
介绍 Pandas 实战中一些高端玩法

DataFrame数据集当中的分层索引问题。什么是多重/分层索引
DataFrame数据集多重索引的创建
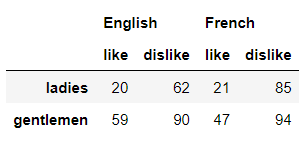
columns参数时传递两个或者更多的数组,代码如下df1?=?pd.DataFrame(np.random.randint(0,?100,?size=(2,?4)),
???????????????????index=?['ladies',?'gentlemen'],
???????????????????columns=[['English',?'English',?'French',?'French'],
????????????????????????????['like',?'dislike',?'like',?'dislike']])
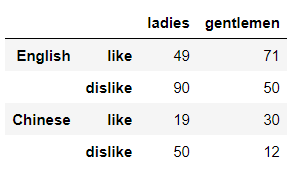
index参数的时候传递两个或者更多数组即可,代码如下df?=?pd.DataFrame(np.random.randint(0,?100,?size=(4,?2)),
???????????????????index=?[['English','',?'Chinese',''],
???????????????????????????['like','dislike','like','dislike']],
???????????????????columns=['ladies',?'gentlemen'])
pd.MultiIndex.from_arrayspd.MultiIndex.from_framepd.MultiIndex.from_tuplespd.MultiIndex.from_product
df2?=?pd.DataFrame(np.random.randint(0,?100,?size=(4,?2)),?
???????????????????columns=?['ladies',?'gentlemen'],
???????????????????index=pd.MultiIndex.from_product([['English','French'],
????????????????????????????????????????????????????['like','dislike']]))
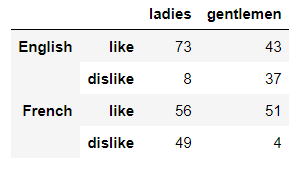
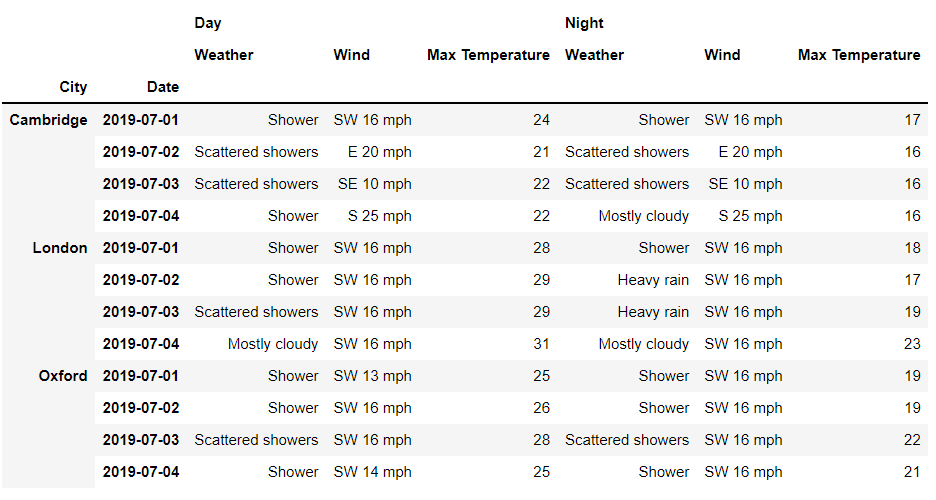
获取多重索引的值
import?pandas?as?pd
from?pandas?import?IndexSlice?as?idx?
df?=?pd.read_csv('dataset.csv',
????index_col=[0,1],
????header=[0,1]
)
df?=?df.sort_index()
df
df.columns.levels
FrozenList([['Day',?'Night'],?['Max?Temperature',?'Weather',?'Wind']])
df.columns.get_level_values(0)
Index(['Day',?'Day',?'Day',?'Night',?'Night',?'Night'],?dtype='object')
df.columns.get_level_values(1)
Index(['Weather',?'Wind',?'Max?Temperature',?'Weather',?'Wind',
???????'Max?Temperature'],
??????dtype='object')
数据的获取
loc()方法以及iloc()方法了,例如df.loc['London'?,?'Day']
##?或者是
df.loc[('London',?)?,?('Day',?)]
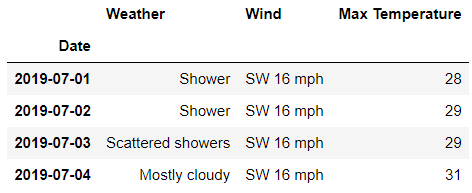
loc()方法来获取第一层级上的数据,要是我们想要获取所有“行”的数据,代码如下df.loc[:,?'Day']
##?或者是
df.loc[:,?('Day',)]

df.loc['London'?,?:]
##?或者是
df.loc[('London',?)?,?:]
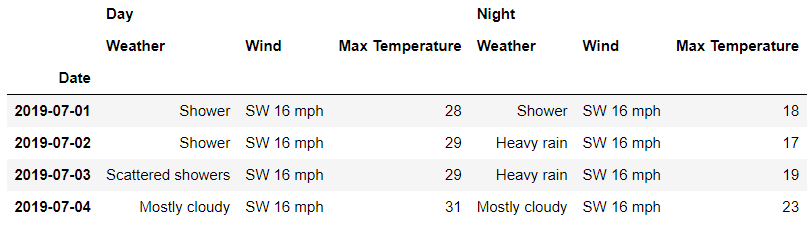
df.loc['London'?,?'2019-07-02']
##?或者是
df.loc[('London'?,?'2019-07-02')]

多重索引的数据获取
df.loc['Cambridge',?'Day'].loc['2019-07-03']

loc['Cambridge', 'Day']的时候返回的是DataFrame数据集,然后再通过调用loc()方法来提取数据,当然这里还有更加快捷的方法,代码如下df.loc[('Cambridge',?'2019-07-01'),?'Day']
df.loc[?
????('Cambridge'?,?['2019-07-01','2019-07-02']?)?,
????'Day'
]

df.loc[?
????'Cambridge'?,
????('Day',?['Weather',?'Wind'])
]
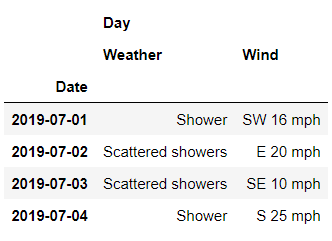
df.loc[
????('Cambridge',?'2019-07-01':?'2019-07-03'),
????'Day'
]

df.loc[
????('Cambridge','2019-07-01'):('London','2019-07-03'),
????'Day'
]
xs()方法的调用
xs()方法来指定多重索引中的层级,例如我们只想要2019年7月1日各大城市的数据,代码如下df.xs('2019-07-01',?level='Date')
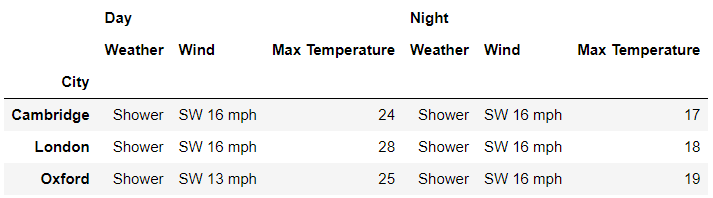
df.xs(('London',?'2019-07-04'),?level=['City','Date'])

axis参数来指定是获取“列”方向还是“行”方向上的数据,例如我们想要获取“Weather”这一列的数据,代码如下df.xs('Weather',?level=1,?axis=1)
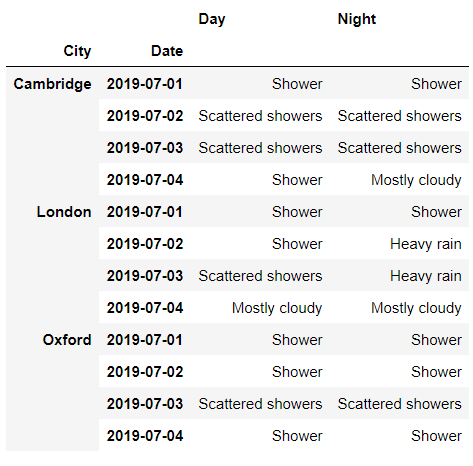
level参数代表的是层级,我们将其替换成0,看一下出来的结果df.xs('Day',?level=0,?axis=1)
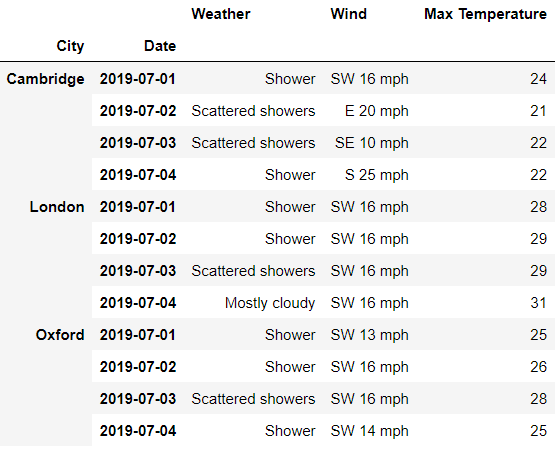
IndexSlice()方法的调用
Pandas内部也提供了IndexSlice()方法来方便我们更加快捷地提取出多重索引数据集中的数据,代码如下from?pandas?import?IndexSlice?as?idx
df.loc[?
????idx[:?,?'2019-07-04'],?
????'Day'
]
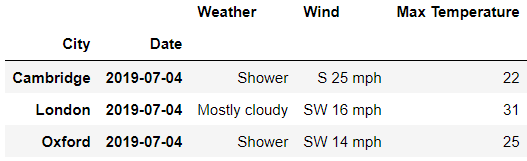
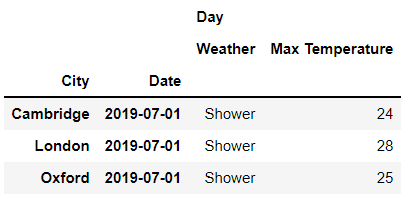
rows?=?idx[:?,?'2019-07-02']
cols?=?idx['Day'?,?['Max?Temperature','Weather']]
df.loc[rows,?cols]


分享
点收藏
点点赞
点在看




关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675