
英伟达:从图像中抽象出概念再生成新的图像,网友:人类幼崽这个技能AI终于学会了
羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
人类幼崽2岁就能做的事,AI竟然才学会?
早在2017年,就有网友吐槽:2岁幼童只要见过一次犀牛的照片,就能在其他图片里认出不同姿势、视角和风格的卡通犀牛,但AI却做不到。

直到现在,这一点终于被科学家攻克了!
最新研究发现,只要给AI喂3-5张图片,AI就能抽象出图片里的物体或风格,再随机生成个性化的新图片。

有网友评价:非常酷,这可能是我这几个月来看到的最好的项目。

它是如何工作的?
让我们先来看几个例子。
当你上传3张不同角度的陶瓷猫照片,可能会得到以下4张新图像:两只在船上钓鱼的陶瓷猫、陶瓷猫书包、班克斯艺术风格的猫以及陶瓷猫主题的午餐盒。

同样的例子还有艺术品:

铠甲小人:

碗:

不只是提取图像中的物体,AI还能生成特定风格的新图像。
例如下图,AI提取了输入图像的绘画风格,生成了一系列该风格的新画作。

更神奇的是,它还能将两组输入图像相结合,提取一组图像中的物体,再提取另一组的图像风格,两者结合,生成一张崭新的图像。

除此之外,有了这个功能,你还可以对一些经典图像“下手”,给它们添加一些新元素。

那么,这么神奇的功能背后是什么原理呢?
尽管近两年来,大规模文本-图像模型,如DALL·E、CLIP、GLIDE等,已经被证明有很强的自然语言推理能力。
但有一点:如果用户提出一些特定的需求,比如生成一张包含我最喜欢的童年玩具的新照片,或者把孩子的涂鸦变成一件艺术品,这些大规模模型都很难做到。
为了应对这一挑战,研究给出了一个固定的、预先训练好的文本-图像模型和一个描述概念的小图像集(用户输入的3-5张图像),目标是找到一个单一的词嵌入,从小集合中重建图像。由于这种嵌入是通过优化过程发现的,于是称之为“文本倒置(Textual Inversion)”。
具体来说,就是先抽象出用户输入图像中的物体或风格,并转换为“S?”这一伪词(pseudo-word),这时,这个伪词就可以被当作任何其他词来处理,最后根据“S?”组合成的自然语句,生成个性化的新图像,比如:
“一张S?在海滩上的照片”、”一幅挂在墙上的S?的油画”、”以S2?的风格画一幅S1?”。
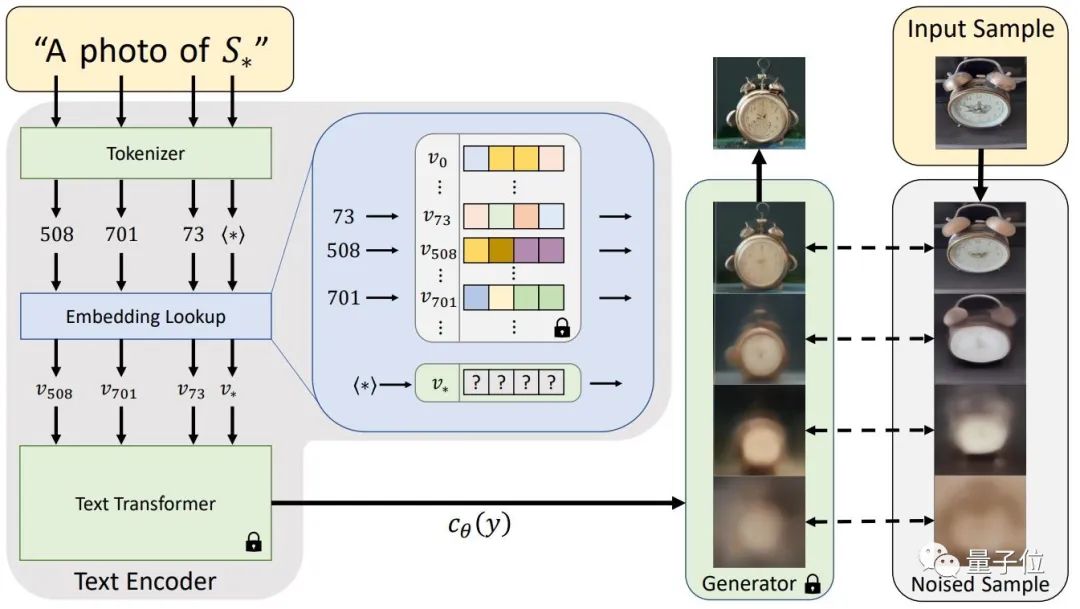
值得注意的是,由于本次研究应用了一个小规模、经过策划的数据集,因此在生成图像时能有效地避免刻板印象。
例如下图,当提示“医生”时,其他模型倾向于生成白种人和男性的图像,而本模型生成图像中则增加了女性和其他种族的人数。

目前,该项目的代码和数据已开源,感兴趣的小伙伴可以关注一下。
作者介绍
该篇论文来自特拉维夫大学和英伟达的研究团队,作者分别是Rinon Gal、Yuval Alaluf、Yuval Atzmon、Or Patashnik、Amit H. Bermano、Gal Chechik、Daniel Cohen-Or。
第一作者Rinon Gal,是特拉维夫大学的计算机科学博士生,师从Daniel Cohen-Or和Amit Bermano,主要研究方向是在减少监督的条件下生成2D和3D模型,目前在英伟达工作。

参考链接:
[1]https://textual-inversion.github.io/
[2]https://github.com/rinongal/textual_inversion
[3]https://arxiv.org/abs/2208.01618
[4]https://twitter.com/_akhaliq/status/1554630742717726720
[5]https://rinongal.github.io/
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里 关注公众号:拾黑(shiheibook)了解更多 [广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 量子位
量子位
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675