
ClickHouse 挺快,esProc SPL 更快
ClickHouse vs Oracle
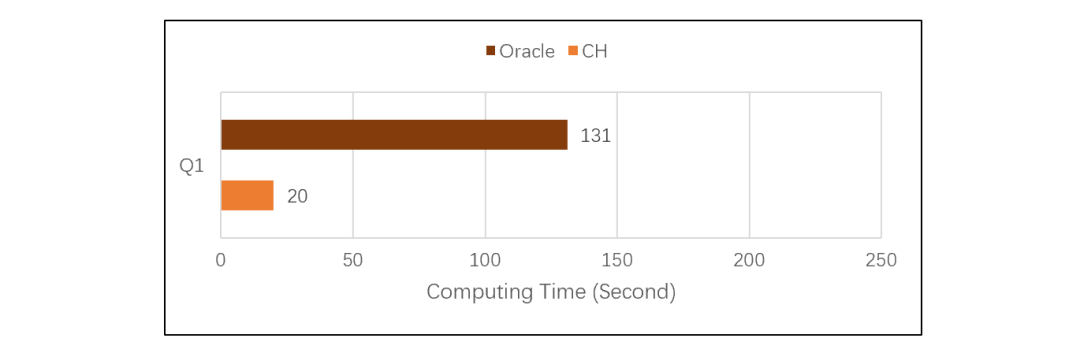

esProc SPL 登场
SELECT mod(id, 100) AS Aid, max(amount) AS AmaxFROM test.tGROUP BY mod(id, 100)
SELECT * FROM test.t ORDER BY amount DESC LIMIT 100
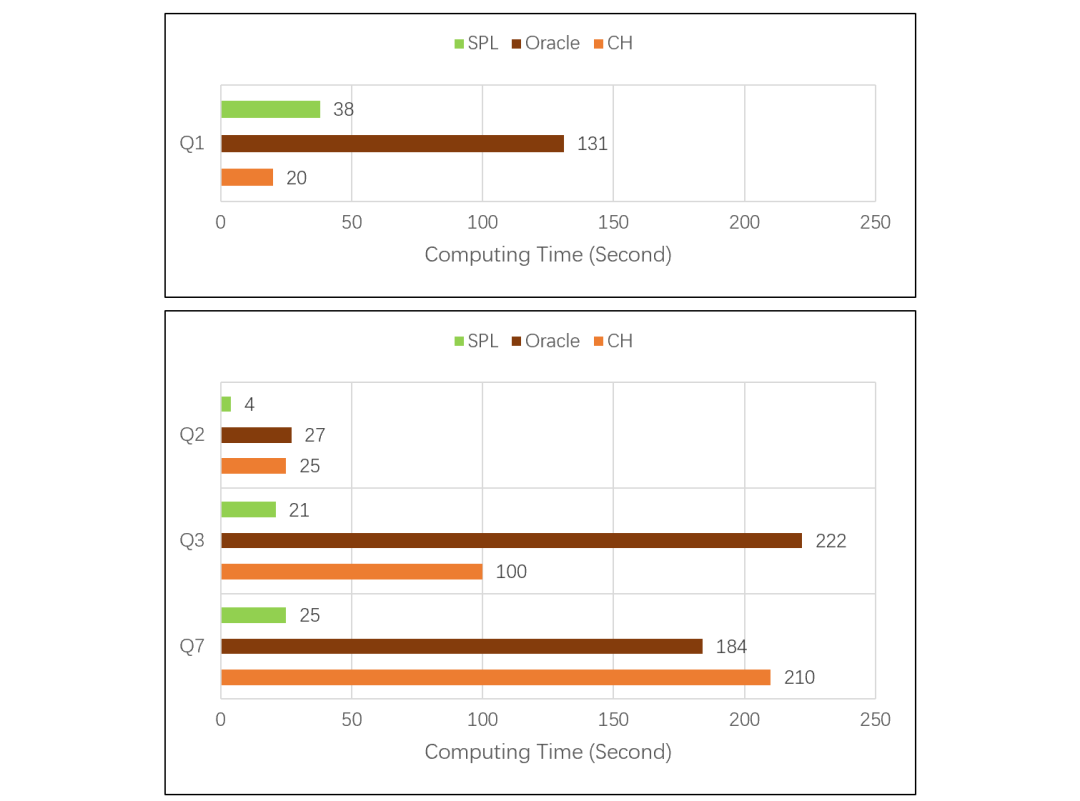
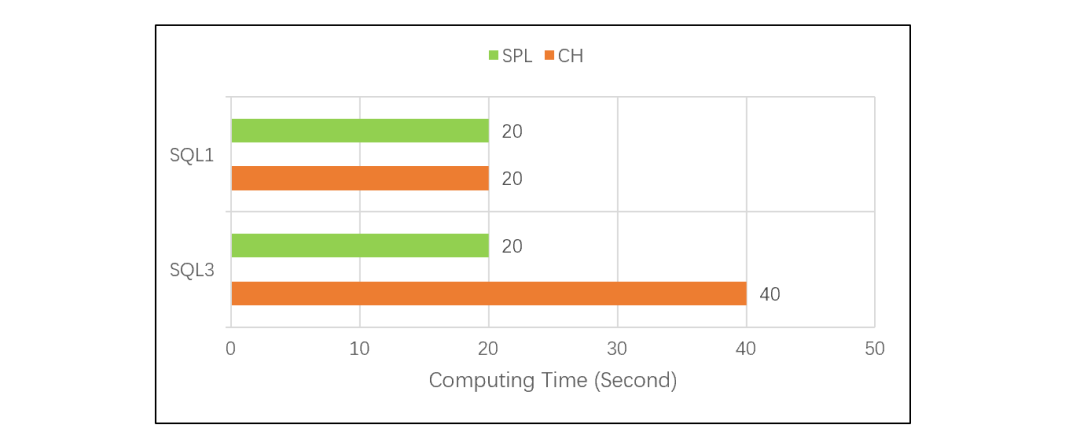
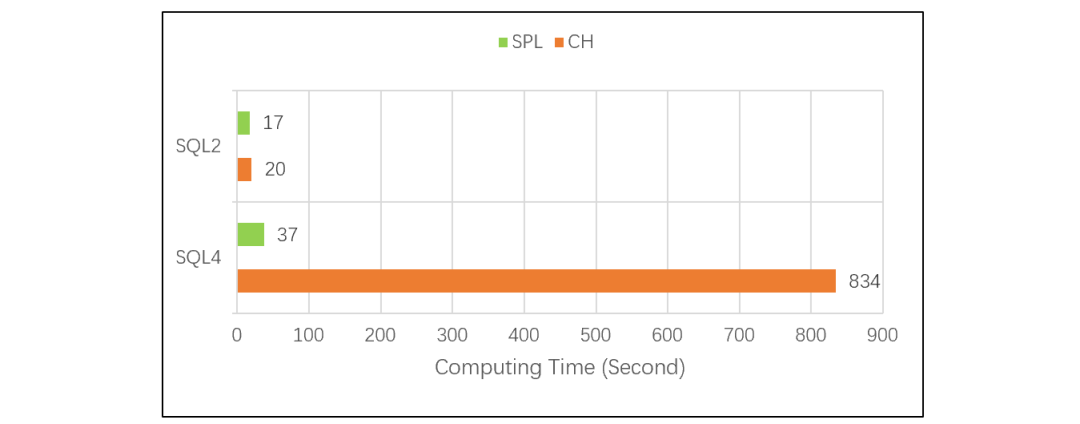
进一步的差距
SELECT *FROM (SELECT mod(id, 100) AS Aid, max(amount) AS AmaxFROM test.tGROUP BY mod(id, 100)) A??JOIN?(???SELECT?floor(id?/?200000)?AS?Bid,?min(amount)?AS?Bmin???FROM?test.t???GROUP?BY?floor(id?/?200000)??)?B???ON?A.Aid?=?B.Bid
这种情况下,对比测试的结果是 CH 的计算时间翻倍,SPL 则不变:
| A | B | |
| 1 | =file("topn.ctx").open().cursor@mv(id,amount) | |
| 2 | cursor A1 | =A2.groups(id%100:Aid;max(amount):Amax) |
| 3 | cursor | =A3.groups(id\200000:Bid;min(amount):Bmin) |
| 4 | =A2.join@i(Aid,A3:Bid,Bid,Bmin) | |
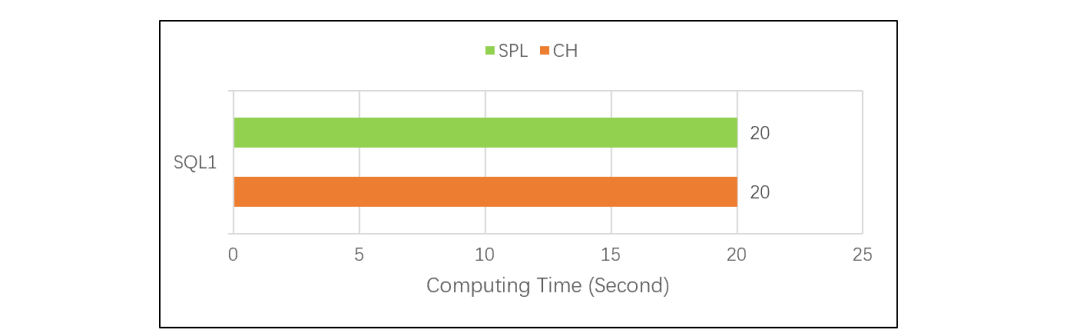
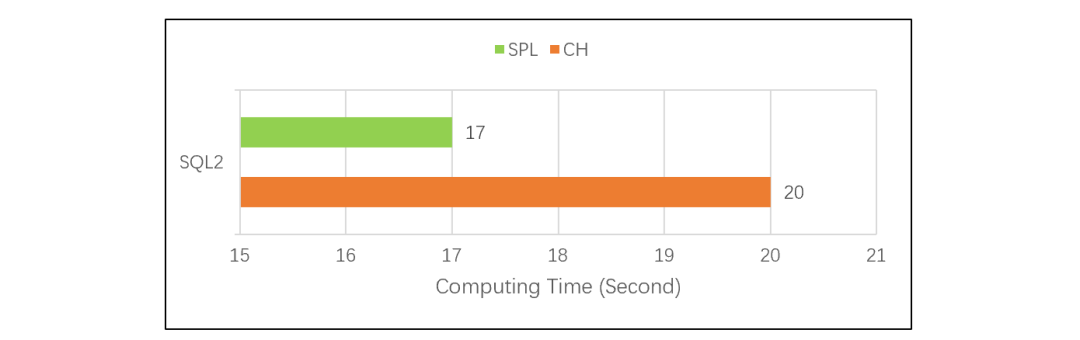
再将 SQL2 常规 TopN 计算,调整为分组后求组内 TopN。对应 SQL 是:
SELECTgid,groupArray(100)(amount)?AS?amountFROM(????SELECTmod(id, 10) AS gid,amount??FROM?test.topn??????ORDER?BYgid ASC,amount DESC)?AS?aGROUP?BY?gid
这个分组 TopN 测试的对比结果是下面这样的:
| A | |
| 1 | =file("topn.ctx").open().cursor@mv(id,amount) |
| 2 | =A1.groups(id%10:gid;top(10;-amount)).news(#2;gid,~.amount) |
不只是跑得快
| A | B | |
| 1 | =["etype1","etype2","etype3"] | =file("event.ctx").open() |
| 2 | =B1.cursor(id,etime,etype;etime>=date("2021-01-10") && etime<date("2021-01-25") && A1.contain(etype) && …) | |
| 3 | =A2.group(id).(~.sort(etime)) | =A3.new(~.select@1(etype==A1(1)):first,~:all).select(first) |
| 4 | =B3.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime<t1+7).etime, null)))) | |
| 5 | =A4.groups(;count(~(1)):STEP1,count(~(2)):STEP2,count(~(3)):STEP3) | |
CH 的 SQL 无法实现这样的计算,我们以 ORA 为例看看三步漏斗的 SQL 写法:
with e1 as (select gid,1 as step1,min(etime) as t1from Twhere etime>= to_date('2021-01-10', 'yyyy-MM-dd') and etime<to_date('2021-01-25', 'yyyy-MM-dd')and eventtype='eventtype1' and …group by 1),with e2 as (select gid,1 as step2,min(e1.t1) as t1,min(e2.etime) as t2from T as e2inner join e1 on e2.gid = e1.gidwhere e2.etime>= to_date('2021-01-10', 'yyyy-MM-dd') and e2.etime<to_date('2021-01-25', 'yyyy-MM-dd')and e2.etime > t1and e2.etime < t1 + 7and eventtype='eventtype2' and …group by 1),with e3 as (select gid,1 as step3,min(e2.t1) as t1,min(e3.etime) as t3from T as e3inner join e2 on e3.gid = e2.gidwhere e3.etime>= to_date('2021-01-10', 'yyyy-MM-dd') and e3.etime<to_date('2021-01-25', 'yyyy-MM-dd')and e3.etime > t2and e3.etime < t1 + 7and eventtype='eventtype3' and …group by 1)selectsum(step1) as step1,sum(step2) as step2,sum(step3) as step3frome1left join e2 on e1.gid = e2.gidleft join e3 on e2.gid = e3.gid
总结一下:CH 计算某些简单场景(比如单表遍历)确实很快,和 SPL 的性能差不多。但是,高性能计算不能只看简单情况快不快,还要权衡各种场景。对于复杂运算而言,SPL 不仅性能远超 CH,代码编写也简单很多。SPL 能覆盖高性能数据计算的全场景,可以说是完胜 CH。

重磅!开源SPL交流群成立了
简单好用的SPL开源啦!
为了给感兴趣的技术人员提供一个相互交流的平台,
特地开通了交流群(群完全免费,不广告不卖课)
需要进群的朋友,可长按扫描下方二维码

本文感兴趣的朋友,请到阅读原文去收藏 ^_^
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

![邓嘚儿 氛围感拉满[兔子] ](https://imgs.knowsafe.com:8087/img/aideep/2021/11/14/6b3ed088d1160bf5e592b81b26959fd8.jpg?w=250)




 程序员狗哥
程序员狗哥
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675