
UCloud对象存储US3元数据改造(下)
前言
在《UCloud对象存储US3元数据改造(上)》中,我们介绍了US3的新版本元数据服务UKV-Meta,UKV-Meta是基于UCloud自研的分布式计算存储分离的KV系统UKV,所研发的对象存储元数据服务,下面我们将介绍一下UKV及其相关组件。
URocksDB
I. 简介
URocksDB是UKV存储引擎, 是US3研发小组针对开源RocksDB定制化开发的Key-Value存储引擎。
II. RocksDB
LevelDB是由Google开源的,基于LSM Tree的单机KV数据库,其特点是高效,代码简洁而优美。RocksDB则是Facebook基于LevelDB改造的,它在level的基础上加了很多实用的功能,例如Column Family等,具体的差别大家可以Google,也可以实际体验一下,这里就不再赘述了。
RocksDB目前已经运用在许多海内外知名的项目中,例如TiKV,MyRocksDB,CrockRoachDB等。
RocksDB使用上的缺点
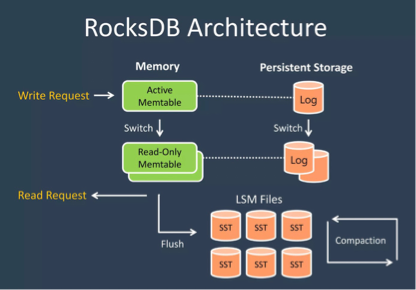
RocksDB是通过WAL来保证数据持久性的,RocksDB先将数据写入磁盘上的WAL,再将数据写入内存中的Memtable中,当Memtable达到大小阈值(或者WAL的大小阈值),Memtable中的内容会被Flush成有序的SST文件持久化,WAL也会切换成新的WAL(代表旧的数据已被持久化,避免WAL过大)。
当RocksDB出现问题当机/重启后,可以通过重做WAL来使RocksDB内存中未持久化的数据恢复到之前的状态。
但是这里存在两个问题:
1、RocksDB读取WAL是线性读取的, 当为了读性能把Memtable设置的足够大时,WAL也可能变得很大(Flush频率下降),此时如果发生当机重启,RocksDB需要足够长的时间来恢复。
2、如果机器硬盘出现损坏,WAL文件本身被破坏,那么就会出现数据损坏。即使做了Raid,也需要很长时间来恢复数据。
因此RocksDB的可用性是个大问题。
另外由于LSM架构,RocksDB的读性能也会存在问题。
怎么解决?
Share Nothing
为了满足数据一致性这一基本要求,大部分的解决方案都是将一致性协议置于RocksDB之上,每份数据通过一致性协议提交到多个处于不同机器的RocksDB实例中,以保证数据的可靠性和服务的可用性。
典型如TiKV:
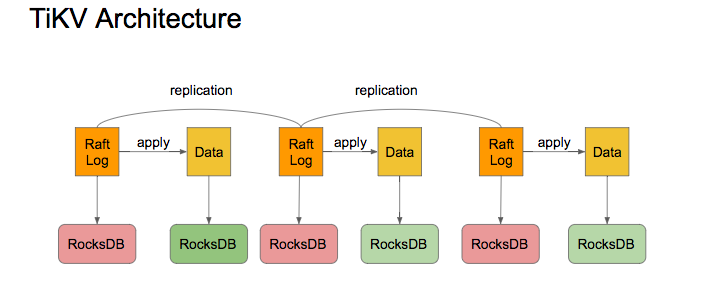
TiKV使用3个RocksDB组成一个Group,存储同一份数据,实例与实例之间不共享任何资源(CPU、内存、存储),即典型的Share Nothing模式。一旦有一实例数据有损失,可通过另外的实例迁移/同步日志,来做恢复。
这种模式解决了可用性问题,也有不错的扩展性。但也存在缺点:
目前CPU的成本偏高,是我们在实际业务中重点关注的成本优化点之一。而RocksDB(LSM Tree架构)的一大问题就是写放大。每个RocksDB为了提高读性能、降低存储大小,都会进行不定期Compaction(将数据读出来重新Decode/Encode,再写入磁盘),编解码本身会消耗大量的CPU资源。而这样的多份(一般3份)写入RocksDB,等于CPU消耗确定会放大3倍。并且写放大由于提高了写的次数,即提高SSD的擦写次数,会显著减少SSD的寿命,提高系统的成本。
这种架构计算与存储是耦合在一起的,无论是计算先达到瓶颈,还是存储先达到瓶颈,两种状况虽然不同,时间点也不一致。但通常不管哪种情况都是加机器,因此就会存在不少浪费。
不易扩展:计算和存储耦合模式下,存储扩展通常需要迁移大量数据。
存算分离
将数据存储于分布式文件系统中,由其保证数据的一致性和存储的扩容,而计算节点仅仅处理数据的写入和读取。

URocksDB使用自研的分布式存储服务Manul作为底层的存储,Manul具备数据高可靠,服务高可用的特性, 拥有自动容灾、扩容等功能。这样当主节点写入一份数据时,Manul会自动做三副本同步数据,而从节点也能很快同步到主节点做好的数据,无需再多做几次重复的Flush或者Compaction。
当存储节点容量不够时,可单独加入新的存储节点,Manul能够自动平衡数据。当计算节点达到瓶颈时,URocksDB拥有独特的热点分裂功能,在无需做数据迁移的情况下即可快速增加计算节点,降低热点压力。此时就能够更精细化的运营计算资源和存储资源,降低业务成本。
URocksDB热备
RocksDB是支持Read Only模式的,但是只是类似于读一个快照,并不能读取到主节点DB的最新数据。我们实现了RocksDB Secondary Instance(以下简称RSI)模式,能够通过底层分布式存储系统实时的读到另一个RocksDB最新写入的数据,使得从节点不仅能与主节点共享一份持久化文件数据,还能保持从节点内存数据紧紧跟随主节点,提供读取能力,和快速容灾能力。
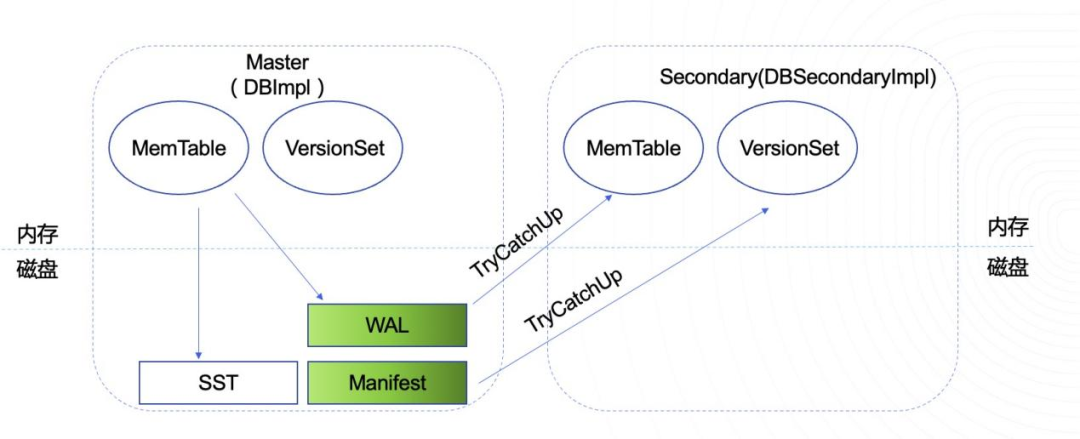
RSI如何做到数据的同步?
利用底层存储分布式的特点,无论在哪个节点,从节点都能看到与主节点一致的数据,因而可以由从节点定期Tail Read并回放主节点的WAL文件和Manifest文件至其内存中,以跟上主节点的内存中最近的数据。
RSI容灾
如果直接重启主节点,那么由于LSM架构的缺陷,主节点必须回放所有WAL日志至内存中后,才能对外提供服务。但是只读的从节点在同步数据后,其Memtable中的数据应与主一致。由于从节点不断的Tail Read主节点写下的WAL日志,因此从节点只需要先Tail Read 主节点写入最新的WAL日志即可同步好数据。然后新建一个主节点对象,再将内存中的Memtable和VersionSet切过去即可。
原生RocksDB在重启时,会先加载所有的WAL日志至内存中,再将内存中的Memtable全部Flush至Level 0文件。这样RocksDB就能获得一个“干净”的Memtable,然后对外提供服务。但是如果Memtable很大很多,那么Flush将会占用很多的时间。研究了RocksDB的SwitchWAL的过程后,通过代码改造,把这一部分移动到后台线程去做了(即把加载的Memtable转为只读的Immemtable)。

当主节点挂掉时,从节点内存中即有最新的写入数据,所以从节点抢到ZK的主后,即可将自己从只读节点转为可写节点,同时因为从同步Manifest文件,从已有所有的数据文件信息(与之前的主是同一份),无需进行数据迁移,因此可立刻对外提供服务。

采用此种优化后,我们线上的节点容灾时间大幅度降低,主从切换P99达到100ms内。
UKV

UKV是UCloud自研的计算存储分离的分布式KV存储系统。其存储底座为分布式统一存储Manul,Manul是具备自动数据平衡、异构介质存储、EC存储等功能的高性能、高可用、分布式存储服务。
UKV提供了集群管理服务,快速备份等常规功能,还针对US3元数据服务设计了数据结构,使其在UCloud日常的业务场景下提供更优秀的性能。
UKV使用UCloud自研的、由开源RocksDB定制化的URocksDB作为计算节点,同时依托Manul,实现了主从热备,热点节点快速分裂等特色功能。
热点分裂
由于UKV采用Range Sharding(因为对象存储有许多的列表服务,会有大量的范围读请求,因为我们采用Range Sharding来满足此项需求),所以比较容易出现热点问题,同时我们也需要集群的横向扩展能力,以保证集群服务能力,所以UCloud为UKV实现了热点分裂的功能。
设计原则
1、服务可用性
用户服务不可长时间停止
2、数据完整性
元数据完整性不容有误
3、失败回滚处理
有任何预期外状态能兜得住
4、自动化
自动检测热点节点做分裂,自动挑选空闲机器节点做目标
?分裂流程

首先Range信息是持久化在ConfigServer集群的。UKV启动时,如果它是Active节点,ConfigServer会给其下发Range。UKV会与ConfigServer保持心跳,不断上传节点信息,包括容量、QPS、机器状态。ConfigServer根据其状态判断节点是否触发热点分裂,如果触发,则会选择一个空闲节点作为目标端。
?分裂主要分为四个阶段:
1.SPLITTING_BEGIN
ConfigServer发起SplitRequest
2.HARDLINK_BEGIN
UKVRequest定期更新其硬链状态(向ConfigServer发送请求,如成功顺便带上计算的Range)
3.TARGET_OPEN
ConfigServer向Target发起OpenRequest请求(Target Open但不启动Compaction)
4.OPEN_COMPACTION_FILTER
ConfigServer使用心跳来让Source和Target开启Compaction Filter

我们主要应用计算存储分离的能力,利用硬链功能和RocksDB的Compaction特性,来保证数据不移动,且能过滤非Range数据。
?分裂时间

我们单节点大小上限设置为256G,实际线上300ms以内就可完成分裂,配合上上层的重试,分裂过程中用户是完全无感知的。
数据迁移

由于新老列表数据存储结构不一致(新的是字典序),老的是先目录再文件,所以还做了列表服务Proxy的兼容开发, 避免上层业务改动。

以现有扩容方式,无缝加入UKV-Meta,缩小影响范围。

我们研发了专用的Migration服务来为我们的UKV-Meta进行迁移,将存在于老架构的元数据迁移至UKV-Meta,以便将老架构占用的机器下机,降低业务成本。
Migration服务可以在不影响用户业务的情况下,安全的进行数据热迁移,保证数据的一致性,同时还具备迁移数据实时校验功能,防止迁移过程中出现问题。
总结
由于当前芯片、机柜等硬件资源价格高昂,使得云计算公司对CPU资源、存储资源的使用提出了更高、更精细化的需求。计算存储耦合的方式在扩容集群、扩充CPU、存储资源时,不仅会引发数据的Reshuffle,还会消耗比较大的网络带宽、以及CPU资源。
通过分离存储资源、计算资源,独立规划存储、计算的资源规格和容量,使得计算资源的扩容、缩容、释放,均可以比较快的完成,并且不会带来额外的数据搬迁代价。存储、计算也可以更好的结合各自的特征,选择更适合自己的资源规格和设计。

2、优刻得发布两款AI新品,助力用户打通视觉算法到场景应用关键环节
3、此芯科技与UCloud达成战略合作,打造端边云协同一体解决方案
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 Ucloud
Ucloud
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675