
Habitat Challenge 2022冠军方案:字节AI Lab提出融合传统和模仿学习的主动导航
机器之心专栏
在刚刚结束的国际机器人 Habitat 物体目标导航挑战赛 (Habitat ?ObjectNav Challenge 2022) 上,字节跳动 AI Lab-Research 团队提交的方法 ByteBOT 获得冠军。该方法结合了基于地图的传统方法以及端到端的深度模仿学习方法,集两种方法优势于一体,达到了当前最好的结果。
物体目标导航 (Object Navigation) 是智能机器人的基本任务之一。在此任务中,智能机器人在一个未知的新环境中主动探索并找到人指定的某类物体。物体目标导航任务面向未来家庭服务机器人的应用需求,当人们需要机器人完成某些任务时,例如拿一杯水,机器人需要先寻找并移动到水杯的位置,进而帮人们取到水杯。
Habitat Challenge 挑战赛由 Meta AI 等机构联合举办,是物体目标导航领域的知名赛事之一,已连续举办4届, 此前夺冠队伍出自 CMU、UC Berkerly、Facebook 等知名机构。2022 年的最新一届比赛共有 54 支参赛队参加,字节跳动 AI Lab-Research 团队的研究者针对现有方法的不足,提出了一种全新的物体目标导航框架。该框架巧妙地将模仿学习与传统方法结合,在关键指标 SPL 中大幅度超过了其他参赛队伍的结果。
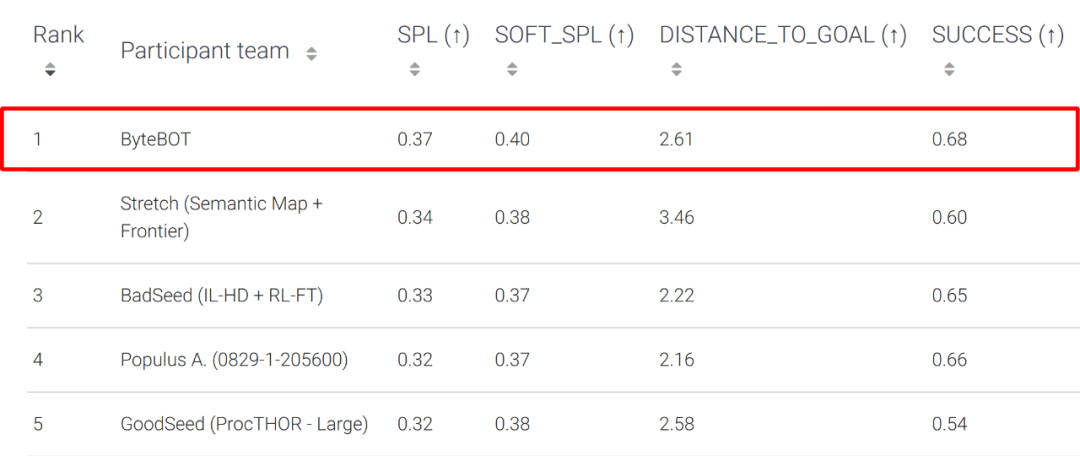
Test-Standard 榜单
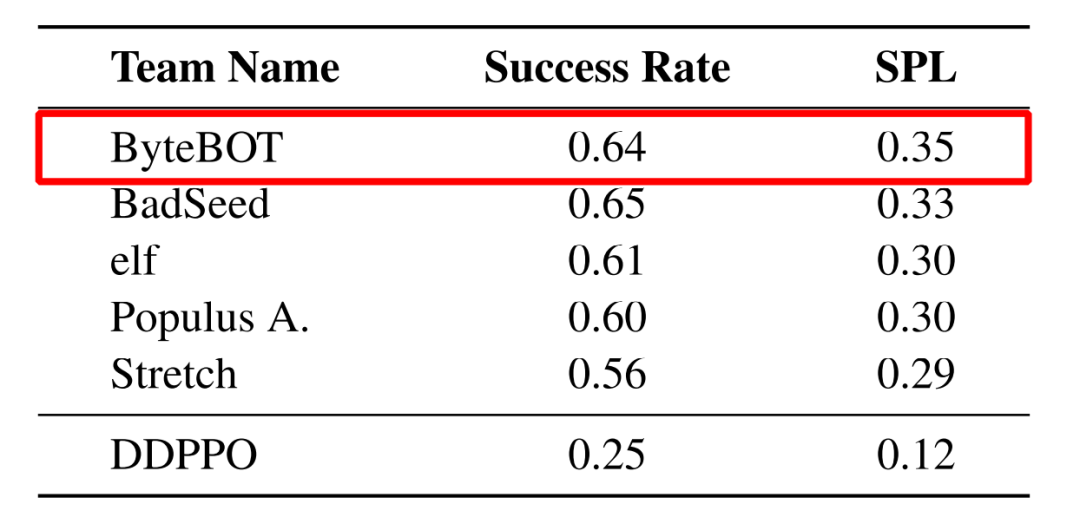
Test-Challenge 榜单
Habitat Challenge 比赛官网:https://aihabitat.org/challenge/2022/
Habitat Challenge 比赛 LeaderBoard:https://eval.ai/web/challenges/challenge-page/1615/leaderboard
研究动机
目前,物体目标导航方法可以大致分为两大类:端到端的方法;基于地图的方法。
端到端的方法提取输入传感器数据的特征,再送入一个深度学习模型中得到 action,此类方法一般基于强化学习或模仿学习(如图1Map-less methods);
基于地图的方法一般会构建显式或隐式地图,然后通过强化学习等方法在地图上选取一个目标点,最后规划路径并得到 action(如图1Map-based method)。
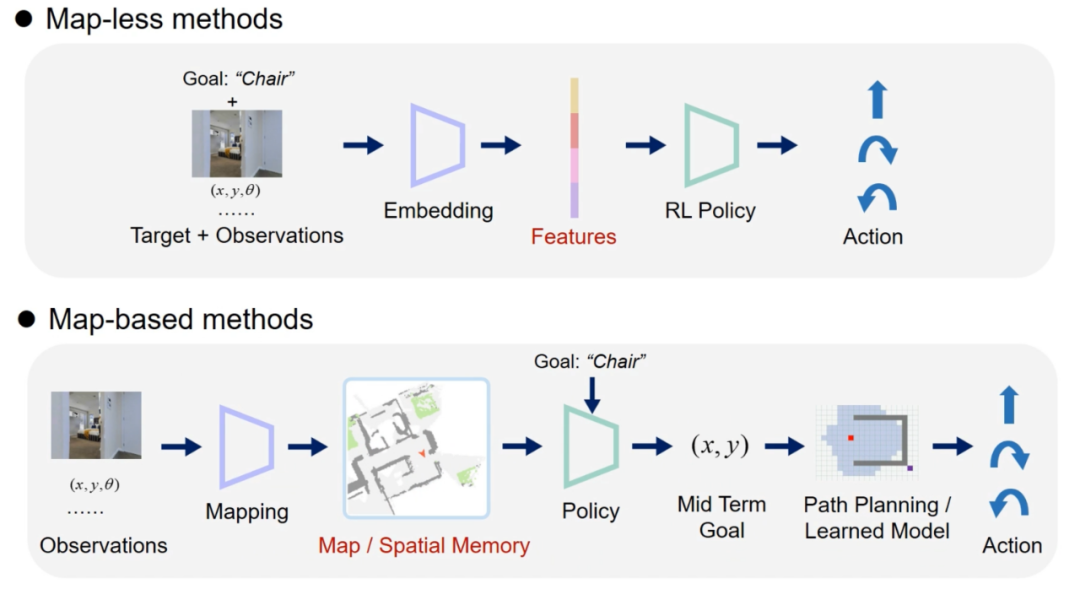
图1 端到端的方法 (上) 和基于地图的方法(下)流程示意图
在经过大量实验对比两类方法后,研究者们发现这两类方法各有优劣:端到端的方法不需要构建环境的地图,因此更加简洁,且不同场景的泛化能力更强。但由于网络需要学习编码环境的空间信息,依赖大量的训练数据,且难以同时学习一些简单的行为,比如在目标物体附近停下。而基于地图的方法使用栅格来存储特征或语义,具有显式空间信息,因此这类行为的学习门槛较低。但它非常依赖准确的定位结果,而且在一些如楼梯等环境中,需要人工设计感知和路径规划策略。
基于上述结论,字节跳动 AI Lab 的研究者们希望将两类方法的优势结合起来。然而这两类方法的算法流程差异很大,难以直接组合;此外也很难设计出一种策略直接融合两种方法的输出。因此研究者设计了一种简单但有效的策略,使两类方法根据机器人的状态交替进行主动探索和物体搜索,从而将各自的优势最大程度地发挥出来。
竞赛方法
算法主要有两个分支组成:基于概率地图的分支和端到端的分支。算法的输入是第一视角的 RGB-D 图像和机器人位姿,以及需要寻找的目标物体类别,输出是下一步动作 action。首先对 RGB 图像进行实例分割,并将其与其他原始输入数据一起传给两个分支。两个分支分别输出各自的 action,并由一个切换策略决定最终输出的 action。
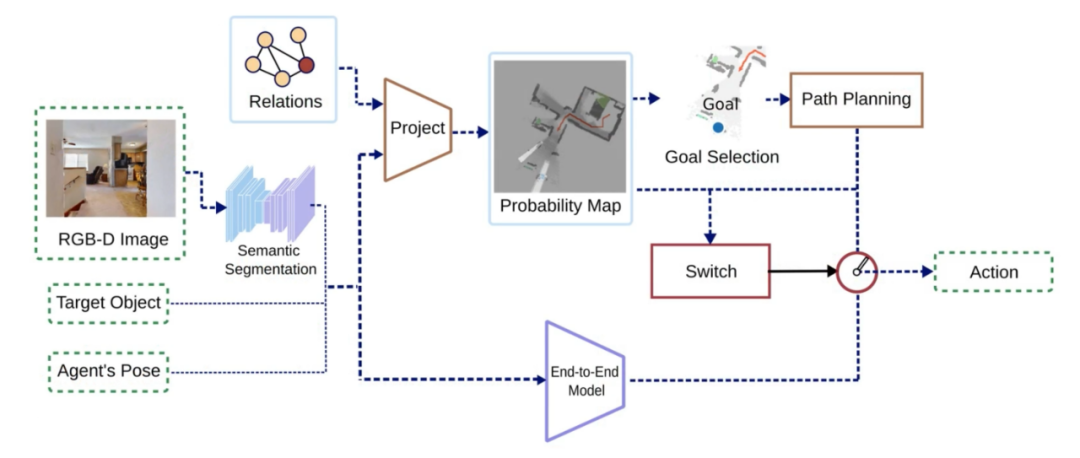
图 2? 算法流程示意图
基于概率地图的分支
基于概率地图的分支借鉴了 Semantic linking map[2] 的思想,并对作者原来发表在 IROS 机器人顶会的论文 [3] 方法进行了简化。该分支根据输入的实例分割结果、深度图和机器人位姿,一方面构建 2D 语义地图;另一方面基于预先学习的物体间关联概率,对一张概率地图进行更新。
概率地图的更新方式包括以下几种:当检测到目标物体但没有足够把握时(置信概率 confidence score 低于阈值),此时应该继续靠近观察,因此概率地图上相应区域的概率值应该提高(如图 3 上方所示);同理,如果检测到和目标物体有关联的物体(例如桌子和椅子放在一起的概率比较高),则相应区域的概率值也会提高(如图 3 下方所示)。算法通过选择概率最高的区域作为目标点,鼓励机器人靠近潜在目标物体以及关联物体进一步观察,直到找到置信概率高于阈值的目标物体。
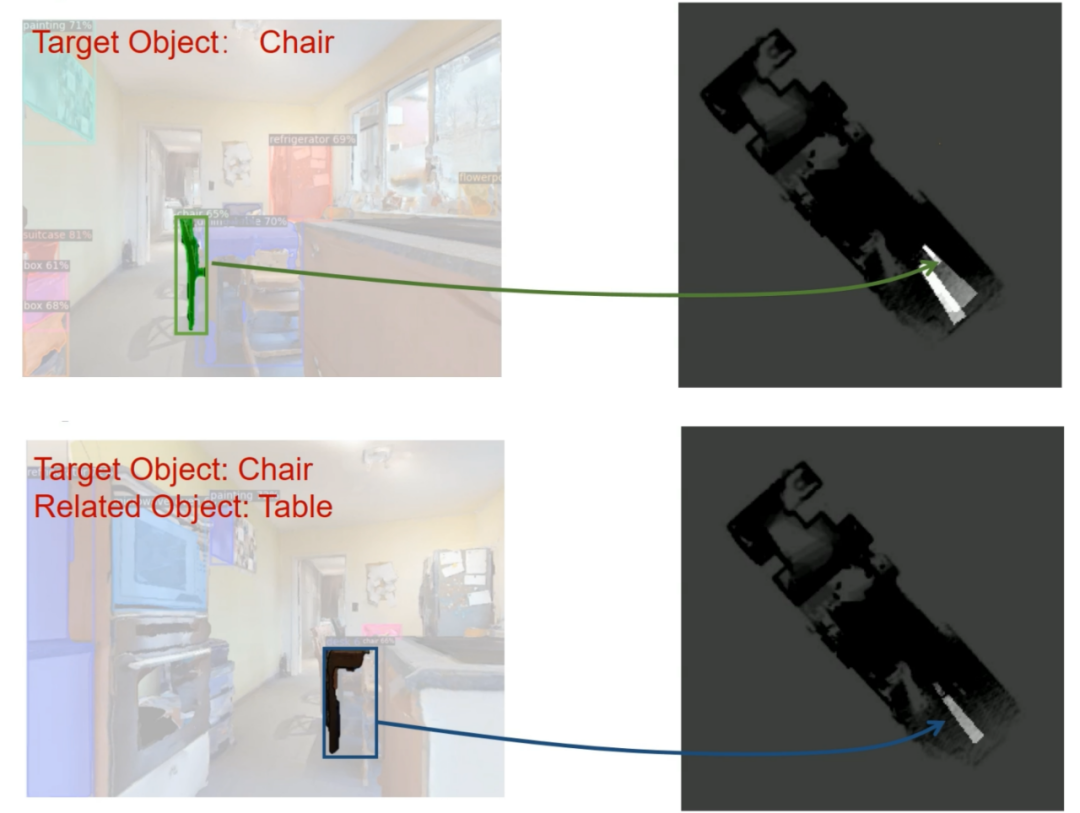
图 3? 概率地图更新方式示意图
端到端的分支
端到端分支的输入包括 RGB-D 图像、实例分割结果、机器人位姿,以及目标物体类别,并直接输出? action。端到端分支的主要作用是引导机器人像人类一样寻找物体,因此采用了 Habitat-Web[4] 方法的模型和训练流程。该方法基于模仿学习,通过在训练集中收集人类寻找物体的示例样本训练网络。
切换策略
切换策略主要根据概率地图和路径规划的结果,在概率地图分支和端到端分支输出的两个 action 中选择一个作为最终输出。当概率地图中没有概率大于阈值的栅格,机器人需要对环境进行探索;当地图上无法规划出可行路径时,此时机器人可能处于一些特殊环境(如楼梯),这两种情况下会采用端到端分支,使机器人具备足够的环境适应能力。其他情况则选择概率地图分支,充分发挥其在寻找目标物体方面的优势。
该切换策略的效果如视频所示,机器人一般情况下利用端到端分支高效地探索环境,一旦发现了可能的目标物体或关联物体,则切换到概率地图分支靠近观察,如果目标物体的置信概率大于阈值,则在目标物体处停下;否则该区域的概率值会不断降低,直到没有概率大于阈值的栅格,机器人重新切换回端到端继续探索。
从视频中可以看出,这种方法兼具了端到端方法和基于地图的方法的优势。两个分支各司其职,端到端方法主要负责探索环境;概率地图分支负责靠近感兴趣区域进行观察。因此该方法不仅能够在复杂场景探索(如楼梯),还降低了端到端分支的训练要求。
总结
针对物体主动目标导航任务,字节跳动 AI Lab-Research 团队提出了一种结合经典概率地图与现代模仿学习的框架。该框架是对传统方法与端到端方法相结合的一次成功的尝试。在 Habitat 竞赛中,字节跳动 AI Lab-Research 团队提出的方法大幅度超出了第二名及其他参赛队伍的结果,证明了算法的先进性。通过将传统方法引入目前主流的 Embodied AI 端到端方法,来进一步弥补端到端方法的一些不足,从而使得智能机器人在帮助人、服务人的道路上更进一步。
参考文献
[1] Yadav, Karmesh, et al. "Habitat-Matterport 3D Semantics Dataset." arXiv preprint arXiv:2210.05633 (2022).
[2] Zeng, Zhen, Adrian R?fer, and Odest Chadwicke Jenkins. "Semantic linking maps for active visual object search." 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020.
[3] Minzhao Zhu, Binglei Zhao, and Tao Kong. "Navigating to Objects in Unseen Environments by Distance Prediction." arXiv preprint arXiv:2202.03735 (2022).
[4] Ramrakhya, Ram, et al. "Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675