
「非结构化数据峰会」精彩速递:Zilliz Cloud 首发、Milvus 技术演进、生态实践全揭秘!| Q推荐

2022 年 9 月 24-25 日,首届非结构化数据峰会(2022 Unstructured Data Summit)在线上举行。本次峰会由 Zilliz 主办,主题为「矩阵革命,向量连接世界」,峰会设置了一系列 Keynote 和分论坛演讲,围绕人工智能在非结构化搜索领域的顶尖技术、热门话题、前沿观察展开分享和探讨,共同探索行业发展的新风向。
对于主办方 Zilliz,如果近期有关注科技圈投融资动态的话,应该对它不陌生。不久前,向量数据库公司 Zilliz 宣布完成 6000 万美元的新一笔融资,通过这轮融资 Zilliz 成功将其 B 轮融资规模进一步扩大至 1.03 亿美元。
这家刚满 5 岁的数据库公司正在做什么?这次的非结构化数据峰会又给行业带来了哪些新风向?
互联网快速发展至今天,全球仍然有 80% 的数据都以非结构化的形态存在,它们很难被有效利用,释放数据原本的价值。在过去的几十年中,虽然计算机已经能够高效处理普通的数值和文本类结构化数据,但对于图片、音视频、行为画像、化合物三维结构,以及基因序列等这些广泛存在的非结构化数据依旧不知所措,业界缺乏有效的非结构化数据处理手段。
在首届「非结构化数据峰会」上,Zilliz 创始人兼 CEO 星爵表示,非结构化数据因其自身的特点,天然难以被洞悉和管理,如何做好非结构化数据的处理,将会是广大企业面临的巨大挑战;作为较早研究非结构化数据的公司,Zilliz 已经取得了一定的成果,包括早前发布的 Towhee、Milvus、Attu、Feder 等项目,能够实现端到端的向量提取与转化、向量存储与分析、数据库图形化管理、算法处理过程可视化等。
此次峰会上,Zilliz 又有一款新产品发布,即全托管 Milvus 服务 Zilliz Cloud,定位为一个非结构化数据处理的云服务。
Zilliz Cloud 是 Milvus 开源社区原班人马基于全球最流行的开源向量数据库 Milvus 打造的全托管向量检索服务,在具备高可用、高可拓展、安全合规的基础上,提供了更加丰富的生态能力和开箱即用的高性能向量检索方案。
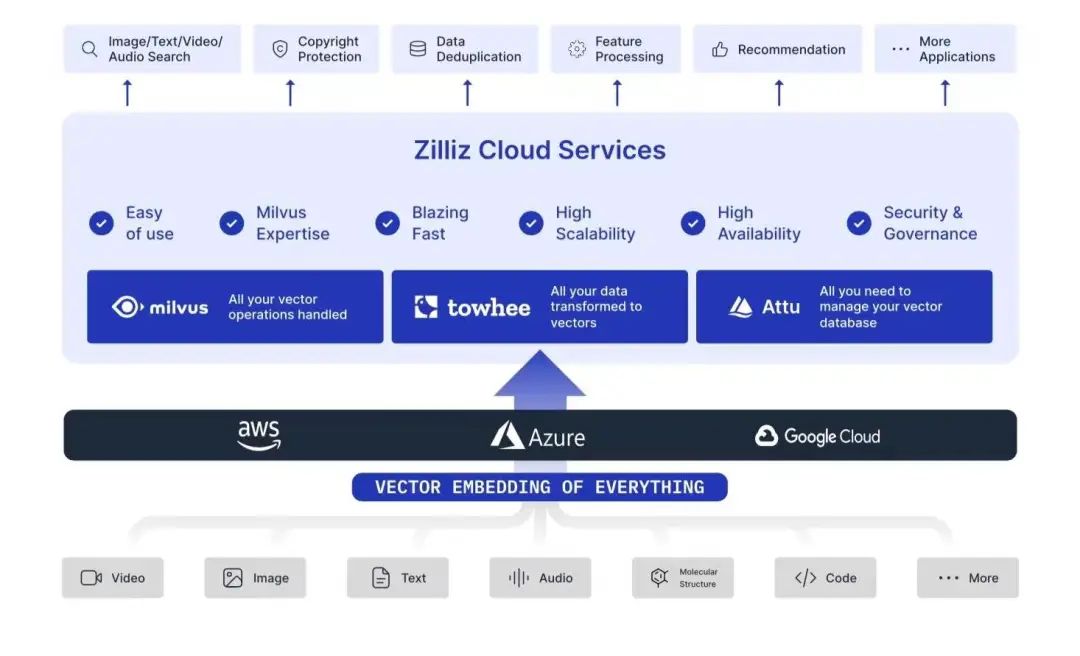
Zilliz cloud 架构大图
Zilliz 合伙人兼技术总监栾小凡向 InfoQ 表示:“Zilliz Cloud 最大的优势在于背靠 Milvus 开源社区。首先 Zilliz Cloud 的开发团队是 Milvus 的原班人马,我们可能是最了解非结构化数据和向量检索的那一拨人;另外这些年来通过在社区跟开源用户不断地交流、探讨,我们深知这个领域用户的需求和应用场景;除此之外,我们团队的工程师都非常有经验,几乎都构建过大规模、高可用的一些解决方案,同时也知道怎么去最大化利用 Milvus 的能力,我们更清楚 Milvus 这个系统应该用什么样的参数去跑,出了问题以后怎么样去解决。”
数据库托管后,又该如何进行非结构化数据的处理,如何通过最低成本来构建 AI 应用,实现模型在业务落地呢?
Zilliz 合伙人和产品总监郭人通博士,在其主题分享《Towhee:非结构化数据 ETL 流水线》中指出,在非结构化数据中提取 / 嵌入向量、数据标签和属性等信息,是构建 AI 应用,实现数据分析、检索的关键。为此,Zilliz 技术团队打造了 Towhee 这个专注于非结构化数据 ETL 的框架,它能帮助各行各业把各种不同的非结构化数据更加简便地转变成向量。
通过使用 Towhee,任何用户都能够基于 Python 代码一键构建面向生产的高性能非结构化数据处理流水线。Towhee 提供了一套优雅的函数式 Python 编程接口,以及一组覆盖日常工作所需要的工具集,只需要几行代码,就能够自动解决以下问题:将推理流水线内出现的代码(模型、算法、数据处理过程等)转换成对应的高性能实现,组织端到端的推理服务代码,一键生成 Docker 镜像等。
对于 Towhee 的研发历程,郭人通向 InfoQ 表示:“去年六七月份,我们受到一个社区诉求的启发,产生了研发一款非结构化数据 ETL 流水线的想法,10 月份 Towhee 0.1 版本诞生,之后进入了持续的模型验证阶段,直到今年 6 月份,我们推出了一个基于 Python 的、易用的、流水线定义的编程接口,开始做大量的面向性能和场景执行效率相关的工作,这个月底我们还将发布 Towhee 0.9 版本,新版本在一些大的视频、音频这类流式数据的处理效果上,会有比较大的提升。”
未来,Towhee 将在现有的 pipeline 定义接口上提供一个类似于 Spark、 Flink 的流水线定义接口;同时将更加深入地集成英伟达的技术生态,进一步提升整个流水线面向生产的一个执行效率;最后 Towhee 也会应社区很多用户的需求,去解决关于中文模型缺口的问题等。
在 Zilliz 的定义里,尽管 Towhee 是一个年轻的项目,但是它作为非结构性数据快速转换为向量的框架,实际上是使用 Milvus 系统的前一站。
作为 Zilliz 的核心产品, Milvus 又是如何一步步成长为现在的样子的呢?
峰会上,Linux Foundation AI & Data 基金会执行董事 Ibrahim Haddad 带来了《加速中的开源人工智能创新与合作》主题分享,他分享了开源项目 Milvus 是如何为 Linux 基金会书写了一段成功的故事,以及基金会在 AI & Data 领域如何帮助初创项目进行孵化、互惠共赢。
LF AI & Data 是 Linux 基金会的一个伞形基金会,支持人工智能、机器学习、深度学习和数据的开源创新。创建 LF AI & Data 是为了支持开源 AI、ML、DL 和数据,并创建一个可持续的开源 AI 生态系统,让使用开源技术创建 AI 和数据产品和服务变得容易。LF AI & Data 鼓励在中立的环境下以开放的治理进行协作,以支持开放源码技术项目的协调和加速。
星爵向 InfoQ 表示,2019 年 Zilliz 将 Milvus 项目正式开源,2020 年初便捐献给了 Linux Foundation AI & Data 基金会,随后的几年 Milvus 发展成全球最流行的向量数据库系统之一;凑巧的是就在峰会前夕, Milvus 项目超越了 ONNX 以及 Horovod 项目,成为了基金会里 star 数量最多的开源项目。
Ibrahim Haddad 指出,Milvus 项目于 2020 年 1 月加入 Linux Foundation AI & Data 基金会,只用了一年半时间便成功毕业,目前已经有超过 1600 名贡献者参与到这个项目,其中超过一半为持续活跃的贡献者;最令他感到惊讶的是,过去两年项目的提交增长了 270%,而项目的拉取请求周期只有 2.23 天,这意味着 Zilliz 团队花了非常多的时间在社区维护上。
从最初的想法萌生到 Milvus 开源,只用了一年的时间,随后便发布了 Milvus 1.0 版本;但是伴随非结构化数据的爆发式增长,1.0 版本下的数据孤岛、架构耦合、缺乏弹性、迭代慢等问题开始变得严重,如何让 Milvus 支撑千亿级向量动态扩展以及云原生等能力成为了横亘在眼前不得不解决的问题。为了解决以上问题,Milvus 团队下定决心去开发一个新的版本——Milvus 2.0。
在经过了一系列的测试之后,Milvus 2.0 于今年 2 月份正式发布,Milvus 2.0 是完全基于云原生架构进行开发的一个全新版本。随后经历了持续半年多的用户反馈、生产环境的经验积累,Milvus 2.0 更进一步迭代,性能更优、生态更完善、适配场景更丰富的 Milvus 2.1 于 7 月份发布。
相比于 2.0 版本, Milvus 2.1 支持内存多副本、查询高可用,能够解决读写分离及高并发等问题,另外还支持了 String 类型,系统性能也得到了大幅提升,比如支持了 ANN 索引,加入了全新的智能调度引擎,实现了 3.2 倍的性能提升,延迟低至 5ms 等。
值得一提的是,Zilliz 团队计划在九月底 / 十月初推出更新的 Milvus 2.2 版本,新版本将重点改进运维友好性、可观测性和稳定性。
Zilliz 首席工程师焦恩伟表示,在 Milvus 2.2 版本中最重磅的功能便是增加了磁盘索引(DiskANN)这一选项,相比于传统的纯内存索引方案,DiskANN 可以把用户的本地磁盘作为存储索引,牺牲少量的查询性能,但能换来大幅成本降低,用户可以使用更低成本的具备 SSD 且内存更小的机器进行数据库部署。同时新版本还将增加数据批量导入、RBAC 权限控制、查询 Pagination、限流与反压等功能。
Zilliz 向 InfoQ 表示,下一代的 Milvus 将重点围绕 AI 中台 / AI 业务两大用户群、高性能向量库 / 海量向量分析两大场景的需求继续进行迭代升级。
随着 AI 技术的快速发展和非结构化数据的爆炸式增长,基于向量的数据分析技术开始被普遍应用。然而,由于向量数据天然的高维特性,对其分析时的算力和存储需求远高于传统标量数据。如何快速高效地对分析向量数据,是近年来在学术界和工业界都备受关注的一个问题。
Zilliz 研究团队负责人和高级研究员易小萌博士将 Milvus 向量数据库面临的挑战总结为三点:向量数据处理的维度灾难、多路折衷的问题、复杂的查询语义挑战,并从数学的角度对这三个挑战进行了阐释。
针对 Milvus 向量检索的实际应用,易小萌举了一个商品搜索的例子:用户给出一个商品图片,除了想要搜索出跟这个图片上的商品一样或近似的商品外,很可能还希望看到它的价格。这种情况下,向量检索不仅仅要找到相似的向量,还需要找到该向量所携带的一些属性、条件等。从数学上的定义就是每一个 item 具备一个向量和一个属性的标签。Milvus 需要在给定一个向量查询需求的同时也给到一个属性的过滤条件,最后在符合属性过滤条件的向量里找到 K 个最相似的向量,然后进行合并分析,从而得出最接近用户需求的答案。
事实上,Milvus 向量数据库系统及相关技术早已在很多行业进行了场景验证。比如金融支付场景下,翼支付利用 Milvus 构建了更加智能的金融风控体系;视频直播场景,Milvus 帮助虎牙团队快速进行敏感区域特征识别与检索,提高视频内容安全审查效率;社交场景,Milvus 助力陌陌进行垃圾信息甄别、假照识别等;深度学习场景,Milvus 语义索引库帮助百度飞桨 PaddleNLP 提高语义检索的精准性等。
当然,目前非结构化数据和向量搜索依然是一个非常新的领域,除了需要更多的场景落地验证外,还需要更多的开发者与企业加入进来,共同构筑行业新生态。
当前围绕非结构化数据检索的开源技术生态处于快速发展和变革期,领域内的开源技术生态成熟度将直接影响上层应用的规模与成本,做出正确的技术决策,选择开放、活跃的生态社区,将是企业实现降本增效的最核心的手段之一。
Zilliz 合伙人和产品总监郭人通博士在其主题分享《非结构化数据搜索的工具链与技术生态》中提到,在应用生态层面,非结构化数据搜索在图搜、视频搜索、文本语义搜索、跨通道搜索、推荐 / 问答系统、版权保护、欺诈检测、数据查重、网络安全、药物发掘、异常检测等场景有着良好的应用前景;在行业生态层面,当前非结构化数据生态的基础软件和工具远远少于结构化数据生态,未来有着非常广阔的增长空间。
但是,不得不承认的是当前非结构化数据检索在可用性、安全性、性能、可靠性、可扩展性等方面依然面临较多的用户痛点。由于缺乏基础组件工具,各个关键技术点很难被串联起来,最终可能陷入“重复造轮子”的窘境,无法向客户输出系统性解决方案。
面对这些问题,Zilliz 开发了一系列的工具去解决一些关键应用环节的问题。在部署阶段,Zilliz 提供了 Milvus Sizing Tool 工具,能够自动生成部署脚本,帮助用户快速布置一个分布式的、大规模的向量数据库软件;在运维阶段,Zilliz 提供了开源工具 Attu,能够帮助用户管理硬件资源、负载状态等等;在业务提效方面,Zilliz 提供了一个向量召回工具 Feder,面向不同索引、不同层面,可视化地告诉用户召回过程中发生了什么,以及数据之间的关系是怎样。另外,Zilliz 还将上述工具进行整合,开发出了一个全托管的向量数据库 SaaS 云平台,也就是刚刚发布的 Zilliz Cloud。
除了内部三件套工具的集成外,在外部生态方面,Milvus 携手百度飞桨社区共建 AI 基础设施开源生态;Towhee 与上海人工智能实验室 OpenDataLab 社区开展了开放数据集领域的生态合作,打通 AI 落地的最后一公里;模型层面,Milvus 已经完成了与 Huggingface、TIMM、TorchVision 等软件的生态对接;数据处理层面,集成了 Numpy、OpenCV、FFmpeg 等开源软件;服务层面,也已经与 Docker、Triton、ONNX、TensorRT 等进行了连通等。目前 Milvus 和 Towhee 也在积极寻求生态合作,希望与合作伙伴们共同完善非结构化数据搜索的技术生态。
最后,借用 Zilliz 创始人兼 CEO 星爵的话来说,“十年后回头看现在,非结构化数据的价值几乎是完完全全没被挖掘出来的。”非结构化数据领域是一个全新的赛道,未来十年,一定会有更多的创新应用、场景涌现,而在生态建设的过程中,需要更多的开发者、产业链伙伴、创业公司加入进来,一起去探索、去共建非结构化数据的未来。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 InfoQ
InfoQ
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675