
用Python爬取手机壁纸,太简单了吧!

人生苦短,快学Python!
在Python爬虫的学习过程中,爬取图片几乎是每个初学者都练习过的项目,比如我们之前就分享过:如何用Python快速爬取小姐姐的美图?
其中我们需要先利用Python中的request库和正则构建获取函数,以此爬取页面中的图片url。

最近有位同学分享他抓包获取到了小米壁纸api接口,那这样再去手机壁纸,可就太简单了!我们只需访问接口,再解析json数据,即可获取精准的壁纸图片url。
小米壁纸是什么,其实就是小米手机系统自带的app,包含了各种风格的手机壁纸。

提供接口的同学给的链接实在太长了,我试了试删去了不太影响主要作用的参数,剩下的接口如下所示:
https://thm.market.xiaomi.com/thm/****/type=WALLPAPER&tag=二次元宅
如果你使用浏览器打开该链接,就能得到10张壁纸图片的详细数据。其中参数cardStart控制翻页,调整参数tag选择不同的标签的壁纸图片。

剩下的只需调用Python下载图片到本地即可,具体代码如下所示。
def?download_img(url,?file_name):
????res?=?requests.get(url)
????img?=?open(file_name,?'wb')
????img.write(res.content)
????img.close()
简单解释一下,requests发起get请求拿到图片的信息。
open打开文件,以file_name(比如111.jpg)为文件名,wb代表以二进制覆盖写。
如果我们想批量下载壁纸图片怎么办呢?for循环就完事了呀!
在交互式环境中输入如下命令:
for?i?in?range(1,20):
????url=?f"https://thm.market.xiaomi.com/thm/*****/&cardStart={i}&type=WALLPAPER&tag=二次元宅"
????html?=?requests.get(url).content
????data?=?json.loads(html.decode('utf-8'))
????for?j?in?range(10):?#?一页10个
????????image_url?=?data['apiData']['cards'][0]['products'][j]['imageUrl']
????????name?=?data['apiData']['cards'][0]['products'][j]['name']
????????print(name,?image_url)
????????image_name?=?f"./二次元宅/{name}.png"
????????download_img(image_url,?image_name)
在上述代码中,json.loads()函数是将json格式数据转换为字典。接着再搭配for循环获取某一页的10个image_url和name,其中name用于设置壁纸图片的本地路径+名称(使用相对路径下载到本地)。
最后调用前文中自定义的函数download_img(),将每一张壁纸图片都下载到二次元宅文件夹中。

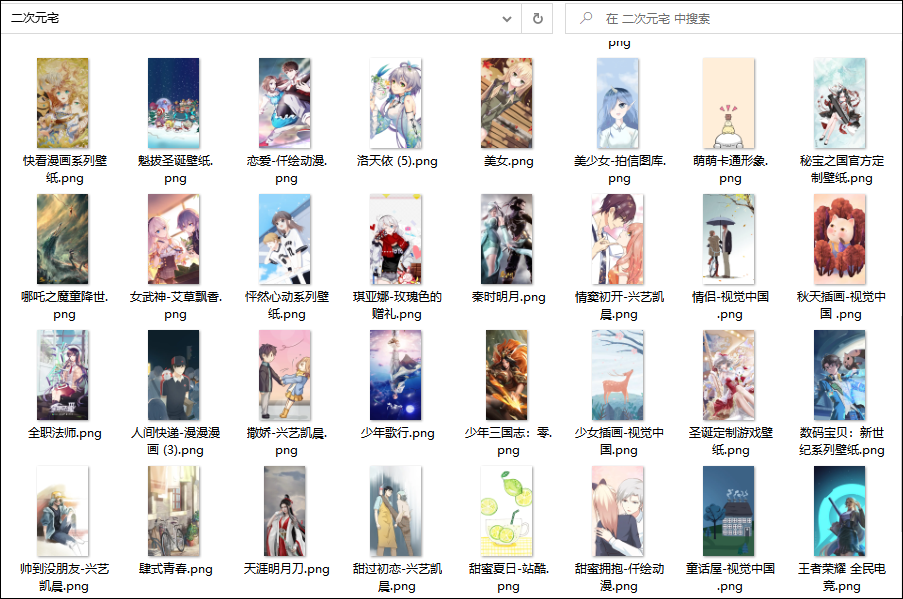
打开本地路径下的二次元宅的文件夹,会发现所有的图片都已经被下载到本地。
是不是,太简单了吧!

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675