
谷歌华人研究员发布MobileNeRF,渲染3D模型速度提升10倍

??新智元报道??
??新智元报道??
【新智元导读】最近谷歌发布了全新的MobileNeRF模型,直接将神经辐射场拉入移动时代,内存需求仅为1/6,渲染3D模型速度提升10倍,手机、浏览器都能用!
2020年,神经辐射场(NeRF)横空出世,只需几张2D的静态图像,即可合成出该模型的3D场景表示,从此改变了3D模型合成的技术格局。

NeRF以一个多层感知器(MLP)来学习表示场景,评估一个5D隐式函数来估计从任何方向、任何位置发出的密度和辐射,可在体渲染(volumic rendering)框架下用于生成新图像。
?
NeRF经过最小化多视图色彩一致性的损失的优化后,相比传统的生成方式,对于新视图能够保留更好的图像细节。
?
但目前主流的NeRF实现方式仍然存在弊端,即需要专门的渲染算法,而这些算法与当下常见的硬件并不匹配。
?

?
传统的NeRF实现使用体积渲染算法,用于在光线沿线的数百个采样位置为每个像素都运行一次大规模MLP,以便估计和密度和辐射度。这种渲染过程对于交互式的可视化来说太慢了,没法用于实时渲染。
?
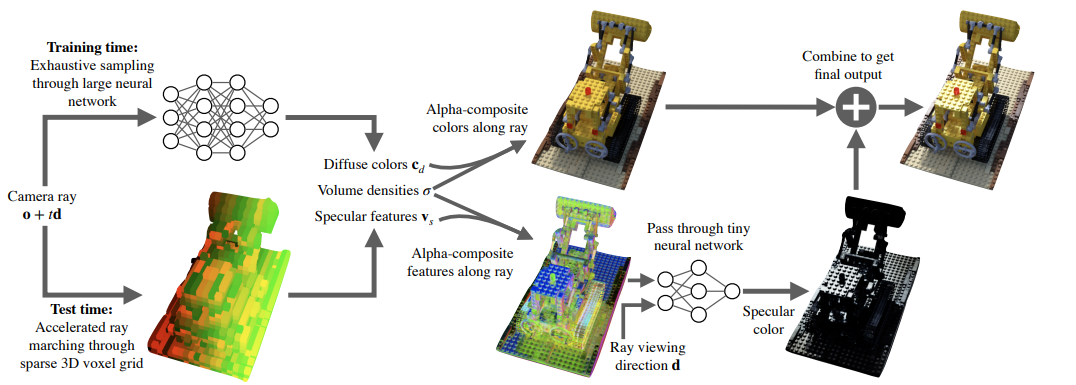
最近有研究将NeRF烘焙(baking)到稀疏的3D voxel grid中来解决这个问题,比如SNeRG中的每个激活的voxel包含不透明度、漫反射颜色和学习的特征向量。
?
从SNeRG绘制图像分为两个阶段:第一阶段使用光线行进来累积沿每条光线的预计算漫反射颜色和特征向量,第二阶段使用对累积特征向量进行操作的轻型MLP来产生与视图相关的残差,该残差添加到ac累积漫反射颜色,这种预计算和延迟渲染方法将NeRF的渲染速度提高了三个数量级。
?
?
但SNeRG仍然依靠光线在稀疏体素网格中行进来生成每个像素的特征,因此无法充分利用GPU的并行性。
?
此外,SNeRG需要大量的GPU内存来存储体积纹理,所以没办法在手机等移动端设备上运行。
?
最近,Google Research和西蒙菲莎大学的研究人员联合提出一种全新的模型MobileNeRF,成功将NeRF模型部署在多种常见的移动设备上。
?

论文链接:https://arxiv.org/abs/2208.00277
Demo链接:https://mobile-nerf.github.io/
?
NeRF由一组纹理多边形(textured polygons)表示,其中多边形大致沿着场景表面排布,纹理图集存储不透明度和特征向量。
?
在渲染图像阶段,MobileNeRF利用带Z-buffering的经典多边形光栅化管道为每个像素生成特征向量,并将其传递给GLSL片段着色器中的轻型MLP运行以生成输出颜色。
?
渲染管道不按深度顺序对光线采样或对多边形排序,因此只能对二进制不透明进行建模。但MobileNeRF可以充分利用了现代图形集成电路硬件中z缓冲区和片段着色器提供的并行性,因此在标准测试场景上比SNeRG快10倍,而且输出质量几乎相同。
?

?
此外,MobileNeRF只需要一个标准的多边形渲染管道,可以在几乎所有的计算平台上实现和加速,因此可以在手机和其他以前无法以交互速率支持NeRF可视化的设备上运行。
?
作者还提供了一个演示网站,可以在web浏览器上实时渲染。
?

文章的第一作者Zhiqin Chen是西蒙菲莎大学的三年级博士生。于2019年获得西蒙菲莎大学硕士学位,2017年获得上海交通大学学士学位。主要研究兴趣是计算机图形学,主修几何建模和机器学习。
?
NeRF进入移动时代
NeRF进入移动时代
?
给定一个经过校准的图像集合,NeRF的目标就是找到一个高效的新视图合成(novel-view synthesis)的表征,包括一个多边形网格(polygonal mesh),其纹理图存储了特征和不透明度。
?
在渲染时,给定一个摄像机的姿势,MobileNeRF采用两阶段的延迟渲染过程:
?
渲染阶段1:将网格栅格化为屏幕空间,并构建一个特征图像,即在GPU内存中创建一个延迟渲染缓冲区。
?

?
渲染阶段2:通过运行在片段着色器中的神经延迟渲染器将这些特征转换成彩色图像,即一个小型MLP,能够接收特征和视图方向并输出一个像素颜色。
?
表示法的训练分为三个阶段,从一个经典的类似于NeRF的连续表示法逐渐转向一个离散的表示法。
?

?
训练阶段1:连续训练。训练一个类似于NeRF的连续不透明度模型,其中体积渲染正交点来自于多边形mesh
?

?
在不损失一般性的情况下,研究人员描述了合成360度场景中使用的多边形网格,首先在单位立方体中以原点为中心定义一个大小为P×P×P的regular grid,通过为每个创建一个顶点来实例化V,通过为每个网格边缘创建一个连接四个相邻voxel顶点的四边形(两个三角形)来实例化。
?

?
在优化过程中,将顶点位置初始化为V=0,即对应于regular Euclidean lattice,并对其进行正则化处理,以防止顶点离开voxel,并在优化问题受限的情况下使其返回到中间位置。
?
训练阶段2:对不透明度进行二进制化,因为虽然经典的栅格化可以很容易地将碎片分解,但对于半透明碎片的处理却很麻烦。
?
一般硬件实现的渲染管道并不支持半透明的网格。渲染半透明网格需要对每一帧进行排序,因此要按从后到前的顺序执行渲染,以保证正确的alpha合成。
?
研究人员通过将平滑不透明度转换为离散/分类不透明度解决了这一问题。
?
为了通过photometric supervision的方式来优化离散不透明度,模型还采用了直通式估计器(straight-through estimator)。需要注意的是,其梯度是透明地通过离散化操作,不考虑平滑透明度和离散透明度的值。为了稳定训练,研究人员选择对连续和离散模型进行联合训练。
?
训练阶段3:提取一个稀疏的多边形网格,将不透明度和特征烘焙成纹理图,并存储神经递延着色器的权重。网格被存储为OBJ文件,纹理图被存储为PNG文件,而延迟着色器的权重则被存储在一个(小型)JSON文件中。
?
在传统的光栅化pipeline中,想要获得高质量的光栅化结果,混叠(aliasing)是一个必须考虑的问题。虽然经典的NeRF通过半透明体来实现平滑的边缘,但半透明体需要对每帧多边形排序。
?
研究人员通过采用超采样抗锯齿来克服这个问题。虽然可以简单地执行四次/像素,并对得到的颜色进行平均,但延迟神经着色器的执行仍然是该技术的计算瓶颈。研究人员通过简单地平均化特征来缓解这个问题,即平均化延迟神经着色器的输入,而非平均化其输出。
?
在将其送入神经延迟着色器之前,对子像素特征进行平均,以产生抗混叠表示。
?
由于MobileNeRF采用了标准的GPU光栅化管道,所以需要的实时渲染器可以在HTML网页中运行。
?
在实验阶段,研究人员设置了一系列的实验来测试MobileNeRF在各种场景和设备上的表现。
?
使用了三个数据集进行测试:NeRF的8个合成360°场景,LLFF的8个正面场景,以及Mip-NeRF 360的5个无界360°户外场景。
?

?
主要的对比模型为SNeRG,因为它是目前唯一一个可以在常见的设备上实时运行的NeRF模型。
?

?
渲染的分辨率与训练的图像相同,800×800的合成图像,1008×756的正向图像,以及1256×828的无界图像,并且在chrome浏览器上测试所有的方法,并在一个完整的圈中旋转/平移相机,以渲染360个框架。
?
在测试时,GPU内存消耗和存储成本相比SNeRG来说也降低了很多。
?

?
其中SNeRG由于其网格表示方法不同,无法表示无界的360°场景,并且由于兼容性或内存不足的问题,无法在手机或平板电脑上运行。
?
在渲染质量上来看,用常见的PSNR、SSIM和LPIPS指标与其他方法进行比较后,可以发现MobileNeRF的质量与SNeRG大致相同。
?

?
当摄像机处于适当的距离时,我们的方法实现了与SNeRG相似的图像质量。当相机被放大时,SNeRG倾向于呈现过度平滑的图像。
?

?
在多边形的计数中,可以看到MobileNeRF对每个场景产生的顶点和三角形的平均数量,以及与初始网格中所有可用顶点/三角形相比的百分比。由于MobileNeRF只保留了可见的三角形,所以在最终的网格中大部分顶点/三角形被移除。
?

?
阴影网格(shading mesh)对比下,文中展示了提取的没有纹理的三角形网格。三角形面大部分是轴对齐的,而不是与实际物体表面对齐。
?

?
因此,如果希望有更好的表面质量,需要设计出更好的正则化损失或训练目标,但优化顶点也确实改善了渲染质量。


关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/
 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675