
做了个色情图片识别系统
项目介绍
本项目将使用python3去识别图片是否为色情图片,会使用到PIL这个图像处理库,并且编写算法来划分图像的皮肤区域
介绍一下PIL:
PIL(Python Image Library)是一种免费的图像处理工具包,这个软件包提供了基本的图像处理功能,如:改变图像大小,旋转图像,图像格式转化,色场空间转换(这个我不太懂),图像增强(就是改善清晰度,突出图像有用信息),直方图处理,插值(利用已知邻近像素点的灰度值来产生未知像素点的灰度值)和滤波等等。虽然这个软件包要实现复杂的图像处理算法并不太适合,但是python的快速开发能力以及面向对象等等诸多特点使得它非常适合用来进行原型开发。
在 PIL 中,任何一副图像都是用一个 Image 对象表示,而这个类由和它同名的模块导出,因此,要加载一副图像,最简单的形式是这样的:
import?Image
img?=?Image.open(“dip.jpg”)
注意:==第一行的 Image 是模块名;第二行的 img 是一个 Image 对象;== Image 类是在 Image 模块中定义的。关于 Image 模块和 Image 类,切记不要混淆了。现在,我们就可以对 img 进行各种操作了,所有对 img 的 操作最终都会反映到到 dip.img 图像上
环境准备
PIL 2009 年之后就没有更新了,也不支持 Python3 ,于是有了 Alex Clark 领导的公益项目 Pillow 。Pillow 是一个对 PIL 友好的分支,支持 Python3,所以我们这里安装的是 Pillow,这是它的官方文档。
默认已经有python3.0以上和包管理工具pip3。那要执行如下命令升级pip3并安装Pillow 工具包:
sudo?install?-U?pip3
sudo?install?Pillow
程序原理
根据颜色(肤色)找出图片中皮肤的区域,然后通过一些条件判断是否为色情图片。
程序的关键步骤如下:
遍历每个像素,检查像素颜色是否为肤色 将相邻的肤色像素归为一个皮肤区域,得到若干个皮肤区域 剔除像素数量极少的皮肤区域
我们定义非色情图片的判定规则如下(满足任意一个判断为真):
皮肤区域的个数小于3个 皮肤区域的像素与图像所有像素的比值小于15% 最大皮肤区域小于总皮肤面积的45% 皮肤区域数量超过60个
这些规则你可以尝试更改,直到程序效果让自己满意为止。关于像素肤色判定这方面,公式可以在网上找到很多,但是世界上不可能有正确率100%的公式。你可以用自己找到的公式,在程序完成后慢慢调试。
RGB颜色模式
第一种:==r > 95 and g > 40 and g < 100 and b > 20 and max([r, g, b]) - min([r, g, b]) > 15 and abs(r - g) > 15 and r > g and r > b==
第二种:==nr = r / (r + g + b), ng = g / (r + g + b), nb = b / (r +g + b)
?,nr / ng > 1.185 and r * b / (r + g + b) ** 2 > 0.107 and r * g / (r + g + b) ** 2 > 0.112==HSV颜色模式
==h > 0 and h < 35 and s > 0.23 and s < 0.68==
YCbCr颜色模式
==97.5 <= cb <= 142.5 and 134 <= cr <= 176==
一幅图像有零个到多个的皮肤区域,程序按发现顺序给它们编号,第一个发现的区域编号为0,第n个发现的区域编号为n-1
用一种类型来表示像素,我们给这个类型取名为Skin,包含了像素的一些信息:唯一的编号id、是/否肤色skin、皮肤区域号region、横坐标x、纵坐标y
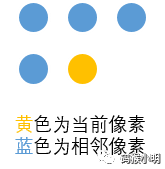
遍历所有像素时,我们为每个像素创建一个与之对应的Skin对象,并设置对象的所有属性,其中region属性即为像素所在的皮肤区域编号,创建对象时初始化为无意义的None。关于每个像素的id值,左上角为原点,像素id值按照像素坐标排布,那么看起来如下图:

其实id的顺序也即遍历的顺序。遍历所有像素时,创建Skin对象后,如果当前像素为肤色,且相邻的像素有肤色的,那么我们把这些肤色像素归到一个皮肤区域。
相邻像素的定义:通常都能想到是当前像素周围的8个像素,然而实际上只需要定义4个就可以了,位置分别在当前像素的左方,左上方,正上方,右上方。因为另外四个像素都在当前像素后面,我们还未给这4个像素创建对应的Skin对象:
实现脚本
直接在python中新建nude.py文件,在这个文件进行代码编写:
导入所需要的模块:
import?sys
import?os
import?_io
from?collections?import?namedtuple
from?PIL?import?Image
我们将设计一个Nude类:
class?Nude:
这个类里面我们首先使用?collections.namedtuple()?定义一个 Skin 类型:
Skin?=?namedtuple("Skin",?"id?skin?region?x?y")
collections.namedtuple()?函数实际上是一个返回 Python 中标准元组类型子类的一个工厂方法。你需要传递一个类型名和你需要的字段给它,然后它就会返回一个类,你可以初始化这个类,为你定义的字段传递值等。详情参见官方文档。
然后定义 Nude 类的初始化方法:
def?__init__(self,?path_or_image):
????#?若?path_or_image?为?Image.Image?类型的实例,直接赋值
????if?isinstance(path_or_image,?Image.Image):
????????self.image?=?path_or_image
????#?若?path_or_image?为?str?类型的实例,打开图片
????elif?isinstance(path_or_image,?str):
????????self.image?=?Image.open(path_or_image)
????#?获得图片所有颜色通道
????bands?=?self.image.getbands()
????#?判断是否为单通道图片(也即灰度图),是则将灰度图转换为?RGB?图
????if?len(bands)?==?1:
????????#?新建相同大小的?RGB?图像
????????new_img?=?Image.new("RGB",?self.image.size)
????????#?拷贝灰度图?self.image?到?RGB图?new_img.paste?(PIL?自动进行颜色通道转换)
????????new_img.paste(self.image)
????????f?=?self.image.filename
????????#?替换?self.image
????????self.image?=?new_img
????????self.image.filename?=?f
????#?存储对应图像所有像素的全部?Skin?对象
????self.skin_map?=?[]
????#?检测到的皮肤区域,元素的索引即为皮肤区域号,元素都是包含一些?Skin?对象的列表
????self.detected_regions?=?[]
????#?元素都是包含一些?int?对象(区域号)的列表
????#?这些元素中的区域号代表的区域都是待合并的区域
????self.merge_regions?=?[]
????#?整合后的皮肤区域,元素的索引即为皮肤区域号,元素都是包含一些?Skin?对象的列表
????self.skin_regions?=?[]
????#?最近合并的两个皮肤区域的区域号,初始化为?-1
????self.last_from,?self.last_to?=?-1,?-1
????#?色情图像判断结果
????self.result?=?None
????#?处理得到的信息
????self.message?=?None
????#?图像宽高
????self.width,?self.height?=?self.image.size
????#?图像总像素
????self.total_pixels?=?self.width?*?self.height
isinstane(object, classinfo)?如果参数?object?是参数?classinfo?的实例,返回真,否则假;参数?classinfo?可以是一个包含若干?type?对象的元组,如果参数?object?是其中任意一个类型的实例,返回真,否则假。
涉及到效率问题,越大的图片所需要消耗的资源与时间越大,因此有时候可能需要对图片进行缩小。所以需要有图片缩小方法:
def?resize(self,?maxwidth=1000,?maxheight=1000):
????"""
????基于最大宽高按比例重设图片大小,
????注意:这可能影响检测算法的结果
????如果没有变化返回?0
????原宽度大于?maxwidth?返回?1
????原高度大于?maxheight?返回?2
????原宽高大于?maxwidth,?maxheight?返回?3
????maxwidth?-?图片最大宽度
????maxheight?-?图片最大高度
????传递参数时都可以设置为?False?来忽略
????"""
????#?存储返回值
????ret?=?0
????if?maxwidth:
????????if?self.width?>?maxwidth:
????????????wpercent?=?(maxwidth?/?self.width)
????????????hsize?=?int((self.height?*?wpercent))
????????????fname?=?self.image.filename
????????????#?Image.LANCZOS?是重采样滤波器,用于抗锯齿
????????????self.image?=?self.image.resize((maxwidth,?hsize),?Image.LANCZOS)
????????????self.image.filename?=?fname
????????????self.width,?self.height?=?self.image.size
????????????self.total_pixels?=?self.width?*?self.height
????????????ret?+=?1
????if?maxheight:
????????if?self.height?>?maxheight:
????????????hpercent?=?(maxheight?/?float(self.height))
????????????wsize?=?int((float(self.width)?*?float(hpercent)))
????????????fname?=?self.image.filename
????????????self.image?=?self.image.resize((wsize,?maxheight),?Image.LANCZOS)
????????????self.image.filename?=?fname
????????????self.width,?self.height?=?self.image.size
????????????self.total_pixels?=?self.width?*?self.height
????????????ret?+=?2
????return?ret
Image.resize(size, resample=0)size – 包含宽高像素数的元祖 (width, height) resample – 可选的重采样滤波器
返回?
Image?对象
然后便是最关键之一的解析方法了:
def?parse(self):
????#?如果已有结果,返回本对象
????if?self.result?is?not?None:
????????return?self
????#?获得图片所有像素数据
????pixels?=?self.image.load()
接着,遍历每个像素,为每个像素创建对应的?Skin?对象,其中?self._classify_skin()?这个方法是检测像素颜色是否为肤色:
????for?y?in?range(self.height):
????????for?x?in?range(self.width):
????????????#?得到像素的?RGB?三个通道的值
????????????#?[x,?y]?是?[(x,y)]?的简便写法
????????????r?=?pixels[x,?y][0]???#?red
????????????g?=?pixels[x,?y][1]???#?green
????????????b?=?pixels[x,?y][2]???#?blue
????????????#?判断当前像素是否为肤色像素
????????????isSkin?=?True?if?self._classify_skin(r,?g,?b)?else?False
????????????#?给每个像素分配唯一?id?值(1,?2,?3...height*width)
????????????#?注意?x,?y?的值从零开始
????????????_id?=?x?+?y?*?self.width?+?1
????????????#?为每个像素创建一个对应的?Skin?对象,并添加到?self.skin_map?中
????????????self.skin_map.append(self.Skin(_id,?isSkin,?None,?x,?y))
若当前像素并不是肤色,那么跳过本次循环,继续遍历:
????????????#?若当前像素不为肤色像素,跳过此次循环
????????????if?not?isSkin:
????????????????continue
若当前像素是肤色像素,那么就需要处理了,先遍历其相邻像素。
一定要注意相邻像素的索引值,因为像素的?id?值是从?1?开始编起的,而索引是从?0?编起的。变量?_id是存有当前像素的?id?值, 所以当前像素在?self.skin_map?中的索引值为?_id - 1,以此类推,那么其左方的相邻像素在?self.skin_map?中的索引值为?_id - 1 - 1?,左上方为?_id - 1 - self.width - 1,上方为?_id - 1 - self.width?,右上方为?_id - 1 - self.width + 1?:
????????????#?设左上角为原点,相邻像素为符号?*,当前像素为符号?^,那么相互位置关系通常如下图
????????????#?***
????????????#?*^
????????????#?存有相邻像素索引的列表,存放顺序为由大到小,顺序改变有影响
????????????#?注意?_id?是从?1?开始的,对应的索引则是?_id-1
????????????check_indexes?=?[_id?-?2,?#?当前像素左方的像素
?????????????????????????????_id?-?self.width?-?2,??#?当前像素左上方的像素
?????????????????????????????_id?-?self.width?-?1,??#?当前像素的上方的像素
?????????????????????????????_id?-?self.width]??#?当前像素右上方的像素
把id值从0编起:
????????????#?用来记录相邻像素中肤色像素所在的区域号,初始化为?-1
????????????region?=?-1
????????????#?遍历每一个相邻像素的索引
????????????for?index?in?check_indexes:
????????????????#?尝试索引相邻像素的?Skin?对象,没有则跳出循环
????????????????try:
????????????????????self.skin_map[index]
????????????????except?IndexError:
????????????????????break
????????????????#?相邻像素若为肤色像素:
????????????????if?self.skin_map[index].skin:
????????????????????#?若相邻像素与当前像素的?region?均为有效值,且二者不同,且尚未添加相同的合并任务
????????????????????if?(self.skin_map[index].region?!=?None?and
????????????????????????????region?!=?None?and?region?!=?-1?and
????????????????????????????self.skin_map[index].region?!=?region?and
????????????????????????????self.last_from?!=?region?and
????????????????????????????self.last_to?!=?self.skin_map[index].region)?:
????????????????????????#?那么这添加这两个区域的合并任务
????????????????????????self._add_merge(region,?self.skin_map[index].region)
????????????????????#?记录此相邻像素所在的区域号
????????????????????region?=?self.skin_map[index].region
self._add_merge()?这个方法接收两个区域号,它将会把两个区域号添加到?self.merge_regions?中的元素中,self.merge_regions?的每一个元素都是一个列表,这些列表中存放了 1 到多个的区域号,区域号代表的区域是连通的,需要合并。
检测的图像里,有些前几行的像素的相邻像素并没有 4 个,所以需要用?try?“试错”。
然后相邻像素的若是肤色像素,如果两个像素的皮肤区域号都为有效值且不同,因为两个区域中的像素相邻,那么其实这两个区域是连通的,说明需要合并这两个区域。记录下此相邻肤色像素的区域号,之后便可以将当前像素归到这个皮肤区域里了。
遍历完所有相邻像素后,分两种情况处理:
所有相邻像素都不是肤色像素:发现了新的皮肤区域。 存在区域号为有效值的相邻肤色像素:region 的中存储的值有用了,把当前像素归到这个相邻像素所在的区域。
????????????#?遍历完所有相邻像素后,若?region?仍等于?-1,说明所有相邻像素都不是肤色像素
????????????if?region?==?-1:
????????????????#?更改属性为新的区域号,注意元祖是不可变类型,不能直接更改属性
????????????????_skin?=?self.skin_map[_id?-?1]._replace(region=len(self.detected_regions))
????????????????self.skin_map[_id?-?1]?=?_skin
????????????????#?将此肤色像素所在区域创建为新区域
????????????????self.detected_regions.append([self.skin_map[_id?-?1]])
????????????#?region?不等于?-1?的同时不等于?None,说明有区域号为有效值的相邻肤色像素
????????????elif?region?!=?None:
????????????????#?将此像素的区域号更改为与相邻像素相同
????????????????_skin?=?self.skin_map[_id?-?1]._replace(region=region)
????????????????self.skin_map[_id?-?1]?=?_skin
????????????????#?向这个区域的像素列表中添加此像素
????????????????self.detected_regions[region].append(self.skin_map[_id?-?1])
somenamedtuple._replace(kwargs)?返回一个替换指定字段的值为参数的?namedtuple实例
遍历完所有像素之后,图片的皮肤区域划分初步完成了,只是在变量?self.merge_regions?中还有一些连通的皮肤区域号,它们需要合并,合并之后就可以进行色情图片判定了:
????#?完成所有区域合并任务,合并整理后的区域存储到?self.skin_regions
????self._merge(self.detected_regions,?self.merge_regions)
????#?分析皮肤区域,得到判定结果
????self._analyse_regions()
????return?self
方法?self._merge()?便是用来合并这些连通的皮肤区域的。方法?self._analyse_regions(),运用之前在程序原理一节定义的非色情图像判定规则,从而得到判定结果。现在编写我们还没写过的调用过的?Nude?类的方法。
首先是?self._classify_skin()?方法,这个方法是检测像素颜色是否为肤色,之前在程序原理一节已经把肤色判定该公式列举了出来,现在是用的时候了:
#?基于像素的肤色检测技术
def?_classify_skin(self,?r,?g,?b):
????#?根据RGB值判定
????rgb_classifier?=?r?>?95?and?\
????????g?>?40?and?g?<?100?and?\
????????b?>?20?and?\
????????max([r,?g,?b])?-?min([r,?g,?b])?>?15?and?\
????????abs(r?-?g)?>?15?and?\
????????r?>?g?and?\
????????r?>?b
????#?根据处理后的?RGB?值判定
????nr,?ng,?nb?=?self._to_normalized(r,?g,?b)
????norm_rgb_classifier?=?nr?/?ng?>?1.185?and?\
????????float(r?*?b)?/?((r?+?g?+?b)?**?2)?>?0.107?and?\
????????float(r?*?g)?/?((r?+?g?+?b)?**?2)?>?0.112
????#?HSV?颜色模式下的判定
????h,?s,?v?=?self._to_hsv(r,?g,?b)
????hsv_classifier?=?h?>?0?and?\
????????h?<?35?and?\
????????s?>?0.23?and?\
????????s?<?0.68
????#?YCbCr?颜色模式下的判定
????y,?cb,?cr?=?self._to_ycbcr(r,?g,??b)
????ycbcr_classifier?=?97.5?<=?cb?<=?142.5?and?134?<=?cr?<=?176
????#?效果不是很好,还需改公式
????#?return?rgb_classifier?or?norm_rgb_classifier?or?hsv_classifier?or?ycbcr_classifier
????return?ycbcr_classifier
颜色模式的转换并不是本实验的重点,转换公式可以在网上找到,这里我们直接拿来用就行:
def?_to_normalized(self,?r,?g,?b):
????if?r?==?0:
????????r?=?0.0001
????if?g?==?0:
????????g?=?0.0001
????if?b?==?0:
????????b?=?0.0001
????_sum?=?float(r?+?g?+?b)
????return?[r?/?_sum,?g?/?_sum,?b?/?_sum]
def?_to_ycbcr(self,?r,?g,?b):
????#?公式来源:
????#?http://stackoverflow.com/questions/19459831/rgb-to-ycbcr-conversion-problems
????y?=?.299*r?+?.587*g?+?.114*b
????cb?=?128?-?0.168736*r?-?0.331364*g?+?0.5*b
????cr?=?128?+?0.5*r?-?0.418688*g?-?0.081312*b
????return?y,?cb,?cr
def?_to_hsv(self,?r,?g,?b):
????h?=?0
????_sum?=?float(r?+?g?+?b)
????_max?=?float(max([r,?g,?b]))
????_min?=?float(min([r,?g,?b]))
????diff?=?float(_max?-?_min)
????if?_sum?==?0:
????????_sum?=?0.0001
????if?_max?==?r:
????????if?diff?==?0:
????????????h?=?sys.maxsize
????????else:
????????????h?=?(g?-?b)?/?diff
????elif?_max?==?g:
????????h?=?2?+?((g?-?r)?/?diff)
????else:
????????h?=?4?+?((r?-?g)?/?diff)
????h?*=?60
????if?h?<?0:
????????h?+=?360
????return?[h,?1.0?-?(3.0?*?(_min?/?_sum)),?(1.0?/?3.0)?*?_max]
self._add_merge()?方法主要是对?self.merge_regions?操作,而self.merge_regions 的元素都是包含一些 int 对象(区域号)的列表,列表中的区域号代表的区域都是待合并的区。self._add_merge()?方法接收两个区域号,将之添加到?self.merge_regions?中。
这两个区域号以怎样的形式添加,要分 3 种情况处理:
传入的两个区域号都存在于? self.merge_regions?中传入的两个区域号有一个区域号存在于? self.merge_regions?中传入的两个区域号都不存在于? self.merge_regions?中
具体的处理方法,见代码:
def?_add_merge(self,?_from,?_to):
????#?两个区域号赋值给类属性
????self.last_from?=?_from
????self.last_to?=?_to
????
????#?记录?self.merge_regions?的某个索引值,初始化为?-1
????from_index?=?-1
????#?记录?self.merge_regions?的某个索引值,初始化为?-1
????to_index?=?-1
????#?遍历每个?self.merge_regions?的元素
????for?index,?region?in?enumerate(self.merge_regions):
????????#?遍历元素中的每个区域号
????????for?r_index?in?region:
????????????if?r_index?==?_from:
????????????????from_index?=?index
????????????if?r_index?==?_to:
????????????????to_index?=?index
????#?若两个区域号都存在于?self.merge_regions?中
????if?from_index?!=?-1?and?to_index?!=?-1:
????????#?如果这两个区域号分别存在于两个列表中
????????#?那么合并这两个列表
????????if?from_index?!=?to_index:
????????????self.merge_regions[from_index].extend(self.merge_regions[to_index])
????????????del(self.merge_regions[to_index])
????????return
????#?若两个区域号都不存在于?self.merge_regions?中
????if?from_index?==?-1?and?to_index?==?-1:
????????#?创建新的区域号列表
????????self.merge_regions.append([_from,?_to])
????????return
????#?若两个区域号中有一个存在于?self.merge_regions?中
????if?from_index?!=?-1?and?to_index?==?-1:
????????#?将不存在于?self.merge_regions?中的那个区域号
????????#?添加到另一个区域号所在的列表
????????self.merge_regions[from_index].append(_to)
????????return
????#?若两个待合并的区域号中有一个存在于?self.merge_regions?中
????if?from_index?==?-1?and?to_index?!=?-1:
????????#?将不存在于?self.merge_regions?中的那个区域号
????????#?添加到另一个区域号所在的列表
????????self.merge_regions[to_index].append(_from)
????????return
在序列中循环时,索引位置和对应值可以使用?enumerate()?函数同时得到,在上面的代码中,索引位置即为?index?,对应值即为region。self._merge()?方法则是将?self.merge_regions?中的元素中的区域号所代表的区域合并,得到新的皮肤区域列表:
def?_merge(self,?detected_regions,?merge_regions):
????#?新建列表?new_detected_regions?
????#?其元素将是包含一些代表像素的?Skin?对象的列表
????#?new_detected_regions?的元素即代表皮肤区域,元素索引为区域号
????new_detected_regions?=?[]
????#?将?merge_regions?中的元素中的区域号代表的所有区域合并
????for?index,?region?in?enumerate(merge_regions):
????????try:
????????????new_detected_regions[index]
????????except?IndexError:
????????????new_detected_regions.append([])
????????for?r_index?in?region:
????????????new_detected_regions[index].extend(detected_regions[r_index])
????????????detected_regions[r_index]?=?[]
????#?添加剩下的其余皮肤区域到?new_detected_regions
????for?region?in?detected_regions:
????????if?len(region)?>?0:
????????????new_detected_regions.append(region)
????#?清理?new_detected_regions
????self._clear_regions(new_detected_regions)
????????#?添加剩下的其余皮肤区域到?new_detected_regions
????????for?region?in?detected_regions:
????????????if?len(region)?>?0:
????????????????new_detected_regions.append(region)
????????#?清理?new_detected_regions
????????self._clear_regions(new_detected_regions)
self._clear_regions()?方法只将像素数大于指定数量的皮肤区域保留到?self.skin_regions?:
#?皮肤区域清理函数
#?只保存像素数大于指定数量的皮肤区域
def?_clear_regions(self,?detected_regions):
????for?region?in?detected_regions:
????????if?len(region)?>?30:
????????????self.skin_regions.append(region)
self._analyse_regions()?是很简单的,它的工作只是进行一系列判断,得出图片是否色情的结论:
#?分析区域
def?_analyse_regions(self):
????#?如果皮肤区域小于?3?个,不是色情
????if?len(self.skin_regions)?<?3:
????????self.message?=?"Less?than?3?skin?regions?({_skin_regions_size})".format(
????????????_skin_regions_size=len(self.skin_regions))
????????self.result?=?False
????????return?self.result
????#?为皮肤区域排序
????self.skin_regions?=?sorted(self.skin_regions,?key=lambda?s:?len(s),
???????????????????????????????reverse=True)
????#?计算皮肤总像素数
????total_skin?=?float(sum([len(skin_region)?for?skin_region?in?self.skin_regions]))
????#?如果皮肤区域与整个图像的比值小于?15%,那么不是色情图片
????if?total_skin?/?self.total_pixels?*?100?<?15:
????????self.message?=?"Total?skin?percentage?lower?than?15?({:.2f})".format(total_skin?/?self.total_pixels?*?100)
????????self.result?=?False
????????return?self.result
????#?如果最大皮肤区域小于总皮肤面积的?45%,不是色情图片
????if?len(self.skin_regions[0])?/?total_skin?*?100?<?45:
????????self.message?=?"The?biggest?region?contains?less?than?45?({:.2f})".format(len(self.skin_regions[0])?/?total_skin?*?100)
????????self.result?=?False
????????return?self.result
????#?皮肤区域数量超过?60个,不是色情图片
????if?len(self.skin_regions)?>?60:
????????self.message?=?"More?than?60?skin?regions?({})".format(len(self.skin_regions))
????????self.result?=?False
????????return?self.result
????#?其它情况为色情图片
????self.message?=?"Nude!!"
????self.result?=?True
????return?self.result
然后可以组织下分析得出的信息:
def?inspect(self):
????_image?=?'{}?{}?{}×{}'.format(self.image.filename,?self.image.format,?self.width,?self.height)
????return?"{_image}:?result={_result}?message='{_message}'".format(_image=_image,?_result=self.result,?_message=self.message)
Nude?类如果就这样完成了,最后运行脚本时只能得到一些真或假的结果,我们需要更直观的感受程序的分析效果,我们可以生成一张原图的副本,不过这个副本图片中只有黑白色,白色代表皮肤区域,那么这样我们能直观感受到程序分析的效果了。
前面的代码中我们有获得图像的像素的 RGB 值的操作,设置像素的 RGB 值也就是其逆操作,还是很简单的,不过注意设置像素的 RGB 值时不能在原图上操作:
#?将在源文件目录生成图片文件,将皮肤区域可视化
def?showSkinRegions(self):
????#?未得出结果时方法返回
????if?self.result?is?None:
????????return
????#?皮肤像素的?ID?的集合
????skinIdSet?=?set()
????#?将原图做一份拷贝
????simage?=?self.image
????#?加载数据
????simageData?=?simage.load()
????#?将皮肤像素的?id?存入?skinIdSet
????for?sr?in?self.skin_regions:
????????for?pixel?in?sr:
????????????skinIdSet.add(pixel.id)
????#?将图像中的皮肤像素设为白色,其余设为黑色
????for?pixel?in?self.skin_map:
????????if?pixel.id?not?in?skinIdSet:
????????????simageData[pixel.x,?pixel.y]?=?0,?0,?0
????????else:
????????????simageData[pixel.x,?pixel.y]?=?255,?255,?255
????#?源文件绝对路径
????filePath?=?os.path.abspath(self.image.filename)
????#?源文件所在目录
????fileDirectory?=?os.path.dirname(filePath)?+?'/'
????#?源文件的完整文件名
????fileFullName?=?os.path.basename(filePath)
????#?分离源文件的完整文件名得到文件名和扩展名
????fileName,?fileExtName?=?os.path.splitext(fileFullName)
????#?保存图片
????simage.save('{}{}_{}{}'.format(fileDirectory,?fileName,'Nude'?if?self.result?else?'Normal',?fileExtName))
变量?skinIdSet?使用集合而不是列表是有性能上的考量的,Python 中的集合是哈希表实现的,查询效率很高。最后支持一下命令行参数就大功告成啦!我们使用?argparse?这个模块来实现命令行的支持。argparse 模块使得编写用户友好的命令行接口非常容易。程序只需定义好它要求的参数,然后 argparse 将负责如何从 sys.argv 中解析出这些参数。argparse 模块还会自动生成帮助和使用信息并且当用户赋给程序非法的参数时产生错误信息。
具体使用方法请查看argparse的?官方文档
if?__name__?==?"__main__":
????import?argparse
????parser?=?argparse.ArgumentParser(description='Detect?nudity?in?images.')
????parser.add_argument('files',?metavar='image',?nargs='+',
????????????????????????help='Images?you?wish?to?test')
????parser.add_argument('-r',?'--resize',?action='store_true',
????????????????????????help='Reduce?image?size?to?increase?speed?of?scanning')
????parser.add_argument('-v',?'--visualization',?action='store_true',
????????????????????????help='Generating?areas?of?skin?image')
????args?=?parser.parse_args()
????for?fname?in?args.files:
????????if?os.path.isfile(fname):
????????????n?=?Nude(fname)
????????????if?args.resize:
????????????????n.resize(maxheight=800,?maxwidth=600)
????????????n.parse()
????????????if?args.visualization:
????????????????n.showSkinRegions()
????????????print(n.result,?n.inspect())
????????else:
????????????print(fname,?"is?not?a?file")
测试效果
先来一张很正经的测试图片:

在PyCharm中的终端运行下面的命令执行脚本,注意是python3而不是python:
python3?nude.py?-v?1.jpg?
运行截图:

这表示1.jpg不是一张色情图片
总结
这个项目就是熟悉了一下PIL的使用,了解了色情图片检查的原理。主要实现难点是在皮肤区域的检测与整合这一方面。项目还有许多可以改进的地方,比如肤色检测公式,色情判定条件,还有性能问题,我得去学习一下用多线程或多进程提高性能。
来源:码猴小明
本文仅做学术分享,如有侵权,请联系删文
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/




![秦海璐 今晚团建啦~[挤眼]#第15届金鹰节开幕式# ](https://imgs.knowsafe.com:8087/img/aideep/2024/10/30/531122b0f609f0144a0eaa7cfd4e50ed.jpg?w=250)

 程序员之家
程序员之家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675