
TiDB 6.0 实战分享丨冷热存储分离解决方案
TiDB 6.0 以 SQL 形式对用户暴露数据调度框架(Placement Rule In SQL),使得 TiDB 在多中心,冷热数据分离和大量写入所需的缓冲隔离等场景下也能够提供灵活的应对。本文将基于大数据冷热分离归档业务场景,重点探讨冷热数据归档存储的功能和特性,以便其在大规模 HTAP 集群归档中的实践应用。
作者简介:李文杰,网易游戏计费 TiDB 负责人,TUG 核心成员,TUG 2019 年和 2020 年 MVA。
结论先行
1. 冷热分离存储,降低存储成本
将热数据从 ssd 迁移到 hdd,每小时可归档约 3000 万行,总体来看效率还是比较高的;
将冷数据从 hdd 迁移到 ssd,每小时可迁移约 6300 万行,大约是从 ssd 迁移到 hdd 速度的 2 倍;
分离存储过程,ssd 和 hdd 用于归档的 IO 消耗都在 10%以内,集群访问 QPS 表现平稳,对业务访问的影响较小;
在补写冷数据场景,每小时写入约 1500 万行到 hdd,数据可正确地直接写入 hdd,不会经过 ssd。
2. 业务底层物理隔离,实现同一集群不同存储
通过放置规则管理将不同数据库下的数据调度到不同的硬件节点上,实现业务间数据的物理资源隔离,避免因资源争抢,硬件故障等问题造成的相互干扰;
通过账号权限管理避免跨业务数据访问,提升数据质量和数据安全。
3. 合并 MySQL 业务,降低运维压力,提升管理效率
概述
动态指定重要数据的副本数,提高业务可用性和数据可靠性;
将最新数据存入 ssd,历史数据存入 hdd,降低归档数据存储成本;
把热点数据的 leader 放到高性能的 TiKV 实例上,提供高效访问;
不同业务共用一个集群,而底层按业务实现存储物理隔离,互不干扰,极大提升业务稳定性;
合并大量不同业务的 MySQL 实例到统一集群,底层实现存储隔离,减少管理大量数据库的成本。
原理简介
mysql>?show?placement?labels?;
+------+-----------------------------------------------------------------+
|?Key??|?Values??????????????????????????????????????????????????????????|
+------+-----------------------------------------------------------------+
|?disk?|?["ssd"]?????????????????????????????????????????????????????????|
|?host?|?["tikv1",?"tikv2",?"tikv3"]?|
|?rack?|?["r1"]??????????????????????????????????????????????????????????|
|?zone?|?["guangzhou"]???????????????????????????????????????????????????|
+------+-----------------------------------------------------------------+
4?rows?in?set?(0.00?sec)(1) 基础放置策略
#创建放置策略
CREATE?PLACEMENT?POLICY?myplacementpolicy?PRIMARY_REGION="guangzhou"?REGIONS="guangzhou,shenzhen";
#将规则绑定至表或分区表,这样指定了放置规则
CREATE?TABLE?t1?(a?INT)?PLACEMENT?POLICY=myplacementpolicy;
CREATE?TABLE?t2?(a?INT);
ALTER?TABLE?t2?PLACEMENT?POLICY=myplacementpolicy;
#查看放置规则的调度进度,所有绑定规则的对象都是异步调度的。
SHOW?PLACEMENT;
#查看放置策略
SHOW?CREATE?PLACEMENT?POLICY?myplacementpolicy\G
select?*?from?information_schema.placement_policies\G
#修改放置策略,修改后会传播到所有绑定此放置策略的对象
ALTER?PLACEMENT?POLICY?myplacementpolicy?FOLLOWERS=5;
#删除没有绑定任何对象的放置策略
DROP?PLACEMENT?POLICY?myplacementpolicy;(2) 高级放置策略
#?创建策略,指定数据只存储在ssd
CREATE?PLACEMENT?POLICY?storeonfastssd?CONSTRAINTS="[+disk=ssd]";
#?创建策略,指定数据只存储在hdd
CREATE?PLACEMENT?POLICY?storeonhdd?CONSTRAINTS="[+disk=hdd]";
#?在分区表应用高级放置策略,指定分区存储在hdd或者ssd上,未指定的分区由系统自动调度
CREATE?TABLE?t1?(id?INT,?name?VARCHAR(50),?purchased?DATE)
PARTITION?BY?RANGE(?YEAR(purchased)?)?(
PARTITION?p0?VALUES?LESS?THAN?(2000)?PLACEMENT?POLICY=storeonhdd,
PARTITION?p1?VALUES?LESS?THAN?(2005),
PARTITION?p2?VALUES?LESS?THAN?(2010),
PARTITION?p3?VALUES?LESS?THAN?(2015),
PARTITION?p4?VALUES?LESS?THAN?MAXVALUE?PLACEMENT?POLICY=storeonfastssd
);环境

冷热归档存储
功能验证
部署 TiDB v6.0.0 集群,具体参考部署集群操作
创建数据落盘策略,以备使用
#?应用该策略的库、表、分区,数据会存储在ssd上
CREATE?PLACEMENT?POLICY?storeonssd?CONSTRAINTS="[+disk=ssd]"?;
#?应用该策略的库、表、分区,数据会存储在hdd上
CREATE?PLACEMENT?POLICY?storeonhdd?CONSTRAINTS="[+disk=hdd]";
#查看集群已有策略
mysql>?show?placement?\G
***************************?1.?row?***************************
Target:?POLICY?storeonhdd
Placement:?CONSTRAINTS="[+disk=hdd]"
Scheduling_State:?NULL
***************************?2.?row?***************************
Target:?POLICY?storeonssd
Placement:?CONSTRAINTS="[+disk=ssd]"
Scheduling_State:?NULL
2?rows?in?set?(0.02?sec)
#?创建数据库tidb_ssd_hdd_test,并设置该库默认落盘策略,设置后新建的表都会默认继承该策略
create?database?tidb_ssd_hdd_test??PLACEMENT?POLICY=storeonssd;
#?查看策略已经应用到指定库上
mysql>?show?placement?\G
***************************?1.?row?***************************
Target:?POLICY?storeonhdd
Placement:?CONSTRAINTS="[+disk=hdd]"
Scheduling_State:?NULL
***************************?2.?row?***************************
Target:?POLICY?storeonssd
Placement:?CONSTRAINTS="[+disk=ssd]"
Scheduling_State:?NULL
***************************?3.?row?***************************
Target:?DATABASE?tidb_ssd_hdd_test
Placement:?CONSTRAINTS="[+disk=ssd]"
Scheduling_State:?SCHEDULED
3?rows?in?set?(0.02?sec)
#?建立分区表,可以看到表建立后默认继承和库一样的落盘策略,关键标识为“/*T![placement]?PLACEMENT?POLICY=`storeonssd`?*/”
CREATE?TABLE?`logoutrole_log?`?(
`doc_id`?varchar(255)?NOT?NULL,
`gameid`?varchar(255)?DEFAULT?NULL?,
--?some?fields
`logdt`?timestamp?DEFAULT?'1970-01-01?08:00:00'?,
`updatetime`?varchar(255)?DEFAULT?NULL?,
UNIQUE?KEY?`doc_id`?(`doc_id`,`logdt`),
--?some?index
KEY?`logdt_gameid`?(`logdt`,`gameid`)
)?ENGINE=InnoDB?DEFAULT?CHARSET=utf8mb4?COLLATE=utf8mb4_bin?/*T![placement]?PLACEMENT?POLICY=`storeonssd`?*/
PARTITION?BY?RANGE?(?UNIX_TIMESTAMP(`logdt`)?)?(
PARTITION?`p20220416`?VALUES?LESS?THAN?(UNIX_TIMESTAMP('2022-04-17?00:00:00')),
PARTITION?`p20220417`?VALUES?LESS?THAN?(UNIX_TIMESTAMP('2022-04-18?00:00:00')),
PARTITION?`p20220418`?VALUES?LESS?THAN?(UNIX_TIMESTAMP('2022-04-19?00:00:00')),
PARTITION?`p20220419`?VALUES?LESS?THAN?(UNIX_TIMESTAMP('2022-04-20?00:00:00')),
PARTITION?`p20220420`?VALUES?LESS?THAN?(UNIX_TIMESTAMP('2022-04-21?00:00:00')),
PARTITION?`p20220421`?VALUES?LESS?THAN?(UNIX_TIMESTAMP('2022-04-22?00:00:00')),
PARTITION?`p20220422`?VALUES?LESS?THAN?(UNIX_TIMESTAMP('2022-04-23?00:00:00'))
);
集群只有 3 个 ssd 的 TiKV?节点,启动 Flink 流往目标表导入数据,可以看到这 3 个 ssd 节点的 region 数和空间使用在不断增长

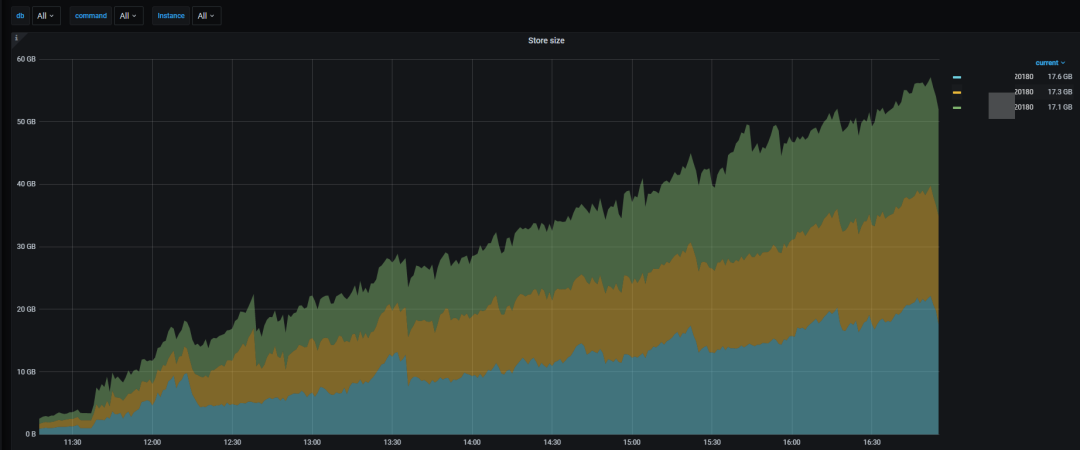
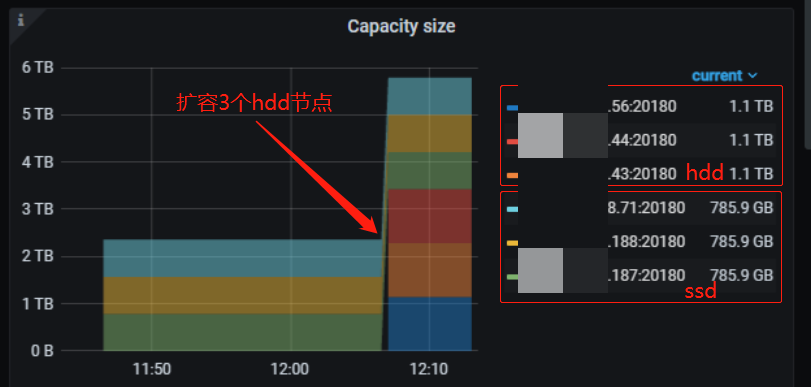
在原有基础上再扩容 3 个 hdd TiKV?实例
mysql>?select?date(logdt)?as?day,count(0)?from?logoutrole_log?group?by?day?order?by?day?;
+------------+----------+
|?day????????|?count(0)?|
+------------+----------+
|?2022-04-16?|??1109819?|
+------------+----------+
1?row?in?set?(1.09?sec)mysql>?alter?table?tidb_ssd_hdd_test.logoutrole_log?partition?p20220416?placement?policy?storeonhdd;
Query?OK,?0?rows?affected?(0.52?sec)


静态集群冷热存储分离(无外部访问)
ssd->hdd
alter?table?tidb_ssd_hdd_test.logoutrole_log?partition?p20220417?placement?policy?storeonhdd;

ssd 上的 region 全部迁移到 hdd 上,ssd 空间被释放,hdd 空间使用逐渐增加,迁移过程中 ssd 和 hdd 的 IO 消耗都在 5%左右,内存和网络带宽使用不变、保持平稳。约 6 千万行 130GB 数据从 ssd 数据迁移到 hdd 大概需要 2 个小时。
在将大规模数据从 ssd 数据迁移到 hdd 过程,集群资源消耗比较低,可以有效避免过多占用集群资源。
在集群没有外部访问压力时,在默认配置下,集群以每小时约 3000 万行的速度从 ssd 迁移到 hdd 节点。
hdd->ssd

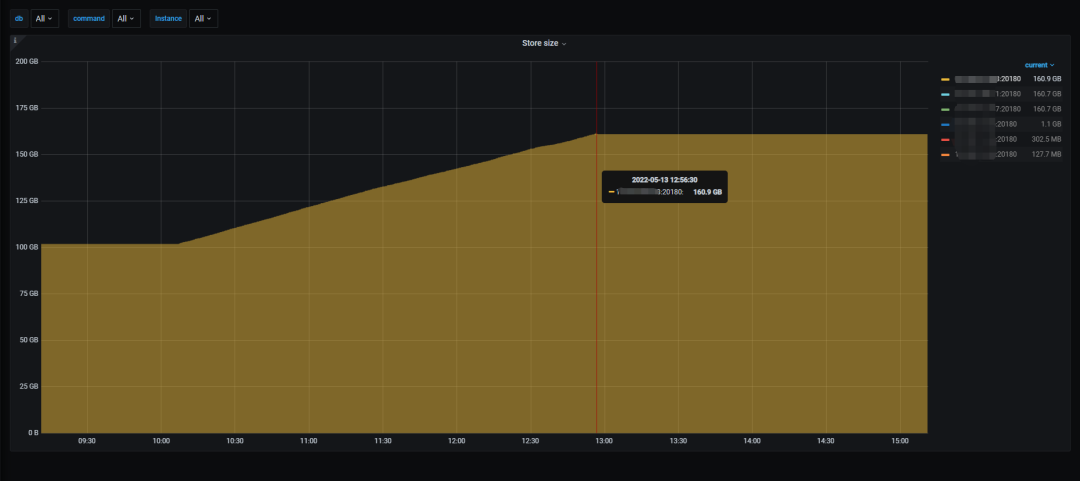

将冷数据从 hdd 迁移至 ssd,迁移 1.7 亿行共约 200GB 数据,大约耗时 2 小时 40 分钟,平均每小时迁移 6300 万行,速度约为将热数据从 ssd 迁到 hdd 的 2 倍(每小时约 3000 万行)。
将数据从 hdd 迁移至 ssd 的过程,不管是对 ssd 还是 hdd,其平均 IO 使用率都不高,不会占用过多集群的资源,可以认为数据迁移过程对集群正在运行的业务影响不大。
热集群冷热存储分离(外部持续访问)
#应用放置策略将2022-04-18数据从ssd归档到hdd
alter?table?tidb_ssd_hdd_test.logoutrole_log?partition?p20220418?placement?policy?storeonhdd;在归档数据时,ssd 的 TiKV?region 数从 6300 下降到 3500 左右,当迁移完成后是净写入数据,此时 ssd 节点的 region 数量又持续上升;
hdd 节点的 region 数从开始的 2600 上升到 6500 左右,随着数据迁移完成,hdd 的 region 数不再增加,一直保持 6500 不变。
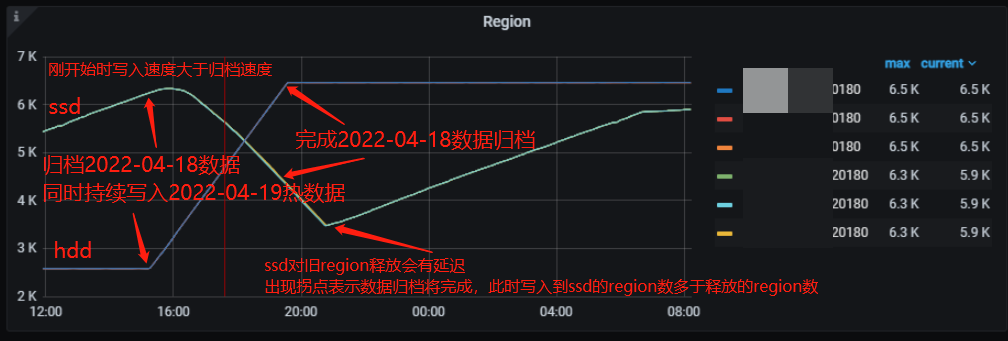
归档数据时,ssd 节点的磁盘使用空间从 152GB 下降到 88GB,当迁移完成后,此时是净写入数据,ssd 空间开始上升;
数据在不断写入到 hdd 节点,所以其使用空间从 61GB 上升到 154GB,随着数据迁移完成,一直保持不变。

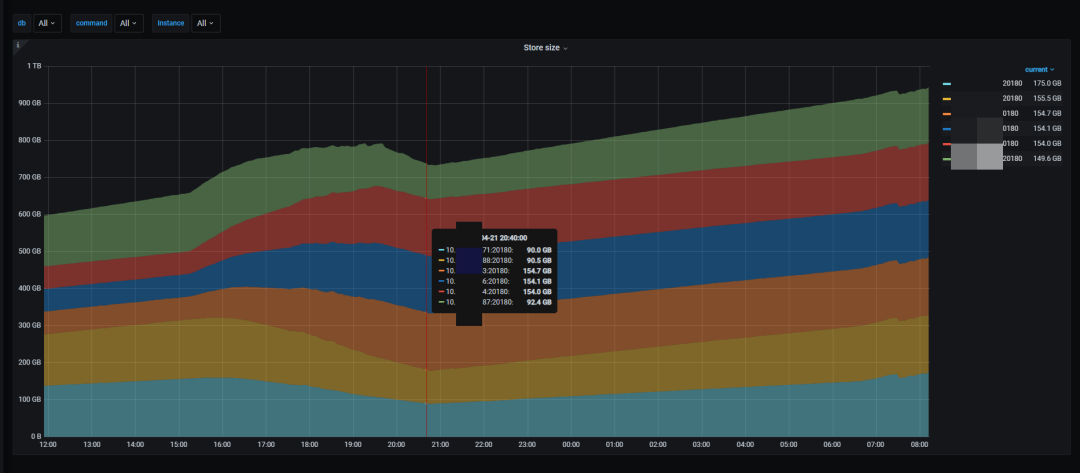
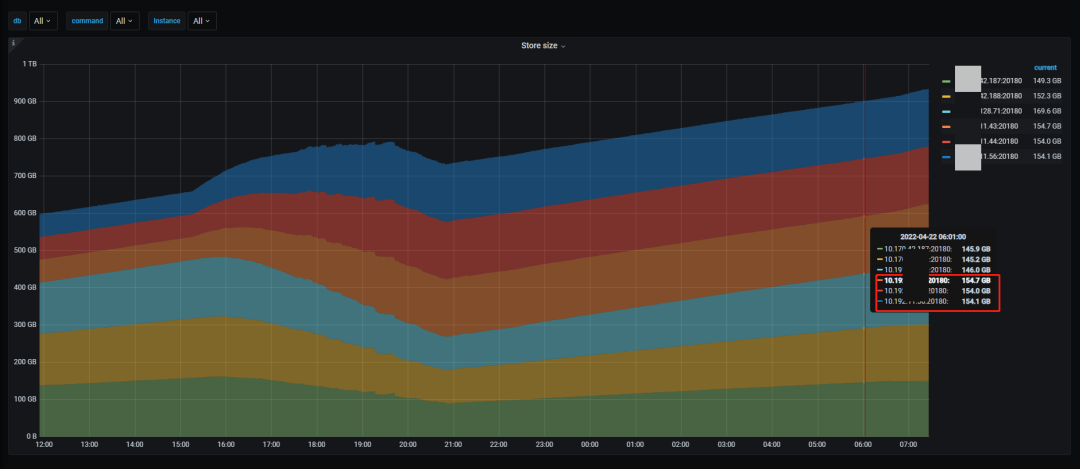
在有外部几乎是满 IO 的写入压力时,归档约 2 亿行、400GB 数据从 ssd 到 hdd 节点,大概需要 6 个小时,即约 3300 万行/小时,可以说冷数据的归档效率还是比较高的。
集群后台在进行数据归档时,Flink 的 sink QPS 变化不大,可以认为归档的过程对集群正常写入影响不大。
归档数据补写

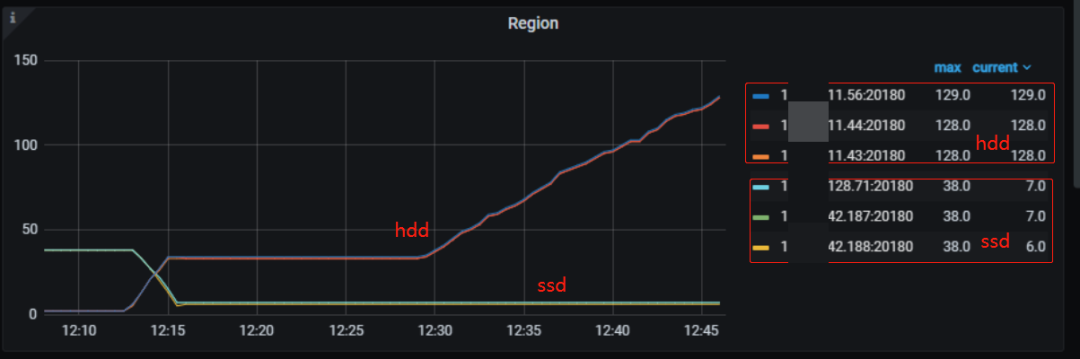
说明 TiDB 冷热数据分离存储功能,在补全历史冷数据的场景,即归档数据补写,数据可以正确地直接写入到 hdd,期间数据不会经过 ssd;
补全冷数据,hdd TiKV?节点 IO 打满,ssd 的 IO 使用率比较低,也说明数据不会经过 ssd。
同一集群业务隔离

CREATE?PLACEMENT?POLICY?'shared_nodes'?CONSTRAINTS?=?"[+region=shared_nodes]";
CREATE?PLACEMENT?POLICY?'business_c'?CONSTRAINTS?=?"[+region=business_c]";
CREATE?PLACEMENT?POLICY?'business_d'?CONSTRAINTS?=?"[+region=business_d]";
ALTER?DATABASE?a?POLICY=shared_nodes;
ALTER?DATABASE?b?POLICY=shared_nodes;
ALTER?DATABASE?c?POLICY=business_c;
ALTER?DATABASE?d?POLICY=business_d;总结
对已有集群应用 Placement Rules
0. 将集群升级到 6.0.0 版本
1. 创建默认 ssd?策略
2. 打开放置策略默认开关,使得集群已有库表都默认存储在 ssd 上 (该功能依赖官方发布新版本支持)
- 目前只能用脚本 alter 全部库设置这个默认策略,如果有新增的库也需要提前进行设置
3. 申请新机器并扩容新的 hdd TiKV
4. 创建 hdd 放置策略
5. 在目标表的目标分区上指定 ssd 或 hdd 策略
6. 定期将过期分区声明 hhd 放置策略
对新建的集群应用 Placement Rules
0.?部署 6.0.0 集群版本 1. 创建默认 ssd?策略 2.?创建的全部库都先设置这个默认策略 3.?申请新机器并扩容新的?hdd TiKV? ? 4.?创建 hdd 放置策略? 5.?在目标表或目标分区上指定 ssd 或 hdd?策略? 6.?定期将过期分区声明 hhd 放置策略?
活动预告
新发布的 TiDB 6.0 大幅增强了 TiDB 作为企业级产品的可管理性,具备更成熟的 HTAP 与容灾能力,加入多项云原生数据库所需的基础特性。抢先试用 TiDB 6.0、TiFlash、TiEM 和 PingCAP Clinic 等多款新品与服务,参与 Book Rush 贡献,将有机会享受 “TiDB 荣誉体验官” 在内的多项权益!
扫描下方二维码了解详情

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 PingCAP
PingCAP
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675