作者:金一鸣? ?审校:陈之炎
本文选择一个简单直观的应用实战——根据股价基本 历史数据来预测股市涨跌。
支持向量机(Support Vector Machine, SVM)是一种通过监督学习方式来进行学习的分类和回归模型,在多数情况下,人们都会用这个模型来进行较小规模的二分类任务的求解。支持向量机主要的思想是在特征空间上找到一个与正负样本边界最大的线性分类器,而求解边界最大化的问题从数学的角度来看即是求解凸二次规划(Convex Quadratic Programming)的最优化算法。支持向量机可用于实现多种场景的分类问题,当训练数据线性可分时,利用硬边界最大化实现数据的二分类;另一方面支持向量机在训练数据线性不可分的时候,通过使用核函数(Kernel Function)以及软边界最大化来进行从样本空间的非线性可分到特征空间的线性可分,此算法最精彩和最经典的技巧也在于此。假设现在有一堆红球和黑球,对于一个简单的分类问题(如图1.1-1),首先,需要找出一个分离超平面(Hyperplane,在二维坐标轴上可以理解为一条直线)使得红球和黑球能够很好的分开,此时,可以有无数个平面可以作为这个二分类问题的解,所以需要找出一个最优的分离超平面,将分类的错误率降到最低,由此引出了边界最大化的概念,也就是定义正负数据集样本同时到超平面的最大距离为该数据集的最大边界。定义由边界最大化求出的分离超平面为: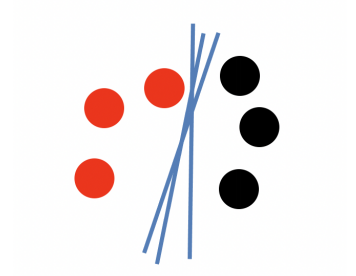
图1.1-1 二分类问题可以有无数条分割线来对其分类
其中x是数据集特征空间的一个特征向量,w是对应的法向量,b可以理解成截距。对
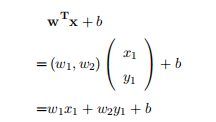
于 可以理解成一个分类标签,整个式子就是一个分类器了,计算过程如下:通过找到最合适的(w,b)也就可以找到唯一边界最大的分离超平面。红球(正样本)也就可以表示成
可以理解成一个分类标签,整个式子就是一个分类器了,计算过程如下:通过找到最合适的(w,b)也就可以找到唯一边界最大的分离超平面。红球(正样本)也就可以表示成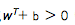 ?(正样本超平面),同样的黑球(负样本)可以表示成
?(正样本超平面),同样的黑球(负样本)可以表示成 (负样本超平面)。因此该问题的决策函数他就是线性支持向量机):y =?sign?(x?+ b)?????????????????????????1.1.?2
(负样本超平面)。因此该问题的决策函数他就是线性支持向量机):y =?sign?(x?+ b)?????????????????????????1.1.?2
为了求解决策函数,这里需要再引入函数边界和几何边界的概念:- 函数边界:一个数据点到超平面的距离|w ? x + b|,所以最小函数边界可以表示为:
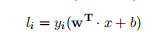 ? ? ? ? ? ??1.1. 3
? ? ? ? ? ??1.1. 3
 ? ? ? ? ? ? ? ? ? ? ??1.1. 4
? ? ? ? ? ? ? ? ? ? ??1.1. 4
其中 (1.1.3) 为样本数据点到超平面的边界,注意这里右边式子乘 yi 是因为分类结果是取决于 w · x + b 和分类的标签 yi 两者的符号的一致性。- 几何边界:在函数边界基础上抽象成空间上的概念,可表示空间中点到平面的距离。对法向量w加上规范化的限制,这样即使w和b成倍增加也不会影响超平面在空 间中的改变。所以最小几何边界可表示成:
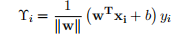 ? ? ? ? ?1.1. 5
? ? ? ? ?1.1. 5
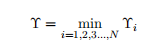 ? ? ? ? ? ? ??1.1. 6
? ? ? ? ? ? ??1.1. 6
其中Yi表示几何边界,其中||w||代表w的范数,这里直接取L2范数,比如对于三维的w,那么:
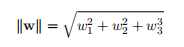
这里找到了到样本点到最小距离的两个分离超平面,接下来求边界函数的最大值,即找到最大边界超平面求解最优化问题:
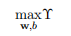
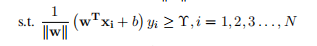 ? ??1.1. 7
? ??1.1. 7
注意:这里为了考虑该式子对于函数边界和几何边界的普适性,几何边界(w,b)可以是函数边界(nw,nb),n是任意倍数,所以,为了方便计算,首先假设边界为1,即Y ? ||w|| = 1。可将原式改写成:
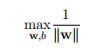
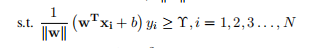 ??1.1. 8
??1.1. 8
由于求 的问题也就是求
的问题也就是求 所以式子也可以写成:
所以式子也可以写成:
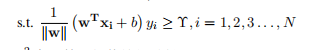 ?1.1. 9
?1.1. 9
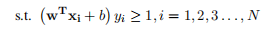 ? ? ? ? ?1.1. 10
? ? ? ? ?1.1. 10
所以当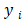 ?= 1 时,Xi + b>1;当?= —1 时,
?= 1 时,Xi + b>1;当?= —1 时,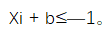 通过这种凸二次规划方式求出来的最大边界分离超平面是具有唯一性的,另外也可以利用拉格朗日函数(Lagrange function)的方法,通过将原始问题(Primal Problem)转化成对偶问题(Dual Problem):
通过这种凸二次规划方式求出来的最大边界分离超平面是具有唯一性的,另外也可以利用拉格朗日函数(Lagrange function)的方法,通过将原始问题(Primal Problem)转化成对偶问题(Dual Problem): ? ??1.1. 11
? ??1.1. 11
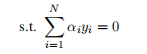

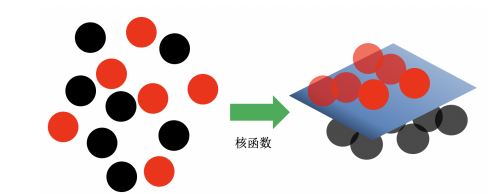
其中a为所要求解的最优的拉格朗日乘子,对这个问题进行求解(此处省略推导过程)。现实中,很多问题可不仅仅像线性可分那样简单,为此必须采取一些技巧来对更复杂的问题进行求解。通常对求完全解线性可分的支持向量算法叫硬边界(Hard Margin)支持向量机;如果允许一些噪声或者异常数据的分类错误,那么也可以找到一条近似于线性可分的超平面来对数据进行分类,这种对计算非线性可分(接近线性可分的数据,见图1.2-1中(a))的数据的算法叫软边界(Soft Margin)支持向量机。如 果有数据完全不能线性可分(见图1.2-1中(b)),这个时候我们就需要采取一定的转化技巧,也就是利用核技巧来进行分类问题的求解(见图1.2-2)。这节主要介绍一下对数据集线性不可分时应该采取的算法。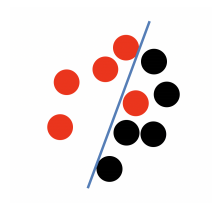 ? ? ? ? ? ? ??
? ? ? ? ? ? ??
(a)?近似于线性可分? ? ? ? ? ? (b) 完全不能线性可分图 1.2-1: 现实中各种分类情况
对于处理近似线性可分的数据,可以对原来线性可分的最优化问题进行改进,容许一些异常或者例外的数据,这里通过对每一个样本都引人一个松驰变量ξ 来使函数间隔大于等于1,相当于放宽了求解条件,所以将原有约束条件改成: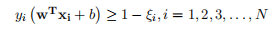 ? ? ??1.2.12
? ? ??1.2.12

 ? ? ? ? ? ? ? ? ? ? ???1.2.13
? ? ? ? ? ? ? ? ? ? ???1.2.13
其中C为惩罚系数,一般取决于实际情况,C的值越大,说明惩罚的强度越大,也说明 对误分类点惩罚越大(可以简单理解成对分类错误宽容度就越差,太大了容易导致过拟合)。最终软边界的原始问题就写成: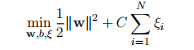
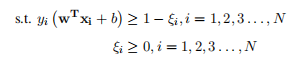 ? ??1.2.14
? ??1.2.14
这样原始问题就变成了容许错误分类样本的存在,同样地,这也是一个凸二次规划问题, 最终可以求得(w, b, ξ)的值(这里需要注意的是这次解并不是唯一的)从而得到其中一个超平面,通过新的决策函数: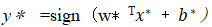
其中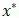 是新的样本点,y*是新的决策函数,通过软边界的容错技巧,可以求出新的分类结果。如果现有的一批数据完全线性不可分,利用上述两种方法肯定是不能解决问题的,为此用到了一个转化的思想。当数据在当前特征空间分布是非线性可分的时候,如果有一个函数可以将数据从低维空间映射到高维空间,那么是不是就可能是线性可分了呢?此时的算法其实就多了一步函数映射的过程,其他步骤依然可以按照之前线性可分问题一样求解。这里定义存在一个函数?(x),可以将原空间线性不可分的数据映射到新空间中,变成线性可分。通过对(1.2.11)进行变形,将核函数引入到对偶问题的式子中,可得:
是新的样本点,y*是新的决策函数,通过软边界的容错技巧,可以求出新的分类结果。如果现有的一批数据完全线性不可分,利用上述两种方法肯定是不能解决问题的,为此用到了一个转化的思想。当数据在当前特征空间分布是非线性可分的时候,如果有一个函数可以将数据从低维空间映射到高维空间,那么是不是就可能是线性可分了呢?此时的算法其实就多了一步函数映射的过程,其他步骤依然可以按照之前线性可分问题一样求解。这里定义存在一个函数?(x),可以将原空间线性不可分的数据映射到新空间中,变成线性可分。通过对(1.2.11)进行变形,将核函数引入到对偶问题的式子中,可得: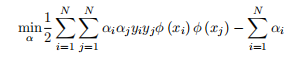
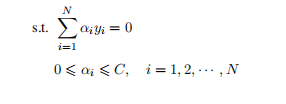 ? ? ? ? ? ??????1.2.15
? ? ? ? ? ??????1.2.15
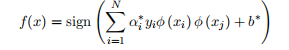 ? ? ? ? ? ? ? ? ? 1.2.16
? ? ? ? ? ? ? ? ? 1.2.16
若核函数??(xi) ??(xj )为正定核,则该对偶问题是凸二次规划问题,也就可以求得最优解。图1.2-2 ?二分类问题可以通过核函数转成线性可分常用的核函数主要有线性核函数(Linear Kernel Function)、多项式核函数(Polynomial Kernel Function)?、高斯(RBF)核函数和sigmoid核函数。在对不同数据集进行使用核函数的时候,需要对数据集的大致特征有所了解。比如特征和数量都比较少的时候首选线性核函数,如果效果不好再换其他核函数;特征数量比较少,样本数量正常的情况下可以选择用高斯核函数,对于每种核函数的选择需要根据数据集来进行选择。支持向量机(SVM)可以利用核函数的方式把数据从低维映射到高维,既可以应用于分类场景,也可以用来做回归问题,其本身又是求解最优化推导而来,不用担心局部最小值问题,所以在金融领域SVM也是有比较广泛的应用的。从总体来看, SVM在金融时序预测、信用风险评估、选择优质股票等问题上应用效果比较好。本文选择一个简单直观的应用实战——根据股价基本 历史数据来预测股市涨跌。通过这个简单的例子,可以比较清晰的感受到传统机器学习在实际股市中的作用,加深对支持向量机算法的理解以及现实。首先对于预测股市(这里以上证指数为例)涨跌这个问题,可以直接看成是一个有监督学习的分类任务,更具体一点说是一个二分类问题。当股市上涨则属于标签1,下降 则是0。主要的任务是根据股市历史数据作为特征来进行训练,并预测接下来的时间里股市的涨跌情况。首先加载股票基本数据,为此选择了从2011-01-01到2021-04-30时间段的数据作为这次应用的数据集。其中数据主要的特征有:
Open?(当天开盘价)High?(当天最高价)
Low?(当天最低价)
Volume?(当天成交的股票数量)
Money?(当天成交的金额)
利用Pandas可以很方便查看数据集的基本结构和属性。
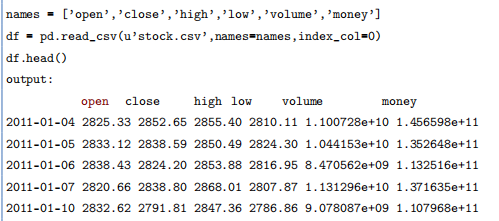
表2.1-1 数据格式
读完数据之后,明显可以看到各个列的数据量级是有差异的,比如开盘价(Open) 和钱的总量(Money)。应用的第一步,需要对数据集进行标准化处理。大致了解数据的结构以及数据具体含义情况之后,对数据进行预处理(Preprocessing)。由于各个特征数据的量级以及分布都无法完全一致,会导致在利用机器学习算法训练的时候预估结果不准,所以需要对数据进行预处理,也可以说归一化处理 (Normalization)。主要目的就是把所有数据统一成一个标准,在不改变数据本身意义的前提下,对数据进行一次“美容”。归一化处理之后的数据可以直接输入到机器学习模型中进行训练。在这里将所有数据初始值设为100来进行归一化, 这样不仅可以方便分析数据,也可以方便做图从而看出走势。

??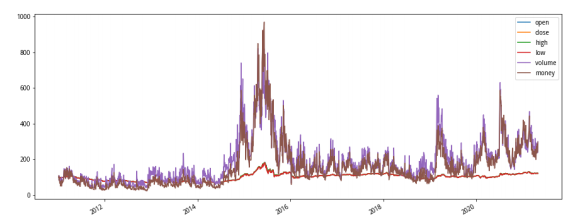 从图中可以看到,股市在2015上半年达到顶峰,然后立马又极速下跌,之后几年都处于震荡状态,最近几年总体趋势是向上的。另一方面,各个指标之间基本走势也是比较相似,其中成交的金额是整体波动比较小的一个指标。接下来,需要再做一个计算前后两天涨跌幅的计算,来代替之前的绝对值数据。并对收盘价涨的标记为正样本,跌的标 记为负样本。这样构造好的数据就可以直接作为机器学习的标准输人数据。
从图中可以看到,股市在2015上半年达到顶峰,然后立马又极速下跌,之后几年都处于震荡状态,最近几年总体趋势是向上的。另一方面,各个指标之间基本走势也是比较相似,其中成交的金额是整体波动比较小的一个指标。接下来,需要再做一个计算前后两天涨跌幅的计算,来代替之前的绝对值数据。并对收盘价涨的标记为正样本,跌的标 记为负样本。这样构造好的数据就可以直接作为机器学习的标准输人数据。
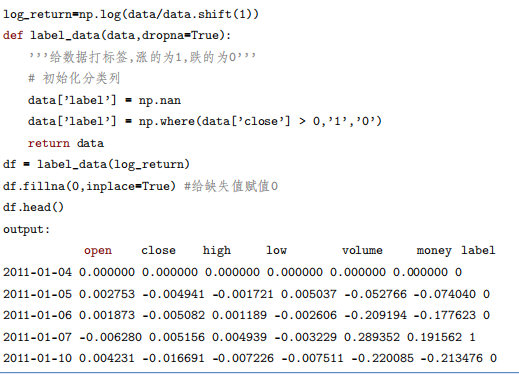
数据全部处理好之后,进行训练数据和测试数据集的分割,这里随机抽取总体数据的30%作为测试集。X_train表示训练集的训练数据,y_train表示训练集的标签,X_test 表示测试集的训练数据,y_test表示测试集的标签。到这里完成了整个流程的第一步。

数据集处理好了之后,第二步,利用现有的机器学习库一一sklearn可以方便地帮助我们直接使用这个算法。一方面SVM算法本身实现的步骤比较多,如果自己手动实现会比较费时间,实际应用中,更多的是直接调用这个包中的方法。

这里的SVC就是指SVM算法的方法函数,直接利用SVC的fit方法把训练数据放进去进行训练,这里的kernel指的是核函数,这里先用最简单的线性核函数进行计算,之后会再对比一下其他核函数的效果。该问题是典型的二分类问题,并且该数据集的正负样本分布还比较均匀,在这里可以采用准确率的指标来对这次模型效果进行判定。


表?2.2-7: rbf核函数SVM模型的核心代码
通过使用两种不同核函数可以看出对于该数据集,采用线性核函数具有更好的效果。回顾:本次实验通过使用不同核函数的svm算法来对股市涨跌进行预测,实验表明:利用线性核的svm效果较好,准确率能达到66.3%。总结:通过本次svm在股票数据中的案例可以看出,一方面,通过对金融数据的获取和处理,利用机器学习的手段的确可以来预估一些比较金融场景下的问题。另一方面,本次实验效果比较一般,主要原因可能是数据的特征还是远远不足以预估A股这样波动比较大的市场,实际的量化交易中会利用很多更有效的特征来进行细化的分析和预估,比如在特征中加人日线的一些数据, 新闻数据的一些特征等。如果想要达到实际应用的效果,需要结合更多的特征,进行更加细化的分析才能预测更加精准。最后还是需要说明一下,股市预测可以预测长期的走势, 但是短期的预测基本是不可能的,预测时间期限越长,预测的难度也越低。END
转自:数据派THU;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/





![aka小腿 今天好想吃火锅(你听到了吗[doge][单身狗]](https://imgs.knowsafe.com:8087/img/aideep/2021/11/27/56ce57d8e3eff6e8d16a1a660d410a2c.jpg?w=250)





 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




