
通过 Java 来学习 Apache Beam

在本文中,我们将介绍 Apache Beam,这是一个强大的批处理和流式处理开源项目,eBay 等大公司用它来集成流式处理管道,Mozilla 用它来在系统之间安全地移动数据。
Apache Beam 是一种处理数据的编程模型,支持批处理和流式处理。
你可以使用它提供的 Java、Python 和 Go SDK 开发管道,然后选择运行管道的后端。

Beam 的编程模型
内置的 IO 连接器
Apache Beam 连接器可用于从几种类型的存储中轻松提取和加载数据。
主要连接器类型有:
基于文件的(例如 Apache Parquet、Apache Thrift);
文件系统(例如 Hadoop、谷歌云存储、Amazon S3);
消息传递(例如 Apache Kafka、Google Pub/Sub、Amazon SQS);
数据库(例如 Apache Cassandra、Elastic Search、MongoDB)。
作为一个 OSS 项目,对新连接器的支持在不断增长(例如 InfluxDB、Neo4J)。
可移植性:
Beam 提供了几个运行管道的 Runner,你可以根据自己的场景选择最合适的,并避免供应商锁定。
分布式处理后端,如 Apache Flink、Apache Spark 或 Google Cloud Dataflow 可以作为 Runner。
分布式并行处理:
默认情况下,数据集的每一项都是独立处理的,因此可以通过并行运行实现优化。
开发人员不需要手动分配负载,因为 Beam 为它提供了一个抽象。
Beam 编程模型的关键概念:
PCollection:表示数据的集合,如从文本中提取的数字或单词数组。
PTransform:一个转换函数,接收并返回一个 PCollection,例如所有数字的和。
管道:管理 PTransform 和 PCollection 之间的交互。
PipelineRunner:指定管道应该在哪里以及如何执行。
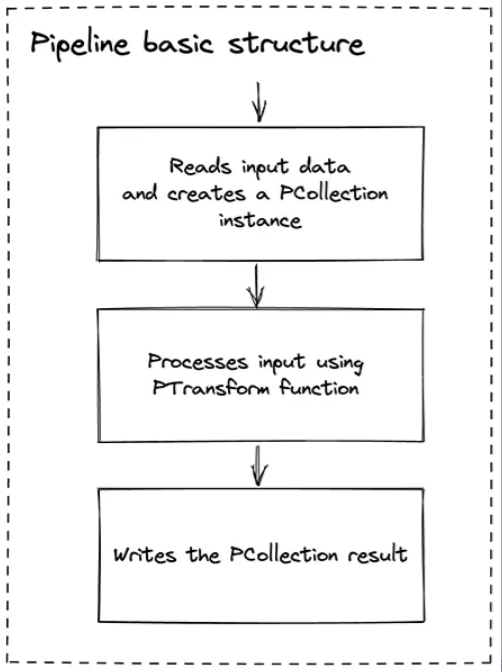
一个基本的管道操作包括 3 个步骤:读取、处理和写入转换结果。这里的每一个步骤都是用 Beam 提供的 SDK 进行编程式定义的。
在本节中,我们将使用 Java SDK 创建管道。你可以创建一个本地应用程序(使用 Gradle 或 Maven 构建),也可以使用在线沙盒。示例将使用本地 Runner,因为这样使用 JUnit 断言验证结果会更容易些。
beam-sdk-java-core:包含所有的 Beam 模型类。
beam-runners-direct-java:默认情况下 Beam SDK 将直接使用本地 Runner,也就是说管道将在本地机器上运行。
在第一个例子中,管道将接收到一个数字数组,并将每个元素乘以 2。
第一步是创建管道实例,它将接收输入数组并执行转换函数。因为我们使用 JUnit 运行 Beam,所以可以很容易地创建 TestPipeline 并将其作为测试类的一个字段。如果你更喜欢通过 main 方法来运行,需要设置管道配置参数。
@Rulepublic final transient TestPipeline pipeline = TestPipeline.create();
现在,我们可以创建作为管道输入的 PCollection。它是一个直接在内存中实例化的数组,但它也可以从支持 Beam 的任何地方读取。
PCollection<Integer> numbers =pipeline.apply(Create.of(1, 2, 3, 4, 5));
然后我们应用我们的转换函数,将每个元素乘以 2。
PCollection<Integer> output = numbers.apply(MapElements.into(TypeDescriptors.integers()).via((Integer number) -> number * 2));
为了验证结果,我们可以写一个断言。
PAssert.that(output).containsInAnyOrder(2, 4, 6, 8, 10);
注意,结果不排序,因为 Beam 将每一个元素作为独立的项进行并行处理。
测试到这里就完成了,我们通过调用下面的方法运行管道:
pipeline.run();
Reduce 操作将多个输入元素进行聚合,产生一个较小的集合,通常只包含一个元素。
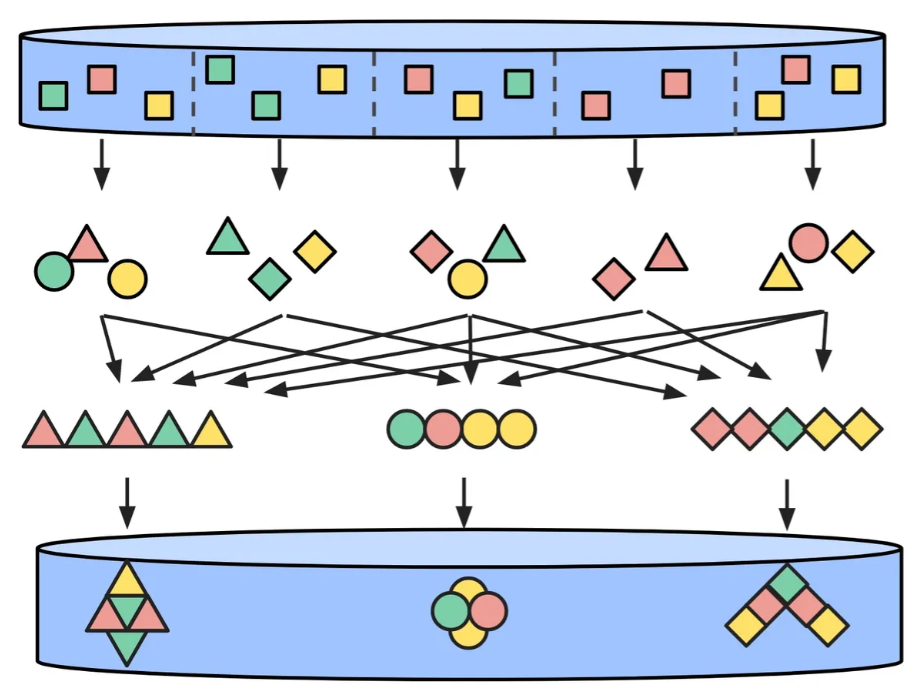
MapReduce
现在我们来扩展上面的示例,将所有项乘以 2 后求和,产生一个 MapReduce 转换操作。
每一个 PCollection 转换都会产生一个新的 PCollection 实例,这意味着我们可以使用 apply 方法将转换链接起来。对于这个示例,将在每个元素乘以 2 后使用 Sum 操作:
PCollection<Integer> numbers =pipeline.apply(Create.of(1, 2, 3, 4, 5));PCollection<Integer> output = numbers.apply(MapElements.into(TypeDescriptors.integers()).via((Integer number) -> number * 2)).apply(Sum.integersGlobally());PAssert.that(output).containsInAnyOrder(30);pipeline.run();
FlatMap 先对每个输入元素应用映射,返回一个新集合,从而产生一个集合的集合。然后再应用 Flat 操作将所有嵌套的集合合并,最终生成一个集合。
下一个示例将把字符串数组转换成包含唯一性单词的数组。
首先,我们声明将作为管道输入的单词列表:
final String[] WORDS_ARRAY = new String[] {"hi bob", "hello alice", "hi sue"};final List<String> WORDS = Arrays.asList(WORDS_ARRAY);
然后,我们使用上面的列表创建输入 PCollection:
PCollection<String> input = pipeline.apply(Create.of(WORDS));
现在,我们进行 FlatMap 转换,它将拆分每个嵌套数组中的单词,并将结果合并成一个列表:
PCollection<String> output = input.apply(FlatMapElements.into(TypeDescriptors.strings()).via((String line) -> Arrays.asList(line.split(" "))));PAssert.that(output).containsInAnyOrder("hi", "bob", "hello", "alice", "hi", "sue");pipeline.run();
数据处理的一个常见的任务是根据特定的键进行聚合或计数。我们将计算上一个例子中每个单词出现的次数。
在有了扁平的字符串数组之后,我们可以链接另一个 PTransform:
PCollection<KV<String, Long>> output = input.apply(FlatMapElements.into(TypeDescriptors.strings()).via((String line) -> Arrays.asList(line.split(" ")))).apply(Count.<String>perElement());
PAssert.that(output).containsInAnyOrder(KV.of("hi", 2L),KV.of("hello", 1L),KV.of("alice", 1L),KV.of("sue", 1L),KV.of("bob", 1L));
Beam 的一个原则是可以从任何地方读取数据,所以我们来看看在实际当中如何使用文本文件作为数据源。
下面的示例将读取包含“An advanced unified programming model”文本的文件“words.txt”。然后转换函数将返回一个包含每一个单词的 PCollection。
PCollection<String> input =pipeline.apply(TextIO.read().from("./src/main/resources/words.txt"));PCollection<String> output = input.apply(FlatMapElements.into(TypeDescriptors.strings()).via((String line) -> Arrays.asList(line.split(" "))));PAssert.that(output).containsInAnyOrder("An", "advanced", "unified", "programming", "model");pipeline.run();
从前面的输入示例可以看到,Beam 提供了多个内置的输出连接器。在下面的例子中,我们将计算文本文件“words.txt”(只包含一个句子“An advanced unified programming model")中出现的每个单词的数量,输出结果将写入一个文本文件。
PCollection<String> input =pipeline.apply(TextIO.read().from("./src/main/resources/words.txt"));PCollection<KV<String, Long>> output = input.apply(FlatMapElements.into(TypeDescriptors.strings()).via((String line) -> Arrays.asList(line.split(" ")))).apply(Count.<String>perElement());;PAssert.that(output).containsInAnyOrder(KV.of("An", 1L),KV.of("advanced", 1L),KV.of("unified", 1L),KV.of("programming", 1L),KV.of("model", 1L));output.apply(MapElements.into(TypeDescriptors.strings()).via((KV<String, Long> kv) -> kv.getKey() + " " + kv.getValue())).apply(TextIO.write().to("./src/main/resources/wordscount"));pipeline.run();
默认情况下,文件写入也针对并行性进行了优化,这意味着 Beam 将决定保存结果的最佳分片(文件)数量。这些文件位于 src/main/resources 文件夹中,文件名包含了前缀“wordcount”、碎片序号和碎片总数。
在我的笔记本电脑上运行它生成了 4 个分片:
第一个分片(文件名:wordscount-00001-of-00003):
An 1advanced 1
第二个分片(文件名:wordscount-00002-of-00003):
unified 1model 1
第三个分片(文件名:wordscount-00003-of-00003):
programming 1
最后一个分片是空的,因为所有的单词都已经被处理完了。
我们可以通过编写自定义转换函数来扩展 Beam。自定义转换器将提高代码的可维护性,并消除重复工作。
基本上,我们需要创建一个 PTransform 的子类,将输入和输出的类型声明为 Java 泛型。然后重写 expand 方法,加入我们的逻辑,它将接受单个字符串并返回包含每个单词的 PCollection。
public class WordsFileParser extends PTransform<PCollection<String>, PCollection<String>> {@Overridepublic PCollection<String> expand(PCollection<String> input) {return input.apply(FlatMapElements.into(TypeDescriptors.strings()).via((String line) -> Arrays.asList(line.split(" "))));}}
用 WordsFileParser 来重构测试场景就变成了:
public class FileIOTest {@Rulepublic final transient TestPipeline pipeline = TestPipeline.create();@Testpublic void testReadInputFromFile() {PCollection<String> input =pipeline.apply(TextIO.read().from("./src/main/resources/words.txt"));PCollection<String> output = input.apply(new WordsFileParser());PAssert.that(output).containsInAnyOrder("An", "advanced", "unified", "programming", "model");pipeline.run();}@Testpublic void testWriteOutputToFile() {PCollection<String> input =pipeline.apply(TextIO.read().from("./src/main/resources/words.txt"));PCollection<KV<String, Long>> output = input.apply(new WordsFileParser()).apply(Count.<String>perElement());PAssert.that(output).containsInAnyOrder(KV.of("An", 1L),KV.of("advanced", 1L),KV.of("unified", 1L),KV.of("programming", 1L),KV.of("model", 1L));output.apply(MapElements.into(TypeDescriptors.strings()).via((KV<String, Long> kv) -> kv.getKey() + " " + kv.getValue())).apply(TextIO.write().to ("./src/main/resources/wordscount"));pipeline.run();}}
结果变成了更清晰和更模块化的管道。
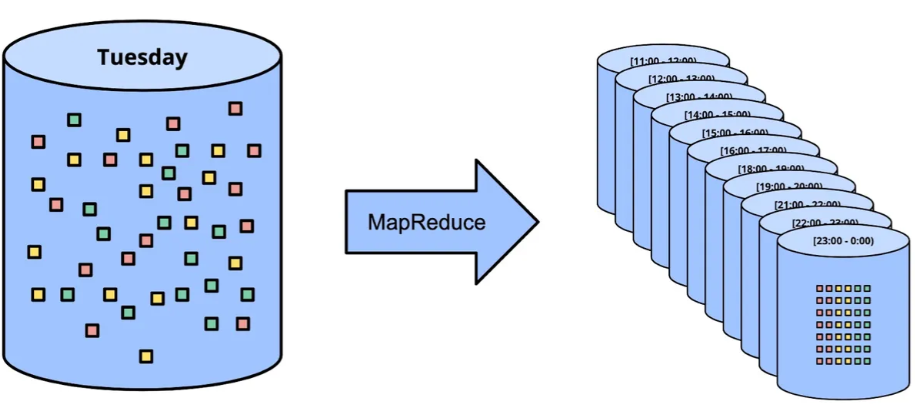
Beam 的时间窗口
流式处理中一个常见的问题是将传入的数据按照一定的时间间隔进行分组,特别是在处理大量数据时。在这种情况下,分析每小时或每天的聚合数据比分析数据集的每个元素更有用。
在下面的例子中,我们将假设我们身处金融科技领域,我们正在接收包含金额和交易时间的事件,我们希望获取每天的交易总额。
Beam 提供了一种用时间戳来装饰每个 PCollection 元素的方法。我们可以通过这种方式创建一个代表 5 笔交易的 PCollection:
金额 10 和 20 是在 2022 年 02 月 01 日转账的;
金额 30、40 和 50 是在 2022 年 02 月 05 日转账的。
PCollection<Integer> transactions =pipeline.apply(Create.timestamped(TimestampedValue.of(10, Instant.parse("2022-02-01T00:00:00+00:00")),TimestampedValue.of(20, Instant.parse("2022-02-01T00:00:00+00:00")),TimestampedValue.of(30, Instant.parse("2022-02-05T00:00:00+00:00")),TimestampedValue.of(40, Instant.parse("2022-02-05T00:00:00+00:00")),TimestampedValue.of(50, Instant.parse("2022-02-05T00:00:00+00:00"))));
接下来,我们将应用两个转换函数:
使用一天的时间窗口对交易进行分组;
把每组的数量加起来。
PCollection<Integer> output =Transactions.apply(Window.into(FixedWindows.of(Duration.standardDays(1)))).apply(Combine.globally(Sum.ofIntegers()).withoutDefaults());
在第一个时间窗口(2022-02-01)中,预计总金额为 30(10+20),而在第二个窗口(2022-02-05)中,我们应该看到总金额为 120(30+40+50)。
PAssert.that(output).inWindow(new IntervalWindow(Instant.parse("2022-02-01T00:00:00+00:00"),Instant.parse("2022-02-02T00:00:00+00:00"))).containsInAnyOrder(30);PAssert.that(output).inWindow(new IntervalWindow(Instant.parse("2022-02-05T00:00:00+00:00"),Instant.parse("2022-02-06T00:00:00+00:00"))).containsInAnyOrder(120);
每个 IntervalWindow 实例需要匹配所选时间段的确切开始和结束时间戳,因此所选时间必须是“00:00:00”。
Beam 是一个强大的经过实战检验的数据框架,支持批处理和流式处理。我们使用 Java SDK 进行了 Map、Reduce、Group 和时间窗口等操作。
Beam 非常适合那些执行并行任务的开发人员,可以简化大规模数据处理的机制。
它的连接器、SDK 和对各种 Runner 的支持为我们带来了灵活性,你只要选择一个原生 Runner,如 Google Cloud Dataflow,就可以实现计算资源的自动化管理。
作者简介:
Fabio Hiroki 是一位在 Mollie 公司从事金融服务的软件工程师。
原文链接:
https://www.infoq.com/articles/apache-beam-intro/
点击底部?阅读原文?访问 InfoQ 官网,获取更多精彩内容!

点个在看少个 bug? 关注公众号:拾黑(shiheibook)了解更多 [广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 InfoQ
InfoQ
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675