
AAAI 2022 | 传统GAN修改后可解释,并保证卷积核可解释性和生成图像真实性
机器之心编辑部
本文介绍了中科院计算所、上海交通大学等机构在 AAAI 2022 上发表的关于可解释生成对抗网络(GAN)的工作。该工作提出了一种将传统 GAN 修改为可解释 GAN 的通用方法,使得 GAN 生成器中间层的卷积核可以学习到解耦的局部视觉概念(例如人脸的眼睛、鼻子和嘴巴等部分)。每个卷积核在生成不同图像时可以稳定地生成对应于相同视觉概念的图像区域。可解释 GAN 使得人们可以通过操纵层中相应卷积核的特征图来修改生成图像上的特定视觉概念,为 GAN 生成图像的可控编辑方法提供了一个新的角度。

论文地址:https://www.aaai.org/AAAI22Papers/AAAI-7931.LiC.pdf 作者单位:中国科学院计算技术研究所、上海交通大学、之江实验室


卷积核的可解释性:研究者希望中间层的卷积核能够自动学习有意义的视觉概念,而无需对任何视觉概念进行人工标注。具体来说,每个卷积核在生成不同图像时都应该稳定地生成对应于相同视觉概念的图像区域。不同的卷积核则应该生成对应于不同视觉概念的图像区域; 生成图像的真实性:可解释 GAN 的生成器仍然能够生成逼真的图像。
传统 GAN 的损失:该损失用于确保生成图像的真实性; 卷积核划分损失:给定生成器,该损失用于找到卷积核的划分方式,使得同一组中的卷积核生成相似的图像区域。具体地,他们使用高斯混合模型 (GMM) 来学习卷积核的划分方式,以确保每组中卷积核的特征图具有相似的神经激活; 能量模型真实性损失:给定目标层卷积核的划分方式,强制同一组中的每个卷积核生成相同的视觉概念可能会降低生成图像的质量。为了进一步确保生成图像的真实性,他们使用能量模型来输出目标层中特征图的真实性概率,并采用极大似然估计来学习能量模型的参数; 卷积核可解释性损失:给定目标层的卷积核划分方式,该损失用于进一步提升卷积核的可解释性。具体地,该损失会使得同一组中的每个卷积核唯一地生成相同的图像区域,而不同组的卷积核则分别负责生成不同的图像区域。





[1] Zhu, Jun-Yan, et al. "Unpaired image-to-image translation using cycle-consistent adversarial networks." Proceedings of the IEEE international conference on computer vision. 2017.
[2] Plumerault, Antoine, Hervé Le Borgne, and Céline Hudelot. "Controlling generative models with continuous factors of variations." International Conference on Learning Representations. 2019.
[3] Shen, Yujun, et al. "Interpreting the latent space of gans for semantic face editing." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[4] Chen, Renwang, et al. "Simswap: An efficient framework for high fidelity face swapping." Proceedings of the 28th ACM International Conference on Multimedia. 2020.
[5] Li, Lingzhi, et al. "Advancing high fidelity identity swapping for forgery detection." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[6] Nirkin, Yuval, Yosi Keller, and Tal Hassner. "Fsgan: Subject agnostic face swapping and reenactment." Proceedings of the IEEE/CVF international conference on computer vision. 2019.
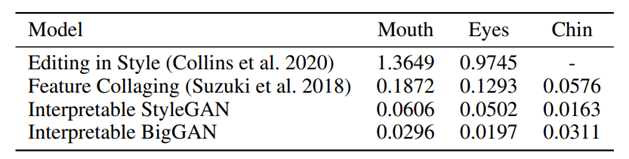
[7] Collins, Edo, et al. "Editing in style: Uncovering the local semantics of gans." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[8] Suzuki, Ryohei, et al. "Spatially controllable image synthesis with internal representation collaging." arXiv preprint arXiv:1811.10153 (2018).

??THE END?
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675