单目标跟踪、多目标跟踪、视频目标分割、多目标跟踪与分割这四个任务,现在一个架构就搞定了。
目标跟踪是计算机视觉中的一项基本任务,旨在建立帧间像素级或实例级对应关系,并输出 box 或掩码(mask)形式的轨迹。根据不同应用场景,目标跟踪主要分为四个独立的子任务:单目标跟踪(SOT)、多目标跟踪(MOT)、视频目标分割 (VOS) 、多目标跟踪与分割 (MOTS) 。大多数目标跟踪方法仅针对其中一个或部分子任务。这种碎片化情况带来以下缺点:(1)跟踪算法过度专注于特定子任务,缺乏泛化能力。(2) 独立模型设计导致参数冗余。那么,是否能用一个统一的模型来解决所有的主流跟踪任务?现在,来自大连理工大学、字节跳动和香港大学的研究者提出了一种统一的方法,称为 Unicorn,它可以使用相同的模型参数通过单个网络同时解决四个跟踪问题(SOT、MOT、VOS、MOTS)。Unicorn 的统一表现在在所有跟踪任务中采用相同的输入、主干、嵌入和头,首次实现了跟踪网络架构和学习范式的统一。Unicorn 在 8 个跟踪数据集(包括 LaSOT、TrackingNet、MOT17、BDD100K、DAVIS16-17、MOTS20 和 BDD100K MOTS)上的表现与特定任务方法的性能相当或更好。Unicorn 将成为迈向通用视觉模型的坚实一步。研究论文已被接收为 ECCV 2022 oral 。- 论文地址:https://arxiv.org/pdf/2207.07078.pdf
- 项目地址:https://github.com/MasterBin-IIAU/Unicorn

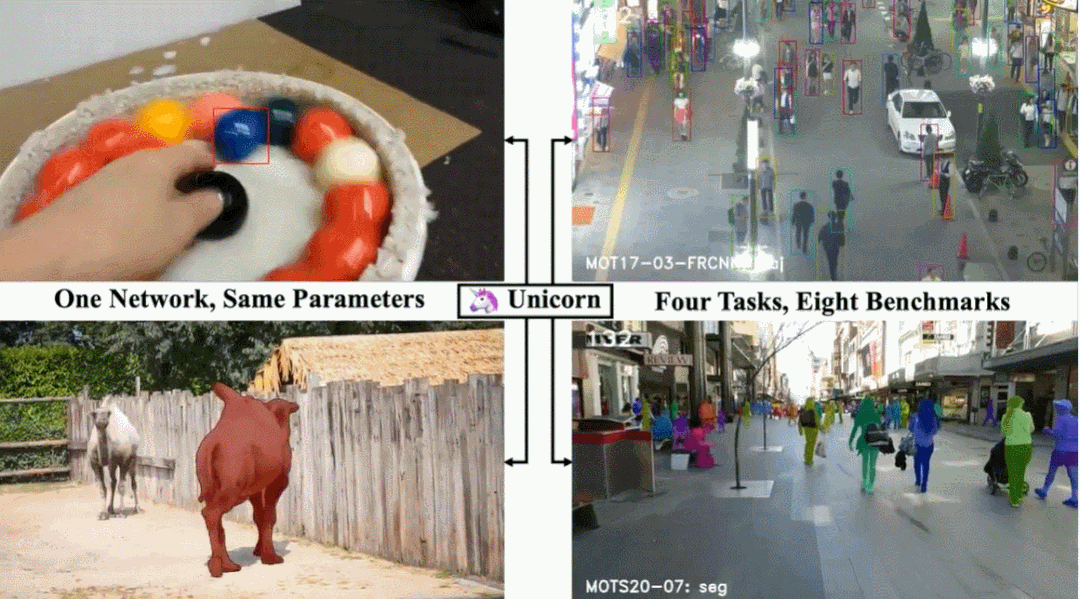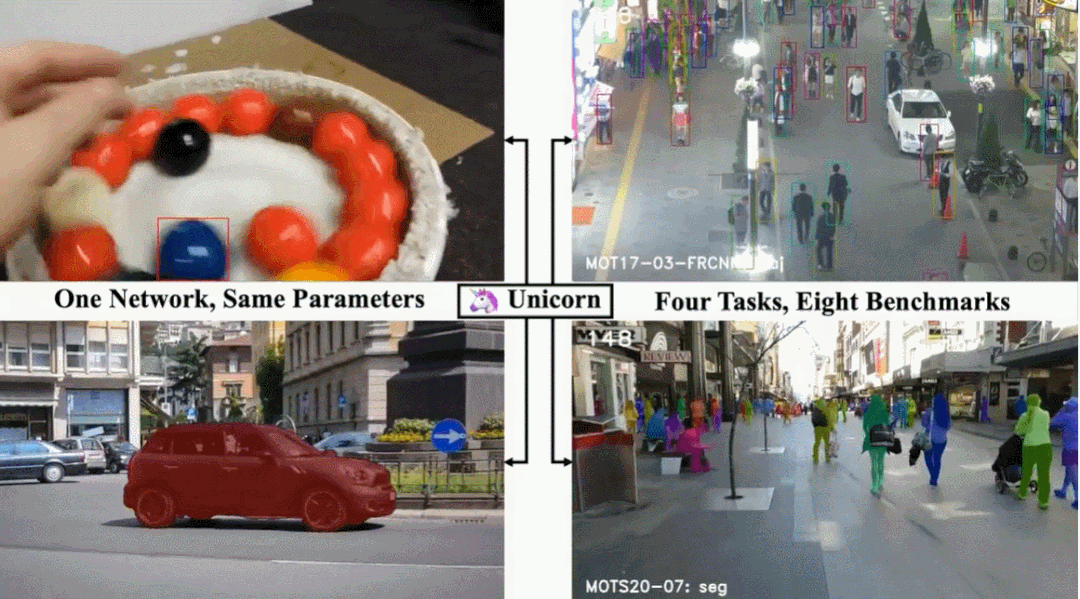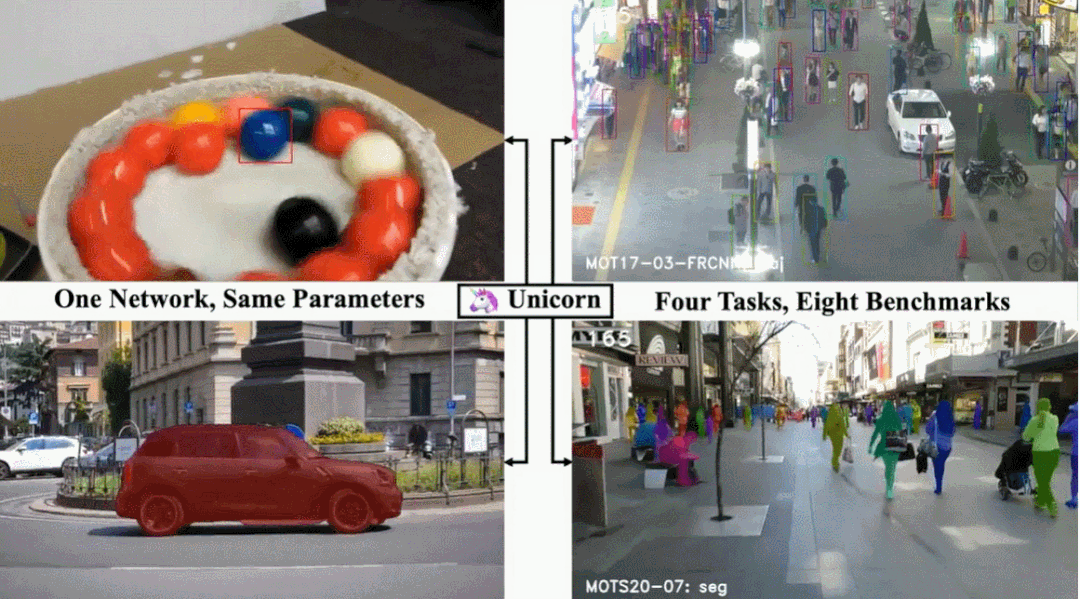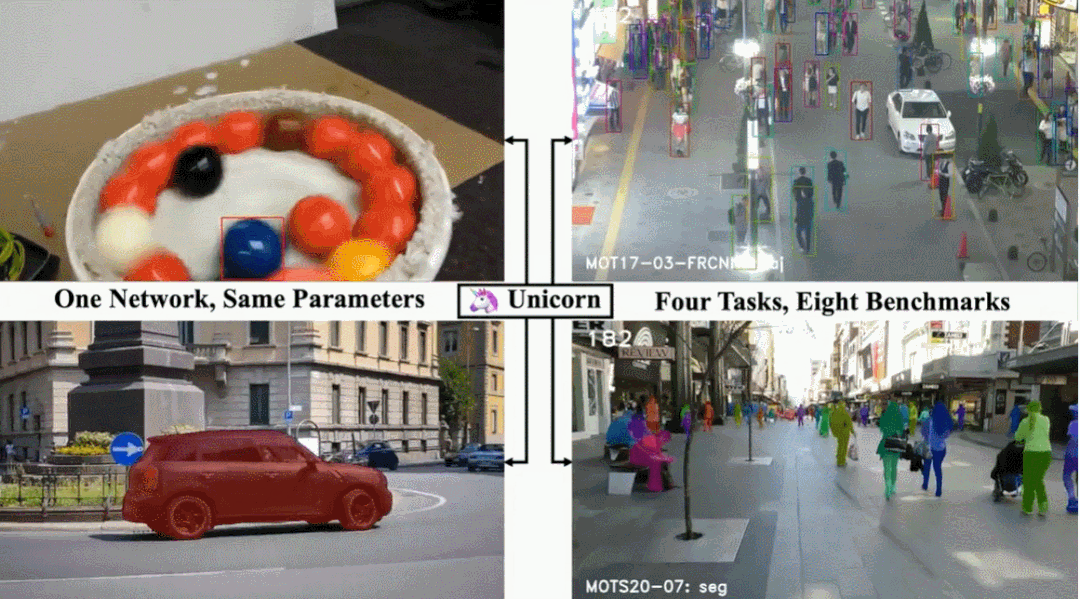
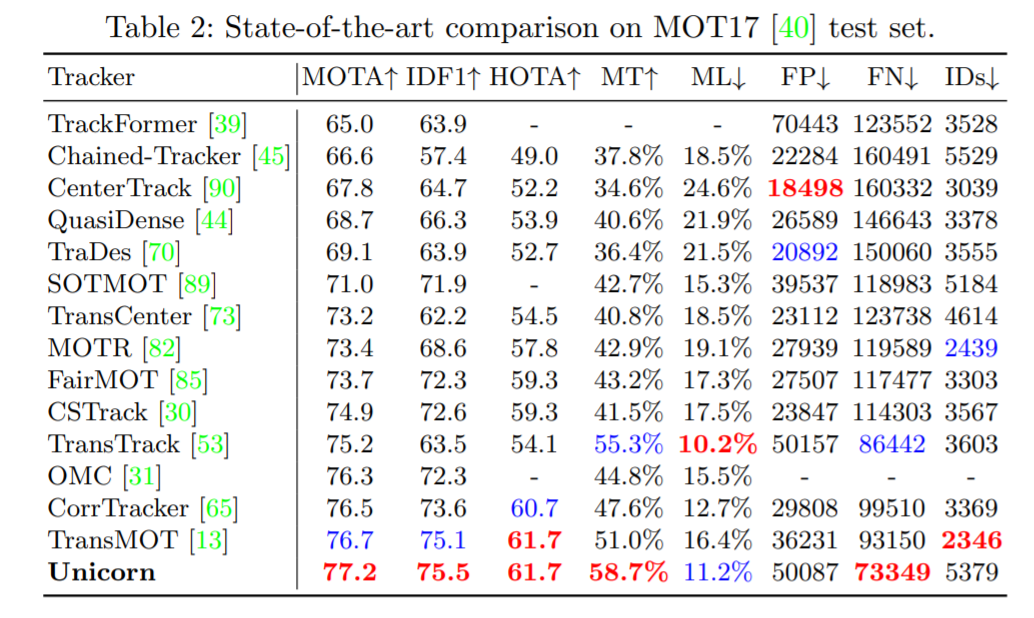
Unicorn 由三个部分组成:统一输入与主干、统一嵌入、统一头。三个组件分别负责获得强大的视觉表征、建立精确的对应关系和检测不同的跟踪目标。Unicorn 的框架如图 2 所示。给定参考帧 I_ref、当前帧 I_cur 和参考目标,Unicorn 旨在通过统一的网络预测当前帧上跟踪目标的状态,以用于四个任务。为了有效地定位多个潜在目标,Unicorn 将整个图像(参考帧和当前帧)而不是局部搜索区域作为输入。在特征提取过程中,参考帧和当前帧通过权重共享主干获得特征金字塔表示(FPN)。为了在计算对应关系时保持重要细节并减少计算负担,本文选择 stride 为 16 的特征图作为之后嵌入模块的输入。参考帧和当前帧的相应特征分别称为 F_ref 和 F_cur。目标跟踪的核心任务是在视频中的帧之间建立准确的对应关系。对于 SOT 和 VOS,逐像素对应将用户提供的目标从参考帧(通常是 1^th 帧)传播到 t^th 帧,为最终的框或掩码预测提供强大的先验信息。此外,对于 MOT 和 MOTS,实例级对应有助于将 t^th 帧上检测到的实例与参考帧(通常是 t-1^th 帧)上的现有轨迹相关联。为了实现目标跟踪的大统一,另一个重要且具有挑战性的问题是为四个跟踪任务设计一个统一头。具体而言,MOT 检测特定类别的目标,SOT 需要检测参考帧中给定的任何目标。为了弥补这一差距,Unicorn 向原始检测器头引入了一个额外的输入(称为目标先验)。无需任何进一步修改,Unicorn 就可以通过这个统一的头轻松检测四项任务所需的各种目标。训练:整个训练过程分为 SOT-MOT 联合训练和 VOS-MOTS 联合训练两个阶段。在第一阶段,使用来自 SOT&MOT 的数据对网络进行端到端优化,包括对应损失和检测损失。在第二阶段,使用来自 VOS&MOTS 的数据在其他参数固定的情况下添加和优化掩码分支,并使用掩码损失进行优化。推理:在测试阶段,对于 SOT&VOS,参考目标图在第一帧生成一次,并在后续帧中保持固定。Unicorn 直接挑选置信度得分最高的框或掩码作为最终的跟踪结果。此外,Unicorn 只需要运行一次主干和对应,是运行轻量级头而不是运行整个网络 N 次,本文方法效率更高。对于 MOT&MOTS,Unicorn 检测给定类别的所有目标并同时输出相应的实例嵌入。之后的关联分别基于 BDD100K 和 MOT17 的嵌入和运行模型执行。LaSOT:LaSOT 是一个大规模的长期跟踪基准,测试集中包含 280 个视频,平均长度为 2448 帧。表 1 显示 Unicorn 实现了新的 SOTA 成功率和精度,分别为 68.5% 和 74.1%。值得注意的是,Unicorn 以更简单的网络架构和跟踪策略,大大超过了之前最好的基于全局检测的跟踪器 Siam R-CNN(68.5% vs 64.8%)。TrackingNet:TrackingNet 是一个大规模的短期跟踪基准,测试集中有 511 个视频。如表 1 所示,Unicorn 以 83.0% 的成功率和 82.2% 的精度超越了所有以前的方法。MOT17 以行人跟踪为重点,训练集有 7 个序列,测试集也有 7 个序列。从表 2 可以看出,Unicorn 实现了最好的 MOTA 和 IDF1,分别比之前的 SOTA 方法高出 0.5% 和 0.4%。BDD100K 是一个大规模的视觉驾驶场景数据集,需要跟踪 8 类实例。如表 3 所示,Unicorn 取得了最佳性能,在验证集上大大超过了之前的 SOTA 方法 QDTrack。具体来说,mMOTA 和 mIDF1 的提升分别高达 4.6% 和 3.2%。DAVIS-16 在验证集中包含 20 个视频,每个序列中只有一个跟踪目标。图 4 表明 Unicorn 在使用边框初始化的方法中取得了最好的结果,甚至超过了使用掩码初始化的 RANet 和 FRTM。
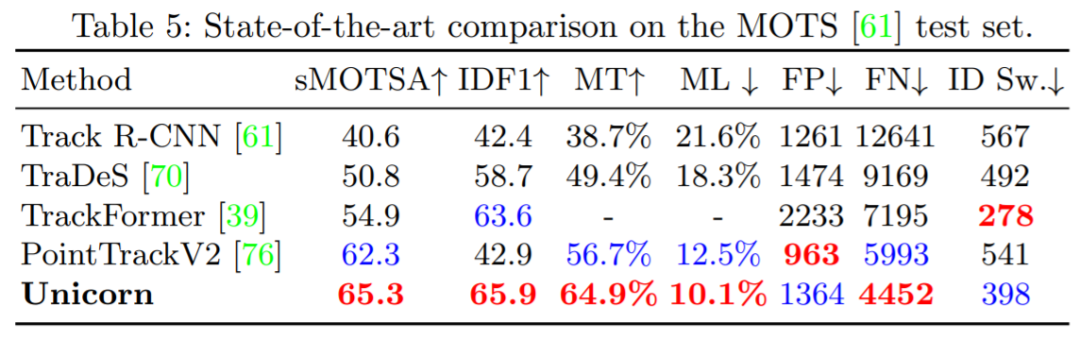
MOTS20 Challenge 在训练集中有 4 个序列,在测试集中有 4 个序列。如表 5 所示,Unicorn 实现了 SOAT 性能,在 sMOTSA 上以 3.3% 的幅度超过了第二好的方法 PoinTrackV2。BDD100K MOTS Challenge 在验证集中包含 37 个序列。图 6 表明 Unicorn 大大优于先前最佳方法 PCAN(即 mMOTSA +2.2%,mAP +5.5%)。同时,Unicorn 没有像 PCAN 那样使用时空存储器或原型网络等复杂设计,引入了更简单的 pipeline。

??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/












 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




