????return?url1[0],?redirectionurl,?selectdomain
????return?False
#?判断是不是分设备重定向的页面
def?select_Page(html2,?url):
????#?判断指定的行是否包含重定向语句
????try:
????????iphoneurls?=?match_href(html2[11])
????????Androidurls?=?match_href(html2[14])
????except:
????????return?False
????if?Androidurls:
????????print("特定分设备重定向的页面")
????????print("iphone钓鱼域名:"?+?str(iphoneurls[0]))
????????print("Android钓鱼域名:"?+?str(url)?+str(Androidurls[0]))
????????iphoneurl?=?iphoneurls[0]
????????androidurl?=?str(url)?+?str(Androidurls[0])
????????return?iphoneurl,?androidurl
????return?False
#?线程
def?scan(url):
????print("----------")
????redirection_Url?=?select_Url?=?iphone_Url?=?android_Url?=?androidre_Url?="X"
????#?发送请求
????reqObject?=?access_request(url)
????#?进入循环判断
????if?not?reqObject:
????????redirection_Url?=?url
????while?reqObject:
????????repage?=?""
????????sepage?=?""
????????list_html?=?reqObject.text.split('\n')
????????redomain?=?reqObject.url
????????sepage?=?select_Page(list_html,?redomain)
????????repage?=?redirection_Page(list_html,?redomain)
????????#?判断是否为直接重定向页面
????????if?repage:
????????????redirection_Url?=?str(repage[1])
????????????select_Url?=?str(repage[2])
????????????reqObject?=?access_request(repage[0])
????????#?判断是否为分设备重定向页面
????????elif?sepage:
????????????select_Url?=?str(redomain)
????????????iphone_Url?=?str(sepage[0])
????????????android_Url?=?str(sepage[1])
????????#判断安卓页面重定向
????????????android_reqObject?=?access_request(android_Url)
????????????list_html1?=?android_reqObject.text.split('\n')
????????????android_repage?=?redirection_Page(list_html1,?android_Url)
????????????if?android_repage:
????????????????androidre_Url?=?str(android_repage[2])
????????????break;
????????#非特定格式页面
????????else:
????????????print("格式变化,人工分析")
????????????redirection_Url?=?str(url)
????????????select_Url?=?str(reqObject.text)
????????????break
????#?写入execl
????write2Execl(path,?redirection_Url,?select_Url,?iphone_Url,?android_Url,androidre_Url)
if?__name__?==?'__main__':
????#?路径
????path?=?r'C:\Users\mengm\Desktop\103.80.134.91.xlsx'
????#?字典存放路径
????dicpath?=?r'C:\Users\mengm\Desktop\103_80_134_91.txt'
????file?=?open(dicpath,?'r')
????#?线程数
????threads?=?1000
????for?a?in?file.readlines():
????????#?限制线程数
????????while?(threading.activeCount()?>?threads):
????????????time.sleep(1)
????????#?限制线程的方式进行控制发送数据包
????????t1?=?threading.Thread(target=scan,?args=(a.replace("\n",?""),))
????????t1.start()
????????#?等待线程结束,为1
????????while?(threading.activeCount()?!=?1):
????????????time.sleep(1)
????print("结束")
重定向域名的IP关联扩线:
通过搜索重定向域名的IP可以在vt中发现大量相同或是相似格式的域名,将其关联到的域名提取出来归类进行数据分析,例如103.80.134.89
VT批量提取IP关联域名:
通过测试发现由于VT接口限制,最多能从resolutions中关联到历史解析记录1000条记录,并且会根据开头字母升序获取(目前获取到的仅从axxx.duckdns.org到lxxx.duckdns.org),因为获取的数据有限,所以尽可能多的将关联到的其他字段url(detected_urls,undetected_urls)也保存下来再进行二次去重筛选
python代码:
调用vt的api去获取相应字段保存到execl
import?requests
import?json
import?jsonpath
import?pandas?as?pd
import?re
#?将数据保存到execl
def?write2execl(path,type,data):
????original_data?=?pd.read_excel(path)
????data2?=?{type:?[data]}
????data2?=?pd.DataFrame(data2)
????#?将新数据与旧数据合并起来
????save_data?=?original_data.append(data2,ignore_index=True)
????save_data.to_excel(path,?index=False)
????#print("保存到execl成功")
#?正则匹配url
def?find_encodestr(line):
????#?调用解密函数则
????if?line.find("djbaaijbegj.achadefcefh(\""):
????????#?正则匹配加密的值
????????pattern?=?re.compile(r'(?<=\'http://).*?(?=/\',)')
????????decodestr?=?pattern.findall(line)
????????return?decodestr
path?=?r"C:\Users\mengm\Desktop\domain1.xlsx"
#?vt获取数据关联到ip的数据字段
url?=?'https://www.virustotal.com/vtapi/v2/ip-address/report'
params?=?{'apikey':'xxx','ip':'103.80.134.89'}
response?=?requests.get(url,?params=params)
s_json?=?json.loads(response.text)
domin?=?[]
#?detected字段的域名
detected?=?[]
detected_urls?=?jsonpath.jsonpath(s_json,?'$.detected_urls.[*].url')
for?a?in?detected_urls:
????str1?=?str(a).replace("http://","").replace("/","")
????detected.append(str1)
#?追加到列表
domin.extend(detected)
#?undetected字段的域名
undetected_urls?=?jsonpath.jsonpath(s_json,?'$.undetected_urls.[*]')
undetected?=?find_encodestr(str(undetected_urls))
#?追加到列表
domin.extend(undetected)
#?resolutions字段的域名
domain?=?[]
resolutions?=?jsonpath.jsonpath(s_json,?'$.resolutions.[*].hostname')
#?追加到列表
domin.extend(resolutions)
print("总共关联到域名数"+str(len(domin)))
#?去重
domin?=?list(set(domin))
print("去重后域名数"+str(len(domin)))
#?写入execl
len1?=?len(domin)
for?u?in?range(len1):
????write2execl(path,"关联到的域名",domin[u])
????print(str(u)+"/"+str(len1))
域名数据初步分类处理:
| ip: | 103.80.134.89 | |
|---|---|---|
| 关联到的域名总数 | 1063 | 处理后关联域名总数 |
| ".duckdns.org"的个数 | 707 | 域名格式均为"[a-z]{10}.duckdns.org" |
| 其他特殊格式的.com域名 | 354 | 域名格式均为"[a-z]{5}.[a-z]{5}.com" |
| 153853.com | 1 | 异常格式数据 |
| game.heroworldnft.com | 1 | 异常格式数据 |
异常格式数据:
2个异常格式的域名均无法正常访问,
([a-z]{5}.[a-z]{5}.com):
关联到的该格式域名均为新加坡域名服务提供商GoDaddy下注册的域名,尝试访问几个域名都已经提示被回收了,通过挨个遍历已知的网页内容长度对比得出均为相同页面,此格式类型域名中均无其他有效线索
([a-z]{10}.duckdns.org):
通过所有页面的长度Content-length做一个初步的判断,测试发现大部分为有效域名,长度为"213"的页面均为重定向页面,格式和攻击者之前使用的直接重定向页面一样
| | 数量: | | --- | --- | | 总域名: | 707 | | 可以访问,长度389 | 646 | | 可以访问,长度213 | 48 | | 无法访问 | 13 |
直接重定向代码格式和最初(myffdvfuom.duckdns.org)使用的代码一致:
<!doctype?html>
<html>
<head>
????<meta?charset="utf-8">
????<title></title>
</head>
<body>
????<script>
???document.location.href?=?"http://cjwuefpycw.duckdns.org";
????</script>
</body>
</html>'
关联到的域名存储到本地
上面做的仅仅只是从一个域名挖掘到的整条攻击链,根据vt关联到的大量域名可以继续挖掘出更多的攻击链中使用的域名,根据这个思路重复运行刚才编写的python脚本批量提取目前已知的域名信息并且存储在execl中?获取的页面分为四种情况:
"直接重定向页面" "分设备重定向页面" 可访问,但不是已知的特定格式页面 无法访问页面
存储格式:?需要存储的四个页面域名为层级关系,所以将一行定为一条完整的情报链,将结果按照指定的格式写入到execl中,以便清晰判断页面的情况,不存在的域名则以"X"表示,
直接重定向域名 iphone钓鱼域名 Android钓鱼域名 Android二次重定向域名 分设备重定向域名
格式效果:
| 直接重定向域名 | 分设备重定域名 | iphone钓鱼域名 | Android钓鱼域名 | Android钓鱼二次重定向域名 | |
|---|---|---|---|---|---|
| 直接重定向页面 | aaa.com | bbb.com | ccc.com | ddd.com | eee.com |
| 分设备重定向页面 | X | bbb.com | ccc.com | ddd.com | eee.com |
| 可访问,但不是已知的特定格式页面 | aaa.com | <html代码> | X | X | X |
| 无法访问页面 | aaa.com | X | X | X | X |
execl存储效果:
关联到其他不同主题的攻击活动:
2022.11.7:?攻击者在活动中会频繁变化钓鱼域名和使用的IP来规避黑名单检测,以及python爬取重定向数据的时间相差了好几天,有些域名之前可以访问,现在无法访问,造成数据上可能有些参差,并且攻击者针对Android设备的攻击方式已经不再使用恶意app了,而是像针对iphone设备一样去使用假冒国税局页面进行钓鱼
目前收集到的攻击IP资产信息:
发现大部分都开放了"8888"端口,该端口为中国常用的一款服务器管理软件"宝塔面板"默认端口,再次从侧面验证攻击者可能为中国人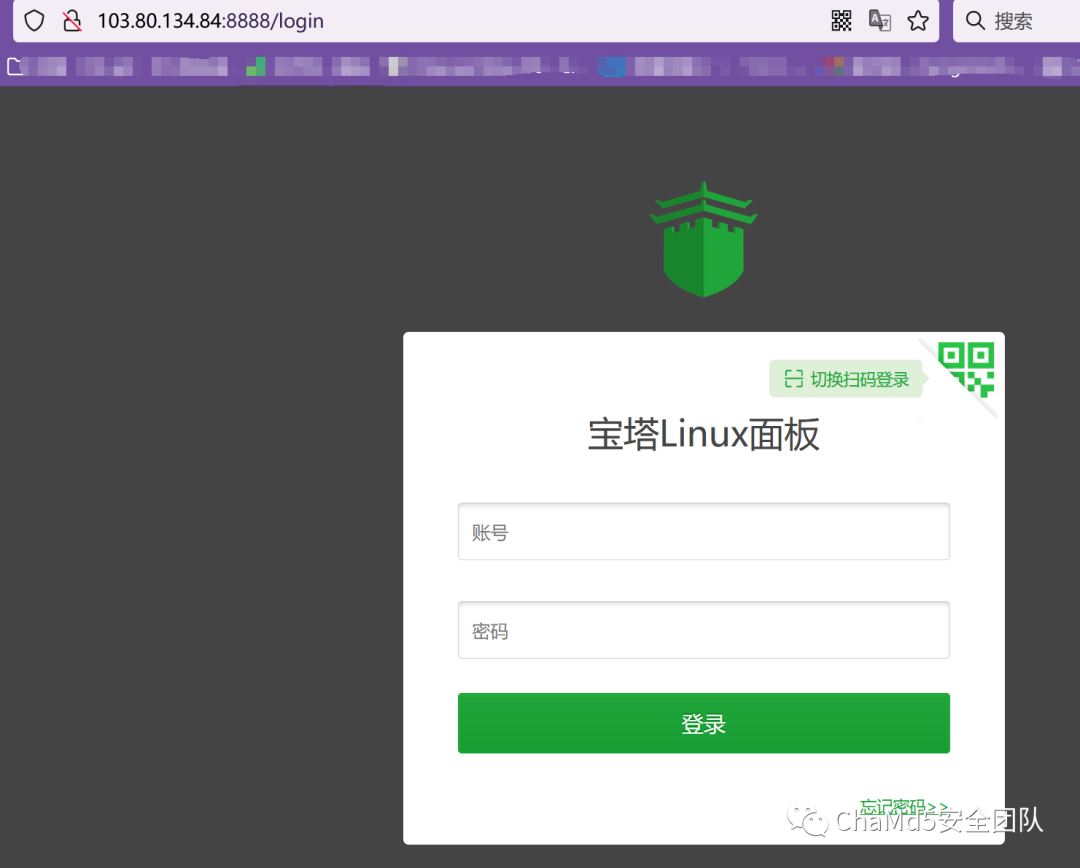 根据持续的域名和IP信息提取,发现攻击者使用到的IP非常多,但是基本使用的相同的服务器配置,考虑从大量相同的jarm入手去继续扩线
根据持续的域名和IP信息提取,发现攻击者使用到的IP非常多,但是基本使用的相同的服务器配置,考虑从大量相同的jarm入手去继续扩线
3fd3fd0003fd3fd21c42d42d000000307ee0eb468e9fdb5cfcd698a80a67ef
3fd3fd0003fd3fd21c42d42d000000bdfc58c9a46434368cf60aa440385763
3fd3fd0003fd00021c42d42d00000014f9d174e655e30a3340ff4e21dd9af4
3fd3fd0003fd3fd21c42d42d000000f816eaea5c28bd7b1d0104ee7676bfe1
| 页面类型 | IP | 开放的端口 | jarm |
|---|---|---|---|
| 分设备重定向页面 | 103.80.134.84 | 80,8888 | |
| 分设备重定向页面 | 103.80.134.89 | 80,8888 | |
| 分设备重定向页面 | 103.80.134.90 | 80,8888 | |
| 分设备重定向页面 | 103.80.134.91 | 80,8888 | |
| 假冒国税局页面 | 45.12.138.161 | 80, 443 | 3fd3fd0003fd3fd21c42d42d000000307ee0eb468e9fdb5cfcd698a80a67ef |
| 假冒国税局页面 | 66.150.66.64 | 22,80,8888 | 3fd3fd0003fd3fd21c42d42d000000bdfc58c9a46434368cf60aa440385763 |
| 假冒国税局页面 | 63.251.217.5 | 22,80,443,8888 | 3fd3fd0003fd3fd21c42d42d000000bdfc58c9a46434368cf60aa440385763 |
| 假冒国税局页面 | 185.250.221.22 | 22,80 | 3fd3fd0003fd00021c42d42d00000014f9d174e655e30a3340ff4e21dd9af4 |
| 假冒国税局页面 | 185.203.7.103 | 21,80,443 | 3fd3fd0003fd3fd21c42d42d000000bdfc58c9a46434368cf60aa440385763 |
| 假冒国税局页面 | 185.203.7.123 | 22,80,443 | 3fd3fd0003fd3fd21c42d42d000000bdfc58c9a46434368cf60aa440385763 |
| 假冒国税局页面 | 213.59.118.101 | 22,80,443,8888 | 3fd3fd0003fd3fd21c42d42d000000bdfc58c9a46434368cf60aa440385763 |
网络空间资产测绘:
shodan扩线IP资产:
以IP为出发点进行扩线,主要使用的是Shodan引擎搜索,根据目前已知的"分设备重定向页面"和"假冒国税局页面"的IP所对应的网络资产的特殊值以及指纹进行资产扩线 (开放端口"22,80,443,8888"),通过端口的hash和html_hash进行搜索扩线 同时结合大量重复的jarm以及在vt中关联到的域名均为通用格式的
同时结合大量重复的jarm以及在vt中关联到的域名均为通用格式的.duckdns.org域名后缀也可以辅证关联到的资产均为同一攻击者所使用的资产
| 已知IP | 端口hash | 扩线IP | jarm |
|---|---|---|---|
| 185.203.7.103 | http.html_hash:934703019 | 45.86.77.51 | |
| 45.88.168.220 | |||
| 63.251.217.5 | |||
| 185.212.68.4 | 3fd3fd0003fd3fd21c42d42d000000bdfc58c9a46434368cf60aa440385763 | ||
| 185.203.7.123 | http.html_hash:-377362481 | 45.82.251.31 | |
| 45.82.251.43 | |||
| 45.155.42.155 | |||
| 141.98.134.127 | |||
| 213.59.118.101 | 3fd3fd0003fd3fd21c42d42d000000bdfc58c9a46434368cf60aa440385763 | ||
| 45.12.138.161 | http.html_hash:2004180945 | 2.56.254.21 | |
| 45.88.168.116 | |||
| 45.148.136.2 | |||
| 63.251.217.30 | |||
| 63.251.217.97 | |||
| 185.183.87.46 | |||
| 193.239.146.50 | |||
| 193.239.146.77 | |||
| 213.59.118.134 | 3fd3fd0003fd3fd21c42d42d000000307ee0eb468e9fdb5cfcd698a80a67ef | ||
| 179.43.149.14 | hash:-1965469592 | 179.43.149.15 | |
| 179.43.149.16 | |||
| 179.43.149.17 | |||
| 179.43.149.18 | |||
| 81.17.22.78 | 3fd3fd0003fd3fd21c42d42d000000307ee0eb468e9fdb5cfcd698a80a67ef |
c段扫描:
通过观察收集记录攻击者变化的域名和IP分析,发现经常使用连号的IP,具有一定的关联性,通过c段探测扩线发现从103.80.134.84 ~ 103.80.134.95还有103.80.134.97均为攻击者的资产,其中103.80.134.97上次活跃还是在一年前,其他均为近期活跃IP
其他攻击主题:
邮箱反查扩线:
根据whois信息反查发现大量的域名的注册者信息没有隐私保护,注册者为中国女性名字并且使用的是网易邮箱,因为网易邮箱的注册门槛比较低,信息暴露比较少,疑似虚假身份 根据邮箱反查注册的域名,发现攻击者利用此身份注册了大量域名,绝大部分为阿里云平台注册的,尝试批量将此邮箱注册的所有域名都导出在本地,微步x情报社区目前邮箱反查域名最全且免费,但是没有批量导出功能,尝试编写js脚本提取,提取完之后根据子域名反查
根据邮箱反查注册的域名,发现攻击者利用此身份注册了大量域名,绝大部分为阿里云平台注册的,尝试批量将此邮箱注册的所有域名都导出在本地,微步x情报社区目前邮箱反查域名最全且免费,但是没有批量导出功能,尝试编写js脚本提取,提取完之后根据子域名反查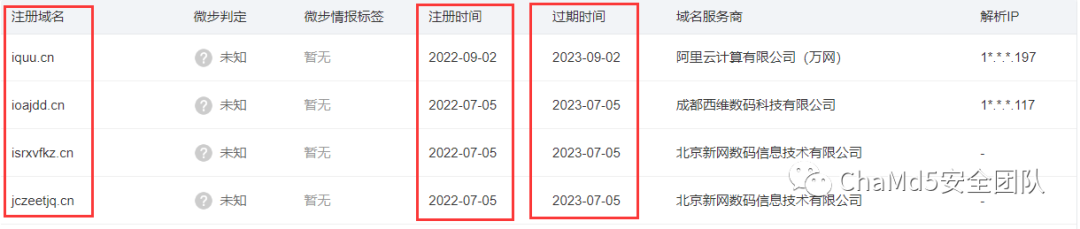
//保存到本地
var?output?=?new?Array();
function?saveShareContent?(content,?fileName)?{
??let?downLink?=?document.createElement('a')
??downLink.download?=?fileName
??//字符内容转换为blod地址
??let?blob?=?new?Blob([content])
??downLink.href?=?URL.createObjectURL(blob)
??//?链接插入到页面
??document.body.appendChild(downLink)
??downLink.click()
??//?移除下载链接
??document.body.removeChild(downLink)
}
var?tb?=?document.getElementById('test');????//?table?的?id
var?rows?=?tb.rows;???????????????????????????//?获取表格所有行
for(var?i?=?0;?i<rows.length;?i++?){
??output.push("\r第"+(i+1)+"个\r");
??for(var?j?=?0;?j<rows[i].cells.length;?j++?){????//?遍历该行的?td
????if(j+1?==?1){
??????output.push("网址:"+rows[i].cells[j].innerHTML.replace(/<\/?.+?>/g,?""));
????}else?if(j+1?==?4)
????{
??????output.push("注册时间:"+rows[i].cells[j].innerHTML);
????}else?if(j+1?==?5){
??????output.push("过期时间:"+rows[i].cells[j].innerHTML);
????}
????//?输出每个tr的内容
??}
}
saveShareContent?(output,?"save")
关联到大量针对日本各个行业的钓鱼域名及IP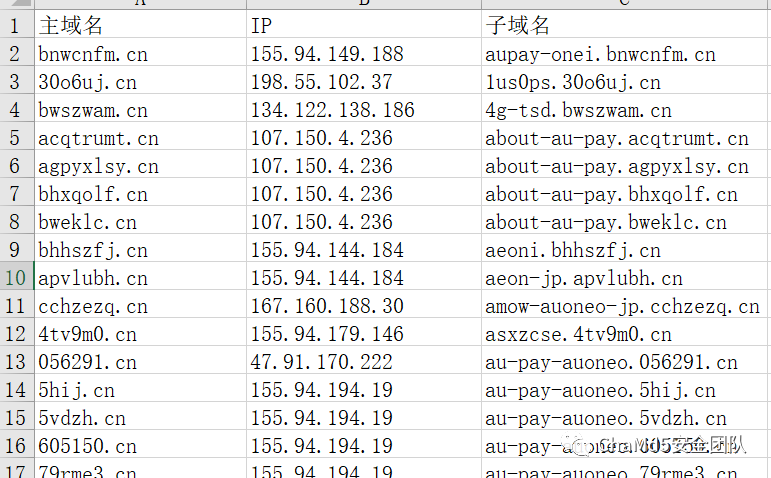
部分攻击主题域名格式
针对日本docomo运营商
| doco[a-z]{2}.top |
|---|
针对日本au-pay运营商
|?about-au-pay.[a-z]{7}.cn bwut-au-pay.[0-9a-z]{6}.cn aupay-update-jp.[0-9a-z]{5}.cn aupay-onei.[a-z]{7}.cn au-pay-auoneo.[0-9]{6}.cn amow-auoneo-jp.[a-z]{7}.cn about-au-pay.[a-z]{8}.cn inof-auoneo-jp.[a-z]{8}.cn
| mowcn-au-pay.[a-z]{6}.cn |
|---|
针对日本AEON网购平台(https://www.aeon.com)
|?aeon-jp.[a-z]{7}.cn
| aeoni.[a-z]{7}.cn |
|---|
针对日本Mercari跳蚤市场服务(https://jp.mercari.com)
|?jp-merioari.[0-9a-z].cn?jp-mericarli.[0-9a-z].cn?jp-mericario.[0-9a-z].cn
| jp-mercario-pay.[0-9a-z].cn |
|---|
iphone钓鱼页面分析(伪造国税局页面):
弹窗提示需要缴纳所得税,付款的最后期限仅限当日,会随着访问日期变化而变化
付款确认号码:****3697
我们一直在敦促你自愿支付你的所得税(或欠款,依法计算),但你还没有这样做。?该公司是本公司及其子公司的注册商标。
参观费总额:40,000日元
付款截止日期:2022年11月8日
付款的最后期限:2022/11/8(付款期限不能延长)。
点击弹窗支付按钮会跳转到页面"/step2.html",诱导用户填写个人信息和银行卡信息, 上传到指定网页面
上传到指定网页面 该页面模板估计为ntagoj.info/notice.php,IP为153.122.197.148
该页面模板估计为ntagoj.info/notice.php,IP为153.122.197.148
Android应用程序逆向分析:
详细分析链接:apk逆向&扩线&溯源
基本信息:
攻击者通过,攻击者通过网页诱导安卓用户下载安装伪装成由KDDI开发的AU移动安全恶意程序
| apk名称 | KDDIセキュリティ.apk |
|---|---|
| file_hash | 585bef6ce050389b729590008fae18d6 |
| 程序图标 |  |
应用程序无实际的"AU移动安全"功能,点击任何按钮均弹出"Start Success"
使用的部分特殊字符串:
发现解密后字符串中使用大量的中文,正面证明了攻击者是以简体中文为母语人士
| 加密字符串 | 解密后明文 |
|---|---|
| ARAeFFtNTRwKDBcTDAMIAAxMHAoSXwoLBBAEDBZGERoE | http://tongzhilan.top/content.txt |
| ARAeFFtNTVpXUkFZUQgBCEwWBxVN | http://220105bei.top/ |
| ARAeFFtNTRwKDBcTDAMIAAxMHAoSXwUNBA9PFhoc | http://tongzhilan.top/link.txt |
| ARAeFFtNTRwKDBcTDAMIAAxMHAoSXwULDQtPEgwP | http://tongzhilan.top/logo.png |
| ARAeFFtNTVpXUkFZUUQQDhJN | http://220105.top/ |
| ARAeFFtNTVpXUkFZUUQQDhJN | http://220105.top/ |
| gOTwjM/Nh9XwRA== | 通讯录& |
| gOTwjM/Nh9XwRB4GRBgBEhcOHEQ= | 通讯录&no result! |
| j/npjfjyRI75yJjn04/r94T/64z74A== | 权限&未获取权限 |
| jNvpjNbRRBgMDBc= | 心跳&ping |
| j/npjfjyh+f0i/DoguXFh+vpjenn | 权限发送握手包 |
| jOnSjNzfhOD1h/r2Qg== | 卸载成功& |
| jOv7gN7DhOnKRAMcBwkBEhFY | 发信息&success: |
| jdvLguDNh9/XhP/5gNDAR4ba6A== | 信息已提交&一 |
| j+vLgujph+TgRA== | 握手包& |
| LSE5SyQhIEcrDSAIAA4NDwU= | DES/ECB/NoPadding |
| LSE5 | DES |
| LSE5AQUHTS0mIF8nCzoFBQYLBgI= | DESede/ECB/NoPadding |
| LSE5AQUH | DESede |
| KCE5SyQhIEcrDSAIAA4NDwU= | AES/ECB/NoPadding |
| KCE5 | AES |
| DxETBQ8DDA== | fuyanan |
疑似人名("fuyanan"):
找到2015年博客园的有篇文章"监听短信的两种方式的简介"中列举的代码和攻击者使用的代码存在重叠,大概率为攻击者复制了该文章作者的代码
"date desc"为文章中判断的号码,攻击者没做任何改变直接复制下来使用 "fuyanan"特殊人名,攻击者同样没改变,直接使用
博客文章:
 攻击者使用代码:
攻击者使用代码:

通信行为:
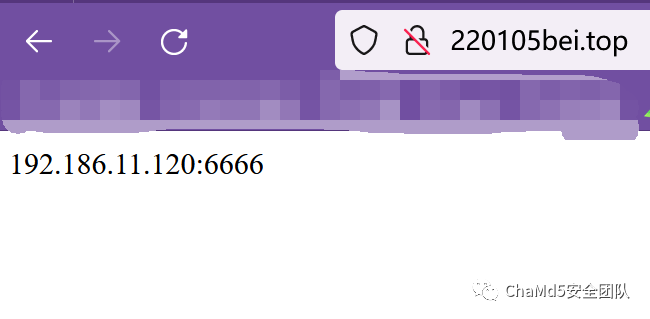
攻击者通过访问代理服务器("http://220105bei.top/")的方式获取到C2的IP地址和端口,以此方式来规避av静态检测,实际上访问连接到的IP为192.186.11.120:6666
通过IP关联扩线到未知攻击主题:
根据已知的恶意应用程序使用到的IP(91.202.5.99&192.186.11.120),可以在vt上关联到大量相同和类似攻击主题的应用程序 初步查看并且根据应用名称可以将攻击主题分为三类,冒充日本运营商au,docomo和SOFTBANK,大量恶意应用程序的恶意功能基本都一致
初步查看并且根据应用名称可以将攻击主题分为三类,冒充日本运营商au,docomo和SOFTBANK,大量恶意应用程序的恶意功能基本都一致
| apk名称 | 翻译 | 钓鱼攻击主题 |
|---|---|---|
| KDDIセキュリティ.apk | KDDI安全.apk | AU By KDDI |
| NTTあんしんセキュリティ_.apk | NTT安信安全.apk | NTT DOCOMO |
| Softbankセキュリティ.apk | 软银安全.apk | BB Security |

zoomeye资产绘制:
通过zoomeye搜索IP91.202.5.99可以探测到关联的一些域名目前依然在攻击链中作起到获取真实c2的作用
| 域名 | banner |
|---|---|
| 221101bei.top | 192.186.13.30:7777 |
| 221101.top | 192.186.13.30:7777 |
| 220417bei.top | 192.186.13.90:6666 |
| 220417.top | 192.186.13.90:6666 |
| 220103.top | 192.186.11.125:6666 |
| 220104bei.top | 192.186.11.205:6666 |
| 220104.top | 192.186.11.205:6666 |
| 220105bei.top | 192.186.11.120:6666 |
| 220105.top | 192.186.11.120:6666 |
特殊数据:
将所有的IP在VT中批量提取相关域名,将所有的数据去重分类清洗,按照其活动时间范围进行再次筛除后得到了一个特殊的数据 "www.ppaway.com"格式和同IP下其他解析的钓鱼域名不同,并且在 2022-05-13 更换新IP地址为193.187.117.156,查询到的jarm指纹和伪造国税局页面一致
 并且可以从vt中通过相同攻击主题的样本关联到另外的c2地址209.250.232.4:6666,也与攻击者使用的代理手法如出一辙
并且可以从vt中通过相同攻击主题的样本关联到另外的c2地址209.250.232.4:6666,也与攻击者使用的代理手法如出一辙 直接访问为后台发现为管理系统
直接访问为后台发现为管理系统 目前该域名解析到154.204.45.195
目前该域名解析到154.204.45.195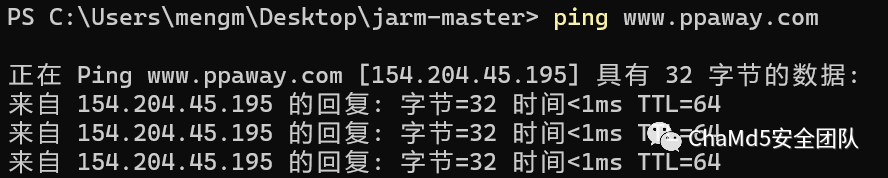
溯源(资产的WHOIS信息):
数据清洗:
根据以上的操作,已经获取到了非常多的IP以及域名,现在需要将获取到的域名进行数据分类和清洗筛选,剔除通用特殊格式的域名(duckdns.org/特殊主题钓鱼域名),获取数据后再将特殊值和异常值进行信息查询定位
清洗逻辑
IP 基础网络资产提取 扩线网络资产 IP关联的域名 WHOIS 保留"registrar"和"emails"到数组listRegister listRegister去重后导出.xls表格 表格内筛选有效注册者信息 排除注册商 排除已知的虚假身份
通过这种方式批量查询到的信息包含一些特殊的中文人名,且信息较为全面和真实,再手动进行溯源确认
攻击者1号:
基本信息溯源:
特殊域名信息 通过查询对应的qq号和微信号均存在,基本可以确定域名为真实用户注册,再次根据注册使用的qq邮箱可以反查到攻击者在2017年注册的域名,并且注册信息填写的很全
通过查询对应的qq号和微信号均存在,基本可以确定域名为真实用户注册,再次根据注册使用的qq邮箱可以反查到攻击者在2017年注册的域名,并且注册信息填写的很全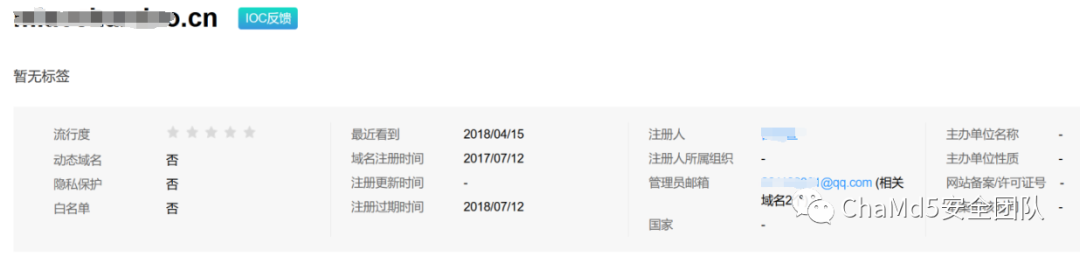 通过注册时使用的电话号码搜索其支付宝账号转账可得到真实的姓和名字最后一个字,验证了whois信息为真实信息
通过注册时使用的电话号码搜索其支付宝账号转账可得到真实的姓和名字最后一个字,验证了whois信息为真实信息
攻击者个人经历:
攻击者在2010年左右开始学习易语言,常用ID为 ,ID和名字强关联
,ID和名字强关联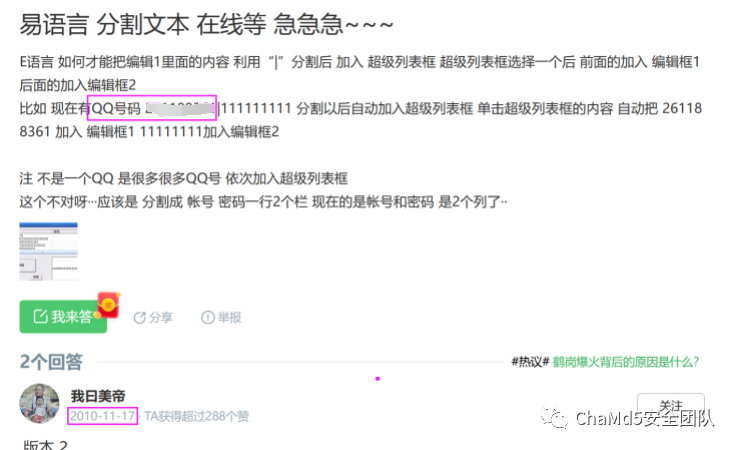 最常使用学习易语言论坛"精易论坛",且连续发布大量文章帖子,均关于易语言开发,为论坛重度用户,在线时间2680小时!
最常使用学习易语言论坛"精易论坛",且连续发布大量文章帖子,均关于易语言开发,为论坛重度用户,在线时间2680小时!
实锤:
在2022-4-16的时候发帖询问关于日本运营商au验证码问题,和攻击主题契合,攻击时间线也吻合
基本信息:

攻击者2号,3号:
发现特殊注册公司和邮箱
根据qq邮箱反查关联域名
发现大量的注册者相关资料和公司名称,高频出现其常用电话号码


进一步个人信息验证:
攻击者屏蔽了"qq号查找"功能,无法直接搜索到账号,但是根据第三方网站统计结果,以及充值了年费vip,账号等级也很高,可以基本确定是真实账号且是日常使用的主要账号 qqvip邮箱 ,也被当作注册公司使用的邮箱
,也被当作注册公司使用的邮箱 并且可以从qq号关联到微信账号,根据微信显示的地区"浙江 衢州"
并且可以从qq号关联到微信账号,根据微信显示的地区"浙江 衢州"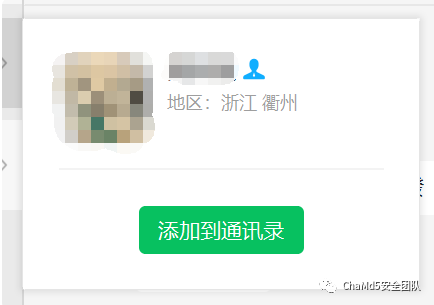 但是通过微信搜索其注册域名时使用的电话号码时却出现不同的微信号码,且账号使用者为女性,但是所在的地区相同,两个人存在强关联
但是通过微信搜索其注册域名时使用的电话号码时却出现不同的微信号码,且账号使用者为女性,但是所在的地区相同,两个人存在强关联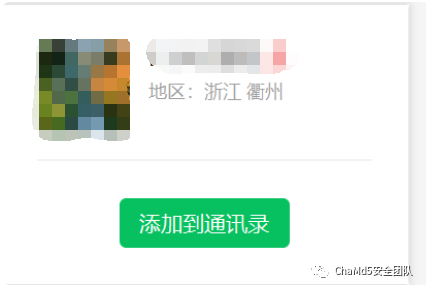
信息扩线梳理
注册的所有公司均无实缴资金,且社保人数为0,基本确认为皮包公司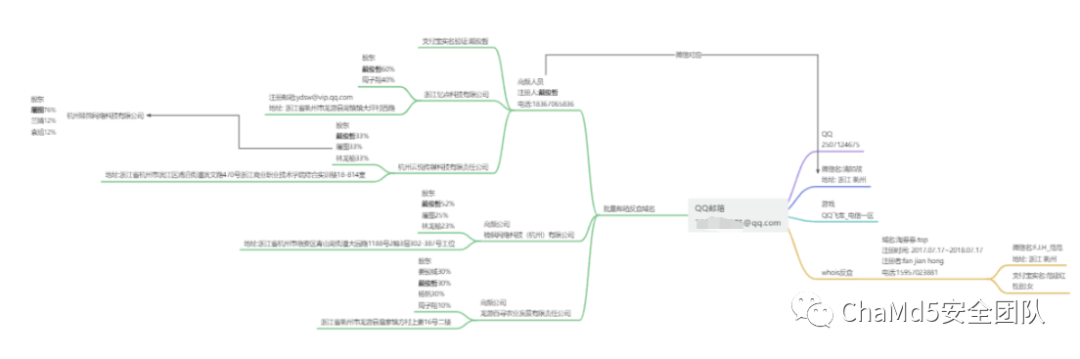
扩线流程梳理:
总结:
安全本质到最后就是人与人之间的一个较量,尽量去站在攻击者的角度思考去梳理整条攻击链的实现流程,就能在关联手段方面将各个信息点串联起来,对于数据的分类和筛选处理可以根据通过 特殊值、固定值、聚集值、异常值 进行定位 整体的扩线溯源需要从已知的信息,去发掘更多未知的相关信息,不局限于仅暴露出来的那一起攻击事件,需要进行更多维度和更加大量的数据进行分析,随着数据收集越来越完善才能发现未知攻击并进一步溯源,深挖事件背后的较为隐蔽的私人资产,实现更深层次的攻击溯源,再将收集到的信息及其关联数据和备案信息去加以验证,实现溯源至攻击者个人信息
参考:
https://www.yuque.com/jianouzuihuai/study/hands-on_traceability__locating_phishing_attackers__from_codes_to_time_zones__from_countries_to_specific_people-00https://www.yuque.com/jianouzuihuai/study/hands-on_traceability__locating_phishing_attackers__from_codes_to_time_zones__from_countries_to_specific_people-01https://www.yuque.com/jianouzuihuai/study/hands-on_traceability__locating_phishing_attackers__from_codes_to_time_zones__from_countries_to_specific_people-02
招新小广告
ChaMd5?Venom?招收大佬入圈
新成立组IOT+工控+样本分析?长期招新
欢迎联系admin@chamd5.org

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 Chamd5安全团队
Chamd5安全团队
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675