
Nature子刊 | NUS、字节首次将AI元学习引入脑成像领域
近期,新加坡国立大学、字节跳动智能创作新加坡团队等机构合作的一项技术成果被全球顶级学术期刊Nature的子刊Nature Neuroscience收录。这项研究首次将人工智能领域的元学习方法引入到神经科学及医疗领域,能在有限的医疗数据上训练可靠的AI模型,提升基于脑成像的精准医疗效果。

研究背景
脑成像技术是神经科学发展的一个重要领域,能够直接观察大脑在信息处理和应对刺激时的神经化学变化、从而对疾病的诊断和治疗提供重要参照。理论上,基于脑成像的机器学习模型可应用于预测个人(individual)的一些非脑成像(non-brain-imaging)的表征特性(phenotypes) ,例如,流动智力 (fluid intelligence)、临床结果(clinical outcomes)等,从而促进针对个人的精准医疗( precision medicine)。
一个现实的问题在于,虽然现在已经有英国生物银行(UK Biobank)这样的大规模人类神经科学数据集,在研究临床人群或解决重点神经科学的问题时,几十到上百人的小规模数据样本依旧是常态。在精确标注的医疗数据量有限的情况下,很难训练出一个可靠的机器学习模型来预测个人表征特性。
论文提出一个新的思路来解决这一数据匮乏所带来的根本限制:在给定一个大规模(N>10,000)的带有多种表征特性标注的脑成像数据集,可以将在该数据集上训练的机器学习模型迁移到一个独立的小规模(N<200)的带有新的表征特性的数据集上,从而使得在新的数据集上训练的模型能够准确预测新的表征特性。
方法
研究者通过对先前的小样本数据分析发现,个体的认知、心理健康、人口统计学和其他健康属性等表征特性与大脑成像数据之间存在一种内在的相关性。这意味着,小数据集当中的某些独特表型可能与大规模数据集当中的某些预先存在的特定表型相关,利用这种相关性,研究者提出了一个新的基于元学习的元匹配方法建立了一种框架机制,可利用大规模脑成像数据集来促进对小数据集当中一些全新的、未知的表型的预测,从而训练出可靠的用于表征特性预测的机器学习模型。
论文提出了一种新的元匹配(meta-matching)方法,来解决小规模数据集上的表征特性预测模型的训练问题。元匹配是一种高度灵活的学习框架,可以用于各种不同的机器学习方法。论文主要研究了将元匹配方法应用于核岭回归(kernel ridge regression, KRR)以及全连接的深度神经网络(DNN).
在元匹配的学习框架中,大规模的训练数据被分为元训练集 (training meta-set) 以及元测试集 (testing meta-set)。这两个数据集包含不同的个体和表征特性标注。元训练集被用来训练DNN预测模型,而元测试集则用来评估当前DNN模型在新的表征特性上的预测准确率(也即泛化性能)。特别的,随机挑选的K个(K<5)个体数据被选作测试样本。而在元测试集上表现最好的一个DNN输出节点(output node)将被保留,而其他节点被移除。之后在该K个测试个体数据,微调(fine-tune)该保留的节点以及DNN模型之前与该节点相连的隐藏层参数。注意与一般的元学习或者微调策略不同的是,这里只微调DNN模型中的一个子网络,而不是微调整个模型参数。该过程将被重复M次,直到DNN模型在元测试集上预测稳定为止。
在完成上述的元训练过程以后,得到的DNN模型已具有了较强的在新的预测任务上的泛化能力。该模型可以直接迁移到新的表征特性数据集上,用少量的标注样本进行训练,即可有较好的预测性能。

实验设置
论文在英国生物银行(UK Biobank)和人类连接组计划(Human Connectome Project)数据集上进行了测评。所有数据的使用均已经过了相关研究部门批准。其中 UK Biobank 包含36,848名参与者的结构MRI以及静息fMRI脑成像数据,以及被筛选出的67个非脑成像的表征特性。而HCP包含 1,019 名参与者的结构MRI以及静息fMRI数据,以及被筛选出的58个表征特性。所筛选的表征特性涵盖了意识(cognition)、情绪(emotion)以及个人特质(personality)。
UK Biobank数据集被用作训练集,用于使用元匹配来训练预测模型。其被随机分为元训练集(26,848名参与者,33个表征特性)以及元测试集(10,000名参与者,34个表征特性)。而HCP数据集则被用作测试集、测试预测模型在新的表征特性上的预测准确率。其被随机分为K个参与者用于训练以及(1,019-K)个参与者用来测试。其中K取值为19,20,50,100和200.

△?图. HCP表据集表形特性示例
实验结论
上述方法已经在英国生物银行(UK Biobank)的 36,848 名参与者和来自人类连接组计划(Human Connectome Project)的 1,019 名参与者的样本评估中显示出有效性。
在BioBank测试集上性能超过经典的核岭回归(KRR)
下图展示了在UK Biobank元测试集 基于Pearson’s相关系数的准确性比较。在所有的样本数量设置上(K值),所提出的元匹配方法在34个表征特性准确率大幅超过经典的KRR方法 (伪发现率FDR q<0.05). 例如在fMRI研究中常见的样本数量K=20 (20-shot),基本的DNN meta-matching 方法准确率超过KRR 100% (0.124 vs. 0.052). 而如果采用coefficient of determinant (COD)作为性能指标,DNN meta-matching方法则超过KRR 400% .
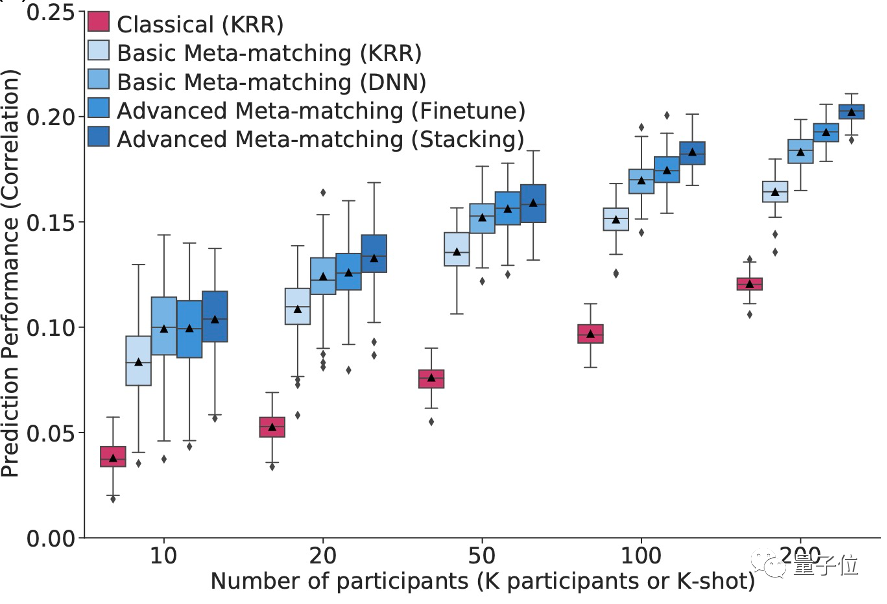
在HCP小规模新数据集上显著超过KRR
为了测试元匹配在全新的测试集上的表现,论文进一步测试了其在HCP数据集上的性能。发现同样的,所提出的元匹配方法准确率大幅超过经典的KRR方法。例如在K=20时,元匹配方法准确率超过KRR 100% (0.123 vs. 0.047). 而在K=100时,以COD为指标,元匹配方法准确率超过KRR 800%.

讨论与总结
考虑到所提出的元匹配方法是利用表征特性之间的相关性来辅助预测,其背后的预测机制有可能是非因果的。然后该研究的主要目标是提高预测准确率,并且即使是非因果预测,所得到的预测模型也有很多的应用场景。例如,抗抑郁药物至少要4周以上才会起效,而少于50%的病人会对第一次给药反应良好。因此,即使是非因果的预测,提高表征特性的预测能力在临床上仍具有巨大价值。
论文所提出的元匹配方法,是基于机器学习领域中的元学习,多任务学习以及迁移学习等。例如在DNN模型上先训练再微调可认为是迁移学习的一种形式。但是,值得注意的是,实验表明最大的准确率提升是来自于论文提出的核心算法—元匹配。当然,更先进的机器学习算法有希望在这个方向上带来更大的预测准确率的提升。
虽然最初的脑成像数据集来自于年轻健康的成年人,现在有越来越多的数据集侧重不同的人群,例如老年人、儿童、不同的疾病等。论文提出的方法在将来也可以用于其他人群数据集的表征特性预测,例如最近的ABCD数据集包含了精神健康症状。
字节跳动智能创作团队是字节跳动音视频创新技术和业务中台,覆盖了机器学习、计算机视觉、图形学、语音、拍摄编辑、特效、客户端、服务端工程等技术领域,在部门内部实现了前沿算法—工程系统—产品全链路的闭环,旨在以多种形式向公司内部各业务线以及外部合作客户提供业界前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。
智能创作基础研究团队旨在探索前沿机器学习以及计算机视觉、自然语言处理技术,解决人工智能领域里的挑战性问题。
Nature Neuroscience是神经生物学领域最顶级的刊物之一,该杂志发表的论文涉及神经科学的各个领域,包括分子、细胞、系统、行为、认知和计算研究。
*本文系量子位获授权刊载,观点仅为作者所有。
—?完?—
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~


量子位?QbitAI
?'?' ? 追踪AI技术和产品新动态
一键三连「分享」「点赞」和「在看」
科技前沿进展日日相见 ~
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 量子位
量子位
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675