
收藏! 38个Python数据科学顶级库
这篇文章中包括的类别,我们认为这些类别考虑了通用的数据科学库,即那些可能被数据科学领域的从业人员用于广义的,非神经网络的,非研究性工作的库:
数据-用于数据管理,处理和其他处理的库 数学-虽然许多库都执行数学任务,但这个小型库却专门这样做 机器学习-自我解释;不包括主要用于构建神经网络或用于自动化机器学习过程的库 自动化机器学习-主要用于自动执行与机器学习相关的过程的库 数据可视化-与建模,预处理等相反,主要提供与数据可视化相关的功能的库。 解释与探索-主要用于探索和解释模型或数据的库
请注意,以下按类型表示了每个库,并按星级和贡献者对其进行了绘制,其符号大小反映了该库在Github上的相对提交次数。
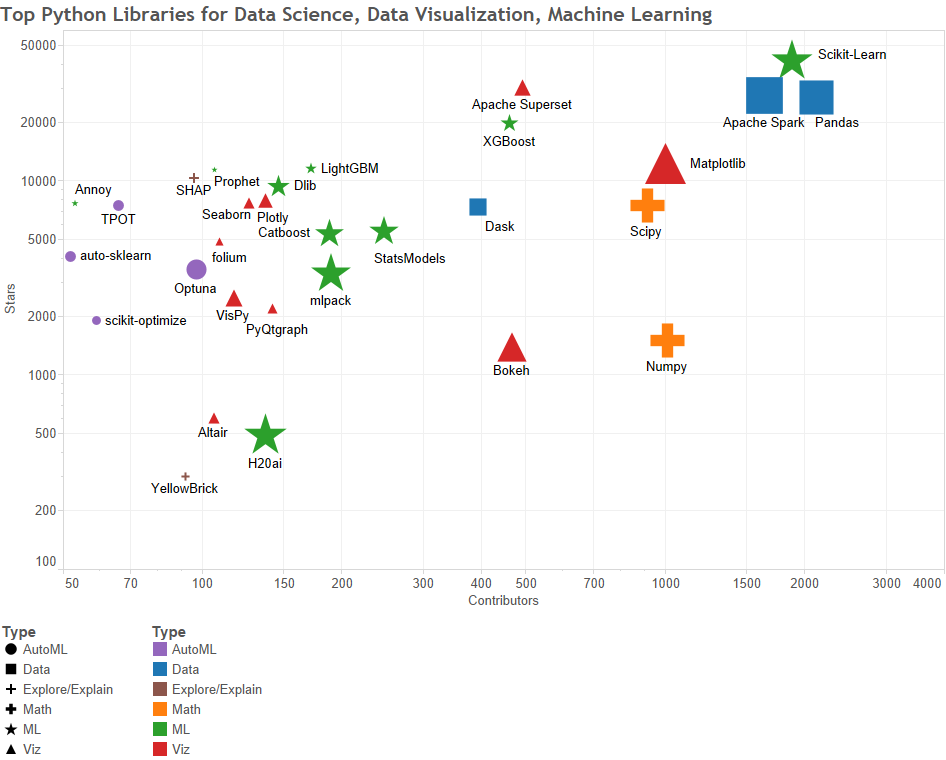
图1:用于数据科学,数据可视化和机器学习的顶级Python库,按星级和贡献者数绘制;相对大小按贡献者数量
数据
1. Apache Spark
https://github.com/apache/spark
star:27600,贡献:28197,贡献者:1638
Apache Spark-用于大规模数据处理的统一分析引擎
2.Pandas
https://github.com/pandas-dev/pandas
star:26800,贡献:24300,贡献者:2126
Pandas是一个Python软件包,提供了快速,灵活和可表达的数据结构,旨在使使用“关系”或“标记”数据既简单又直观。它旨在成为在Python中进行实用,真实世界数据分析的基本高级构建块。
3.Dask
https://github.com/dask/dask
star:7300,贡献:6149,贡献者:393
任务调度的并行计算
数学
4. Scipy
https://github.com/scipy/scipy
star:7500,贡献:24247,贡献者:914
SciPy发音为“ Sigh Pie”是用于数学,科学和工程的开源软件。它包括用于统计,优化,积分,线性代数,傅立叶变换,信号和图像处理,ODE求解器等的模块。
5. Numpy
https://github.com/numpy/numpy
star:1500,贡献:24266,提供者:1010
使用Python进行科学计算的基本软件包。
机器学习
6. Scikit-Learn
https://github.com/scikit-learn/scikit-learn
star:42500,贡献:26162,贡献者:1881
Scikit-learn是一个基于SciPy的Python机器学习模块,并以3条款BSD许可分发。
7. XGBoost
https://github.com/dmlc/xgboost
star:19900,贡献:5015,贡献者:461
适用于Python,R,Java,Scala,C ++等的可扩展,便携式和分布式梯度增强GBDT,GBRT或GBM库。在单机,Hadoop,Spark,Flink和DataFlow上运行
8. LightGBM
https://github.com/microsoft/LightGBM
star:11600,贡献:2066,贡献者:172
基于决策树算法的快速,分布式,高性能梯度提升GBT,GBDT,GBRT,GBM或MART框架,用于排名,分类和许多其他机器学习任务。
9.Catboost
https://github.com/catboost/catboost
star:5400,贡献:12936,贡献者:188
快速,可扩展,高性能的“决策树上的梯度提升”库,用于对Python,R,Java,C ++进行排名,分类,回归和其他机器学习任务。支持在CPU和GPU上进行计算。
10. Dlib
https://github.com/davisking/dlib
star:9500,贡献:7868,贡献者:146
Dlib是一个现代的C ++工具箱,其中包含机器学习算法和工具,这些工具和工具可以用C ++创建复杂的软件来解决实际问题。可以通过dlib API与Python一起使用
11.Annoy
https://github.com/spotify/annoy
star:7700,贡献:778,贡献者:53
C ++ / Python中的近似最近邻居已针对内存使用情况以及加载/保存到磁盘进行了优化
12.H20ai
https://github.com/h2oai/h2o-3
star:500,贡献贡献:27894,贡献者:137
适用于更智能应用的开源快速可扩展机器学习平台:深度学习,梯度提升和XGBoost,随机森林,广义线性建模逻辑回归,弹性网,K均值,PCA,堆叠集成,自动机器学习AutoML等。
13. StatsModels
https://github.com/statsmodels/statsmodels star:5600,承诺:13446,贡献者:247
Statsmodels:Python中的统计建模和计量经济学
14. mlpack
https://github.com/mlpack/mlpack
star:3400,贡献:24575,贡献者:190
mlpack是一个直观,快速且灵活的C ++机器学习库,具有与其他语言的绑定
15.Pattern
https://github.com/clips/pattern
star:7600,贡献:1434,贡献者:20
用于Python的Web挖掘模块,具有用于抓取,自然语言处理,机器学习,网络分析和可视化的工具。
16.Prophet
https://github.com/facebook/prophet
star:11500,贡献:595,贡献者:106
用于为具有多个季节性且线性或非线性增长的时间序列数据生成高质量预测的工具。
自动化机器学习
17. TPOT
https://github.com/EpistasisLab/tpot
star:7500,贡献:2282,贡献者:66
一个Python自动化机器学习工具,可使用遗传编程来优化机器学习pipeline。
18. auto-sklearnhttps://github.com/automl/auto-sklearn
star:4100,贡献:2343,贡献者:52
auto-sklearn是一种自动化的机器学习工具包,是scikit-learn估计器的直接替代品。
19. Hyperopt-sklearn
https://github.com/hyperopt/hyperopt-sklearn
star:1100,贡献:188,贡献者:18
Hyperopt-sklearn是scikit-learn中机器学习算法中基于Hyperopt的模型选择。
20. SMAC-3
https://github.com/automl/SMAC3
star:529,贡献:1882,贡献者:29
基于顺序模型的算法配置
21. scikit-optimizehttps://github.com/scikit-optimize/scikit-optimize
star:1900,贡献:1540,贡献者:59
Scikit-Optimize或skopt是一个简单高效的库,可最大限度地减少非常昂贵且嘈杂的黑盒功能。它实现了几种基于顺序模型优化的方法。
22. Nevergrad
https://github.com/facebookresearch/nevergrad
star:2700,贡献:663,贡献者:38
用于执行无梯度优化的Python工具箱
23.Optuna
https://github.com/optuna/optuna
star:3500,贡献:7749,贡献者:97
Optuna是一个自动超参数优化软件框架,专门为机器学习而设计。
数据可视化
24. Apache Superset
https://github.com/apache/incubator-superset
star:30300,贡献:5833,贡献者:492
Apache Superset是一个数据可视化和数据探索平台
25. Matplotlib
https://github.com/matplotlib/matplotlib
star:12300,贡献:36716,贡献者:1002
Matplotlib是一个综合库,用于在Python中创建静态,动画和交互式可视化。
26.Plotly
https://github.com/plotly/plotly.py
star:7900,贡献:4604,贡献者:137
Plotly.py是适用于Python的交互式,基于开源和基于浏览器的图形库
27. Seaborn
https://github.com/mwaskom/seaborn
star:7700,贡献:2702,贡献者:126
Seaborn是基于matplotlib的Python可视化库。它提供了用于绘制吸引人的统计图形的高级界面。
28.folium
https://github.com/python-visualization/folium
star:4900,贡献:1443,贡献者:109
Folium建立在Python生态系统的数据处理能力和Leaflet.js库的映射能力之上。用Python处理数据,然后通过folium在可视化的Leaflet贴图中显示。
29. Bqplot
https://github.com/bqplot/bqplot
star:2900,贡献:3178,贡献者:45
Bqplot是Jupyter的二维可视化系统,基于图形语法的构造。
30. VisPy
https://github.com/vispy/vispy
star:2500,贡献:6352,贡献者:117
VisPy是一个高性能的交互式2D / 3D数据可视化库。VisPy通过OpenGL库利用现代图形处理单元GPU的计算能力来显示非常大的数据集。
31. PyQtgraph
https://github.com/pyqtgraph/pyqtgraph
star:2200,贡献:2200,贡献者:142
用于科学/工程应用的快速数据可视化和GUI工具
32.Bokeh
https://github.com/bokeh/bokeh
star:1400,贡献:18726,贡献者:467
Bokeh是用于现代Web浏览器的交互式可视化库。它提供通用图形的优雅,简洁的构造,并在大型或流数据集上提供高性能的交互性。
33.Altair
https://github.com/altair-viz/altair
star:600,贡献:3031,贡献者:106
Altair是用于Python的声明性统计可视化库。使用Altair,您可以花费更多时间来理解数据及其含义。
解释与探索
34. eli5https://github.com/TeamHG-Memex/eli5
star:2200,贡献贡献:1198,贡献者:15
一个用于调试/检查机器学习分类器并解释其预测的库
35. LIMEh
ttps://github.com/marcotcr/lime star:800,承诺:501,贡献者:41
Lime:解释任何机器学习分类器的预测
36. SHAP
https://github.com/slundberg/shap
star:10400,贡献:1376,贡献者:96
一种博弈论方法,用于解释任何机器学习模型的输出。
37. YellowBrick
https://github.com/DistrictDataLabs/yellowbrick
star:300,贡献:825,贡献者:92
可视化分析和诊断工具,有助于机器学习模型的选择。
38.pandas-profiling
https://github.com/pandas-profiling/pandas-profiling
star:6200名,贡献:704名,贡献者:47名
从pandas DataFrame对象创建HTML分析报告
作者:Python在线社区;
「完」

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675