
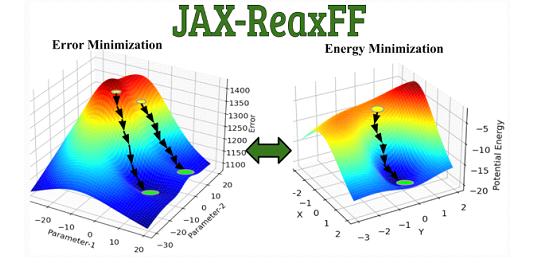
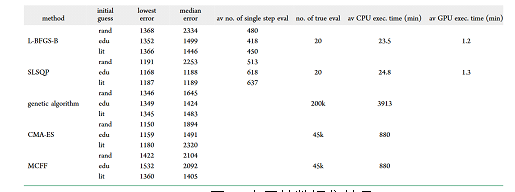
推荐 :谷歌JAX 助力科学计算
import jax.numpy as jnpfrom jax import grad, jit, vmapgrad_tanh = grad(jnp.tanh)print(grad_tanh(2.0))[OUT]:0.070650816
print(grad(grad(jnp.tanh))(2.0))print(grad(grad(grad(jnp.tanh)))(2.0))[OUT]:-0.136218680.25265405
fun: 代表需要进行向量化操作的具体函数; in_axes:输入格式为元组,代表fun中每个输入参数中,使用哪一个维度进行向量化; out_axes: 经过fun计算后,每组输出在哪个维度输出。
import jax.numpy as jnpimport numpy as npimport jax
a = np.array(([1,3],[23, 5]))print(a)[out]: [[ 1 3][23 5]]b = np.array(([11,7],[19,13]))print(b)[OUT]: [[11 7][19 13]]
print(jnp.add(a,b))#[[1+11, 3+7]]# [[23+19, 5+13]][OUT]: [[12 10][42 18]]
print(jax.vmap(jnp.add, in_axes=(0,0), out_axes=0)(a,b))#[[1+11, 3+7]]#[[23+19, 5+13]][OUT]: [[12 10][42 18]]
print(jax.vmap(jnp.add, in_axes=(0,0), out_axes=1)(a,b))# [[1+11, 3+7]]#[[23+19, 5+13]] 再以列转置输出[OUT]: [[12 42][10 18]]
from jax.numpy import jnpA, B, C, D = 2, 3, 4, 5def foo(tree_arg):x, (y, z) = tree_argreturn jnp.dot(x, jnp.dot(y, z))from jax import vmapK = 6 # batch sizex = jnp.ones((K, A, B)) # batch axis in different locationsy = jnp.ones((B, K, C))z = jnp.ones((C, D, K))tree = (x, (y, z))vfoo = vmap(foo, in_axes=((0, (1, 2)),))print(vfoo(tree).shape)
import jax.numpy as jnpfrom jax import jitdef slow_f(x):# Element-wise ops see a large benefit from fusionreturn x * x + x * 2.0x = jnp.ones((5000, 5000))fast_f = jax.jit(slow_f) # 静态编译slow_f;%timeit -n10 -r3 fast_f(x)%timeit -n10 -r3 slow_f(x)10 loops, best of 3: 24.2 ms per loop10 loops, best of 3: 82.8 ms per loop

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675