
7 Papers & Radios | 首篇扩散模型综述;没有3D卷积的3D重建方法
本周主要论文包括稀疏专家模型和扩散模型等论文综述,以及无 3D 卷积的 3D 重建方法在 A100?上重建一帧仅需 70ms。
目录:
A Review of Sparse Expert Models in Deep Learning
Through a Dog's Eyes: fMRI Decoding of Naturalistic Videos from the Dog Cortex
Efficient Methods for Natural Language Processing: A Survey
Git Re-Basin: Merging Models modulo Permutation Symmetries?
Diffusion Models: A Comprehensive Survey of Methods and Applications
SimpleRecon: 3D Reconstruction Without 3D Convolutions?
Deep learning-based kcat prediction enables improved enzyme-constrained model reconstruction
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:A Review of Sparse Expert Models in Deep Learning
作者:William Fedus、Jeff Dean 等
论文地址:https://arxiv.org/pdf/2209.01667.pdf
摘要:稀疏专家模型是一个已有 30 年历史的概念,至今依然被广泛使用,作为深度学习中的流行架构重新出现。此类架构包括混合专家系统(MoE)、Switch Transformer、路由网络、BASE 层等,所有这些架构都具有统一的思想,即每个样本都由参数的子集作用。稀疏专家模型已经在自然语言处理、计算机视觉和语音识别等不同领域展示出了显着的性能。
本文中,来自谷歌的 Jeff Dean 等人回顾了稀疏专家模型的概念,提供了通用算法的基本描述,最后强调了未来研究的方向。

密集与稀疏专家 Transformer 的架构比较。
推荐:Jeff Dean:我们整理了一份「稀疏专家模型研究」综述。
论文 2:Through a Dog's Eyes: fMRI Decoding of Naturalistic Videos from the Dog Cortex
作者:Erin M. Phillips 等
论文地址:https://www.jove.com/t/64442/through-dog-s-eyes-fmri-decoding-naturalistic-videos-from-dog
摘要:过去 15000 年,狗与人类共同进化。现在,狗狗常作为宠物栖息在人类生活环境中。有时狗狗像人一样在家中观看视频,仿佛是看懂了。那么,狗狗眼里的世界是什么样子的?
近日,来自埃默里大学的一项研究从狗的大脑中解码了视觉图像,首次揭示了狗的大脑如何重建它所看到的东西。这项研究发表在《可视化实验期刊》上。

实验设计:首先使用 3T MRI 扫描参与者,同时让参与者观看投射到 MRI 孔后部屏幕上的汇编视频。对于狗来说,通过事先训练,将它们的头放在定制的下巴托中,以达到头部稳定的位置
推荐:狗狗如何看世界?人类研究员要解码狗脑中的视觉认知。
论文 3:Efficient Methods for Natural Language Processing: A Survey
作者:Marcos Treviso 等
论文地址:https://arxiv.org/pdf/2209.00099.pdf
摘要:近日,来自希伯来大学、华盛顿大学等多所机构的十几位研究者联合撰写了一篇综述,归纳总结了自然语言处理(NLP)领域的高效方法。效率通常是指输入系统的资源与系统产出之间的关系,一个高效的系统能在不浪费资源的情况下产生产出。在 NLP 领域,我们认为效率是一个模型的成本与它产生的结果之间的关系。

该研究归纳整理的高效 NLP 方法。
推荐:资源受限如何提高模型效率?一文梳理 NLP 高效方法。
论文 4:Git Re-Basin: Merging Models modulo Permutation Symmetries
作者:Samuel K. Ainsworth 等
论文地址:https://arxiv.org/pdf/2209.04836.pdf
摘要:深度学习能够取得如此成就,得益于其能够相对轻松地解决大规模非凸优化问题。尽管非凸优化是 NP 困难的,但一些简单的算法,通常是随机梯度下降(SGD)的变体,它们在实际拟合大型神经网络时表现出惊人的有效性。
本文中,来自华盛顿大学的多位学者研究了在深度学习中,SGD 算法在高维非凸优化问题上的不合理有效性。

假设你训练了一个 A 模型,你的朋友训练了一个 B 模型,这两个模型训练数据可能不同。不过没关系,使用本文提出的 Git Re-Basin,你能在权值空间合并这两个模型 A+B,而不会损害损失。
推荐:零障碍合并两个模型,大型 ResNet 模型线性连接只需几秒,神经网络启发性新研究。
论文 5:Diffusion Models: A Comprehensive Survey of Methods and Applications
作者:Ling Yang 等
论文地址:https://arxiv.org/pdf/2209.00796.pdf
摘要:本综述来自加州大学 & Google Research 的 Ming-Hsuan Yang、北京大学崔斌实验室以及 CMU、UCLA、蒙特利尔 Mila 研究院等众研究团队,首次对现有的扩散生成模型(diffusion model)进行了全面的总结分析,从 diffusion model 算法细化分类、和其他五大生成模型的关联以及在七大领域中的应用等方面展开,最后提出了 diffusion model 的现有 limitation 和未来的发展方向。

三类扩散模型。
推荐:扩散模型爆火,这是首篇综述与 Github 论文分类汇总。
论文 6:SimpleRecon: 3D Reconstruction Without 3D Convolutions
作者:Mohamed Sayed 等
论文地址:https://nianticlabs.github.io/simplerecon/resources/SimpleRecon.pdf
摘要:从姿态图像重建 3D 室内场景通常分为两个阶段:图像深度估计,然后是深度合并和表面重建。最近,多项研究提出了一系列直接在最终 3D 体积特征空间中执行重建的方法。虽然这些方法已经获得出令人印象深刻的重建结果,但它们依赖于昂贵的 3D 卷积层,限制其在资源受限环境中的应用。
现在,来自 Niantic 和 UCL 等机构的研究者尝试重新使用传统方法,并专注于高质量的多视图深度预测,最终使用简单现成的深度融合方法实现了高精度的 3D 重建。

SimpleRecon 的重建速度非常快,每帧仅用约 70ms。
推荐:没有 3D 卷积的 3D 重建方法,A100 上重建一帧仅需 70ms。
论文 7:Deep learning-based kcat prediction enables improved enzyme-constrained model reconstruction
作者:Feiran Li 等
论文地址:https://www.nature.com/articles/s41929-022-00798-z
摘要:酶周转数(kcat)是了解细胞代谢、蛋白质组分配和生理多样性的关键,但实验测量的 kcat 数据往往稀疏且嘈杂。查尔姆斯理工大学的研究团队提供了一种深度学习方法(DLKcat),用于仅根据底物结构和蛋白质序列对来自任何生物体的代谢酶进行高通量 kcat 预测。DLKcat 可以捕获突变酶的 kcat 变化并识别对 kcat 值有强烈影响的氨基酸残基。研究人员应用这种方法来预测 300 多种酵母物种的基因组规模 kcat 值。
该团队还设计了一个贝叶斯管道,以根据预测的 kcat 值参数化酶约束的基因组规模代谢模型。由此产生的模型在预测表型和蛋白质组方面优于先前管道中相应的原始酶约束基因组规模代谢模型,并使研究人员能够解释表型差异。DLKcat 和酶约束的基因组规模代谢模型构建管道是揭示酶动力学和生理多样性的全球趋势,并进一步阐明大规模细胞代谢的宝贵工具。
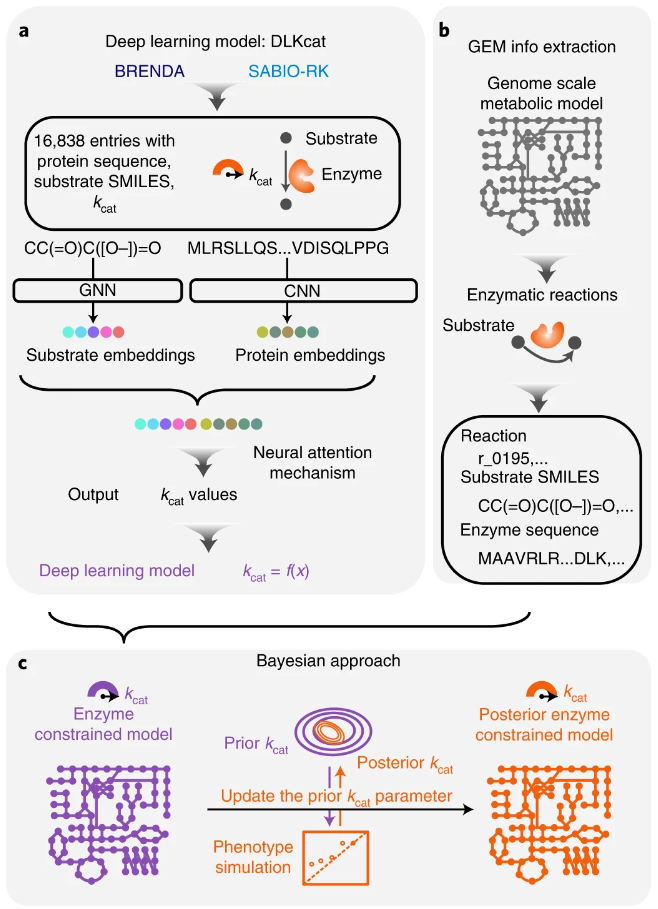
用于 ecGEM 参数化的 kcat 深度学习。
推荐:使用深度学习方法高通量预测代谢酶的 kcat,或可揭开细胞工厂的秘密。
1. SPACE-3: Unified Dialog Model Pre-training for Task-Oriented Dialog Understanding and Generation.? (from Jian Sun)
2. Distribution Aware Metrics for Conditional Natural Language Generation.? (from John Canny)
3. Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contest.? (from Lillian Lee)
4. PANCETTA: Phoneme Aware Neural Completion to Elicit Tongue Twisters Automatically.? (from Eduard Hovy)
5. Multilingual Transformer Language Model for Speech Recognition in Low-resource Languages.? (from Jian Wu)
6. Automatic Error Analysis for Document-level Information Extraction.? (from Claire Cardie)
7. Alexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance.? (from Yang Liu, Dilek Hakkani-Tur, Eugene Agichtein)
8. Hierarchical Attention Network for Explainable Depression Detection on Twitter Aided by Metaphor Concept Mappings.? (from Erik Cambria)
9. Chain of Explanation: New Prompting Method to Generate Higher Quality Natural Language Explanation for Implicit Hate Speech.? (from Haewoon Kwak)
10. ImageArg: A Multi-modal Tweet Dataset for Image Persuasiveness Mining.? (from Diane Litman)
1. Diffusion Models in Vision: A Survey.? (from Mubarak Shah)
2. Robust Category-Level 6D Pose Estimation with Coarse-to-Fine Rendering of Neural Features.? (from Alan Yuille)
3. ComplETR: Reducing the cost of annotations for object detection in dense scenes with vision transformers.? (from Bernt Schiele)
4. Skin Lesion Recognition with Class-Hierarchy Regularized Hyperbolic Embeddings.? (from Lei Zhang)
5. Test-Time Training with Masked Autoencoders.? (from Yu Sun, Alexei A. Efros)
6. TEACH: Temporal Action Composition for 3D Humans.? (from Michael J. Black)
7. Neural Point-based Shape Modeling of Humans in Challenging Clothing.? (from Michael J. Black)
8. Placing Human Animations into 3D Scenes by Learning Interaction- and Geometry-Driven Keyframes.? (from Dinesh Manocha)
9. A Benchmark and a Baseline for Robust Multi-view Depth Estimation.? (from Thomas Brox)
10. HARP: Autoregressive Latent Video Prediction with High-Fidelity Image Generator.? (from Pieter Abbeel)
1. Tuple Packing: Efficient Batching of Small Graphs in Graph Neural Networks.? (from Andrew William Fitzgibbon)
2. Clifford Neural Layers for PDE Modeling.? (from Johannes Brandstetter, Max Welling)
3. Fairness in Forecasting of Observations of Linear Dynamical Systems.? (from Quan Zhou)
4. Differentially Private Estimation of Hawkes Process.? (from Hongyuan Zha)
5. Private Synthetic Data for Multitask Learning and Marginal Queries.? (from Michael Kearns)
6. Layerwise Bregman Representation Learning with Applications to Knowledge Distillation.? (from Manfred K. Warmuth)
7. Active Learning of Classifiers with Label and Seed Queries.? (from Nicolò Cesa-Bianchi)
8. Structured Q-learning For Antibody Design.? (from Jan Peters)
9. In-situ animal behavior classification using knowledge distillation and fixed-point quantization.? (from Liang Wang)
10. Knowledge-based Deep Learning for Modeling Chaotic Systems.? (from Abdenour Hadid)
??THE END?
转载请联系本公众号获得授权
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675